









texthero的初次使用
一、下载
最简单的就是直接pip下载
pip install texthero
但是有许多依赖库,可能下载时间较长
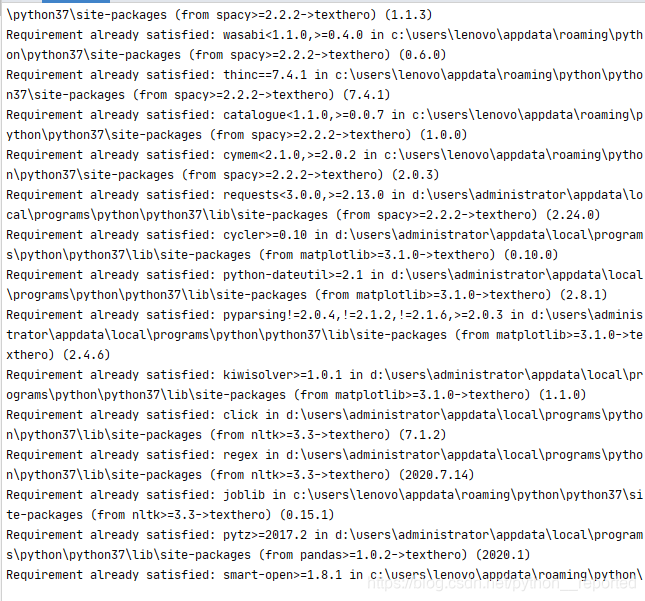
同时在初次使用时还会对一些数据进行下载,
注意:对于这些数据的下载是需要挂上vpn的,否者下载不下来
二、初次使用
基本就是照搬texthero的示例,只是我用中文测试了一下
中文测试内容来源:《对话|“我是讽刺那些假大师”,当武术表演遭遇网红行为艺术》澎湃新闻记者 蒲垚磊2020-07-27 15:39 来源:澎湃新闻

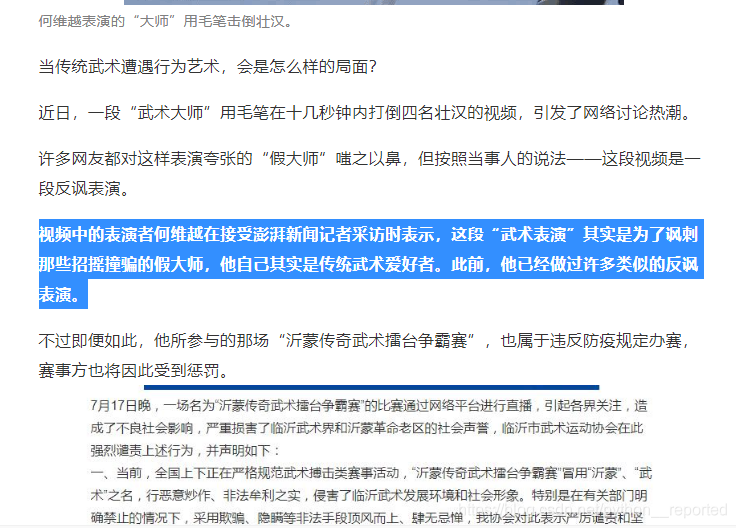
选中的内容就是测试的内容
"""简单的文本清理管道"""
#显示所有的行列
pd.set_option('display.max_columns', None)
# 显示所有行
pd.set_option('display.max_rows', None)
# 设置value的显示长度为100,默认为50
pd.set_option('max_colwidth', 100)
text = "视频中的表演者何维越在接受澎湃新闻记者采访时表示,这段“武术表演”其实是为了讽刺那些招摇撞骗的假大师,他自己其实是传统武术爱好者。此前,他已经做过许多类似的反讽表演。(12306/)!"
#格式化为series格式
s = pd.Series(text)
print(s)#This sèntencé (123 /) needs to [OK!] be cleaned!
#去掉了数字
s = hero.remove_digits(s)
print(s)#This sèntencé ( /) needs to [OK!] be cleaned!
#删除所有类型的括号及其内容
s = hero.remove_brackets(s)
print(s)
#删除变音符号即声标
s = hero.remove_diacritics(s)
print(s)
#删除标点符号。
s = hero.remove_punctuation(s)
print(s)
#删除多余的空格。
s = hero.remove_whitespace(s)
print(s)
#停用词,无意义的词
s = hero.remove_stopwords(s)
print(s)
#nlp提取名词
s = hero.named_entities(s)
print("nlp:",s)
s = hero.noun_chunks(s)
print(s)

其中声标的清除就是将中文转为拼音的过程,然而如果没有音标的清楚,后面的nlp就无法实现

词性标注说明(直接谷歌翻译的)
个人觉得不用音标清楚的方法更好,因为nlp的识别并不是非常好,例如将"视频“识别为人,这可能就是由于作nlp识别时将音标、音调去掉导致的,例如”视频“、”食品“去掉音标都是sipin,因而在拼音层面去识别并标注错误的概念非常高;可以对比一下jieba的结果

jieba识别下的词性标注相对还是比较准确的,”视频“就是名词而不是人名

















 794
794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









