






前言:随着chatGPT的备受欢迎,大模型异常火爆,各大厂商相继推出自己的大模型。
二级公司和用户需要根据自身的垂直领域微调这些具有语义理解能力的大模型,以满足特定领域的业务需求,如医疗,法律咨询等。
但是当微调这一类比较大的模型时,更新所有参数不太可行。以 GPT-3 175B 为例——部署微调模型的独的成本极其昂贵。
huggingface上的框架。 如 1 指令微调 huggingface有PEFT 2 强化学习的human feedback , huggingface有TRL框架
1 1 中 有6种方法, LORA, p-tuning-V1, p-tuning-V2等
2 TRL框架
详细使用方法待后续补充
一 LoRA:
1 低(秩)rank 自适应微调方法
2 背景及本质
大模型的参数更新耗费大量现存为此, 微软的研究者们于2021年通过论文《LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS》提出了低秩适应LoRA
- 它冻结了预训练的模型权重,并将可训练的秩分解矩阵注入到 Transformer 架构的每一层中,大大减少了下游任务的可训练参数的数量
We propose Low-Rank Adaptation, or LoRA, which freezes the pre-trained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, greatly reducing the number of trainable parameters for downstream tasks.
-
- 与使用 Adam 微调的 GPT-3 175B 相比,LoRA 可以将可训练参数数量减少 10,000 倍,GPU 内存需求减少 3 倍
Compared to GPT-3 175B fine-tuned with Adam, LoRA can reduce the number of trainable parameters by 10,000 times and the GPU memory requirement by 3 times.
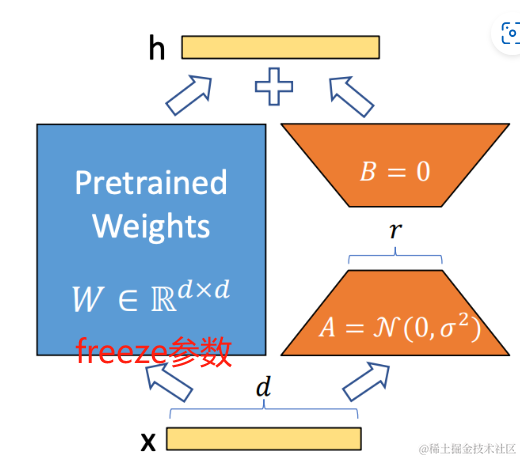
3 大致操作总览
1 正向推理 的所有参数 结果
2 反向梯度的所有结果
3 反向梯度更新的计算, sGD不带状态的会相对省内存,但是adam 就会记录过往若干梯度参数。
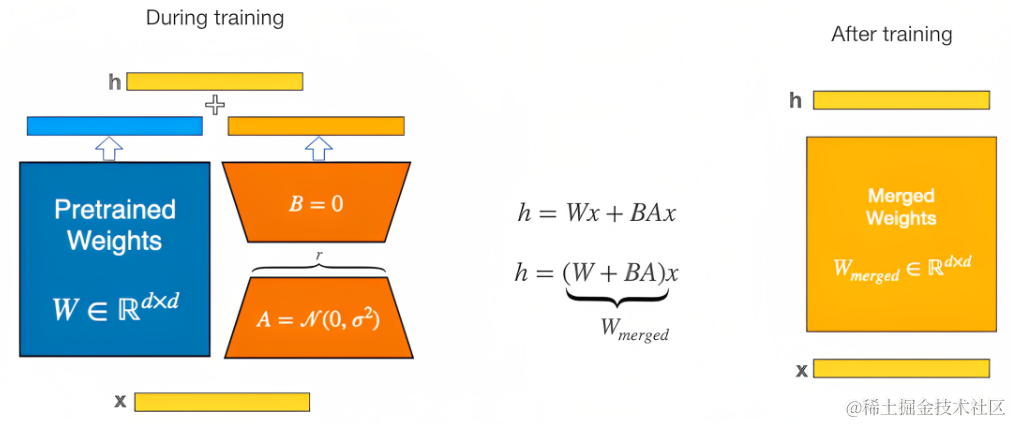
训练:
图 W0+Lora层结果
lora=w1 正态分布+w2 全0
推理:lora层需要merge会W0,即w1*w2+w0即可。
4 实际操作
4.1 微软DeepSpeed-Chat中对LoRA微调的实现
# TODO 待补充—>>>>>>
代码中体现
| 1 | F.linear(``input``, ``self``.weight, ``self``.bias) ``+ (``self``.lora_dropout(``input``)<br> @ ``self``.lora_right_weight @ ``self``.lora_left_weight) ``* self``.lora_scaling |
|---|
加号左侧为原结构支路,加号右侧为新增支路,self.lora_right_weight 和self.lora_left_weight 分别为两个新引入线性层的参数.
4.2 Huggingface上PEFT库对LoRA
更详细使用方法
# TODO 待补充—>>>>>>
5 另外应用
lora层可针对某一层参数,可插拔
对stable diffusion 也可用。
二 QLora微调方法
2.1 前言
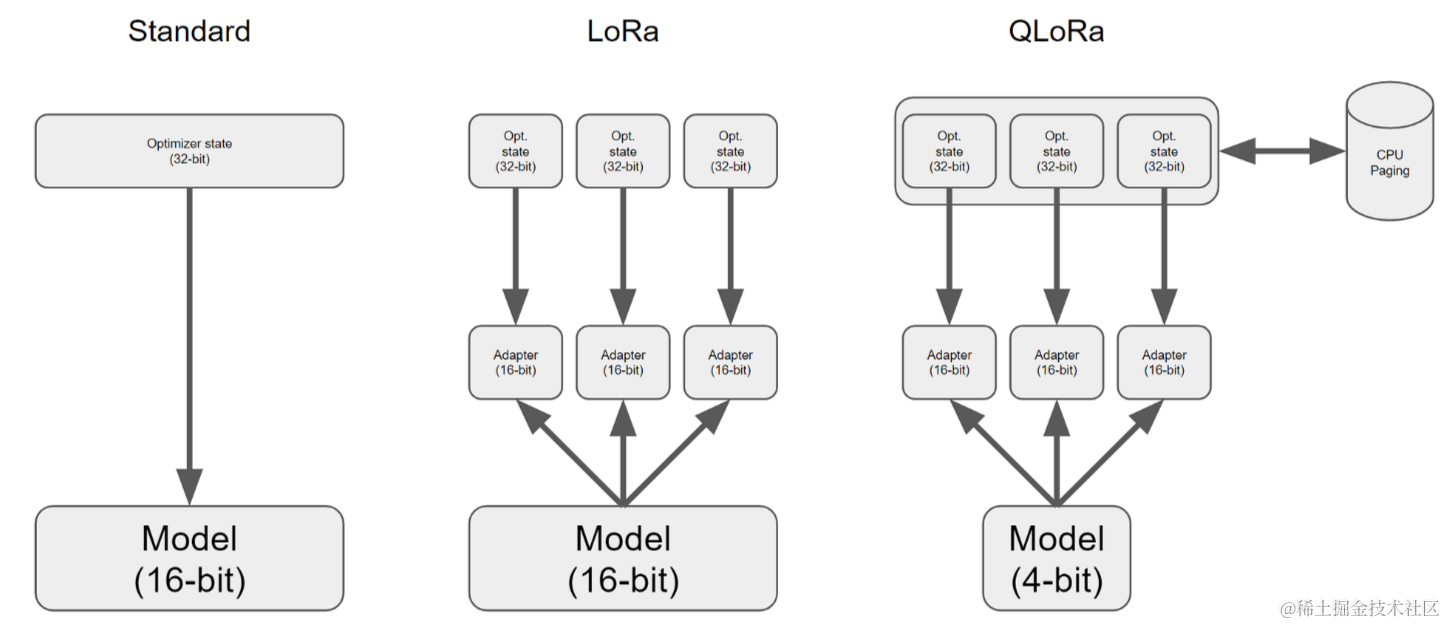
QLoRA于今23年5月份通过此篇论文《[QLORA: Efficient Finetuning of Quantized LLMs](https://arxiv.org/pdf/2305.14314 "QLORA: Efficient Finetuning of Quantized LLMs")》被提出,本质是对LoRA的改进,相比LoRA进一步降低显存消耗。
- 因为LoRa为LLM的每一层添加了少量的可训练参数(适配器),并冻结了所有原始参数。这样对于微调,只需要更新适配器权重,这可以显著减少内存占用
- 而QLoRa更进一步,引入了4位量化、双量化和利用nVidia统一内存进行分页。
所有这些对比Lora,进一步降低了显存消耗。
下图总结了不同的微调方法及其内存需求,其中的QLoRA通过将模型量化到4位精度并使用分页优化器管理内存峰值来改进LoRA.
2.2 模型量化
原理:将浮点数值转化为定点数值,同时尽可能减少计算精度损失的方法。
这样就减小了模型, 在计算时,最后再将定点数据反量化为浮点数据得到最终的结果。
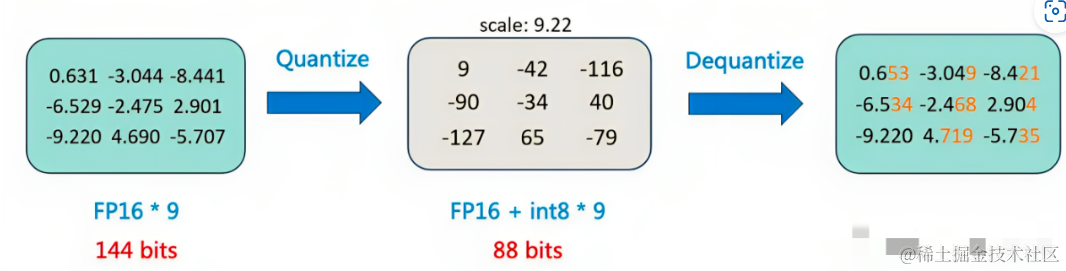
综合而言,我们可以对模型参数(weight)、激活值(activation)或者梯度(gradient)做量化。通常而言,模型的参数分布较为稳定,因此对参数 weight 做量化较为容易(比如,QLoRA便是对weight做量化)
至于模型的激活值往往存在异常值,直接对其做量化,会降低有效的量化格点数,导致精度损失严重,因此,激活值的量化需要更复杂的处理方法(如SmoothQuant)
更多内容详见: 《zhouyi量化白皮书》
三 P-tuning V1/V2
在学习P-tuning之前,需要先了解下prefix-tuning。
它指的是在微调模型的过程中只优化加入的一小段可学习的向量(virtual tokens)作为Prefix,而不需要优化整个模型的 参数(训练的时候只更新Prefix部分的参数,而PLM中的其他部分参数固定)。原理如图。
对于不同的任务和模型结构需要不同的prefix, 微调时只更新prefix。
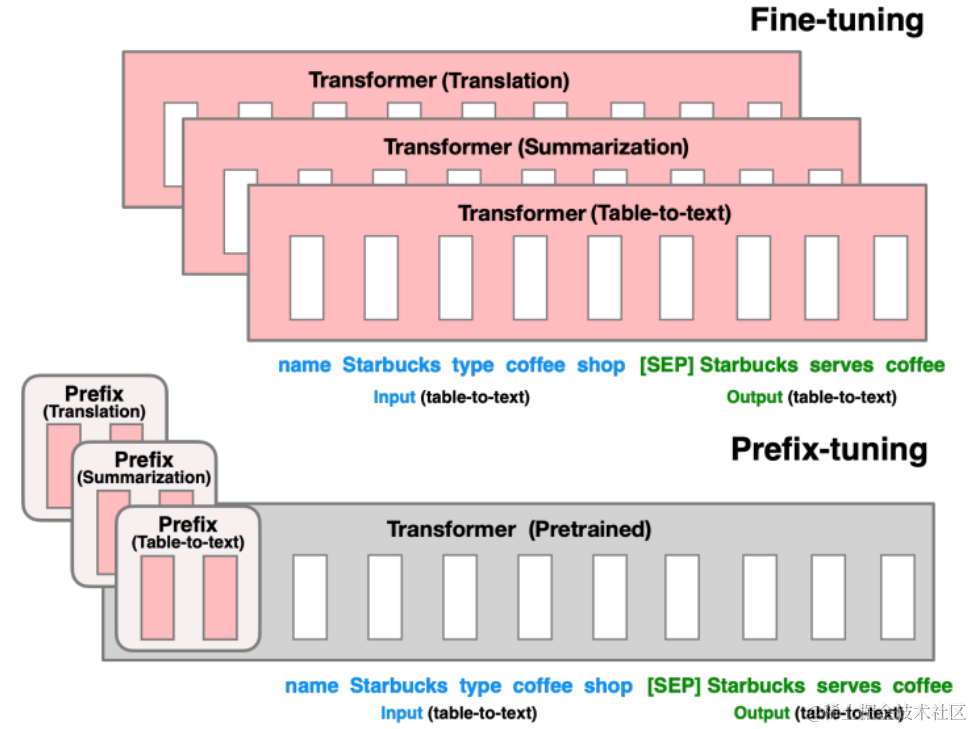
1)在autoregressive LM 前添加prefix:
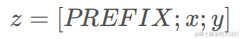
2)在encoder和decoder之前添加prefixs:
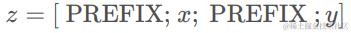
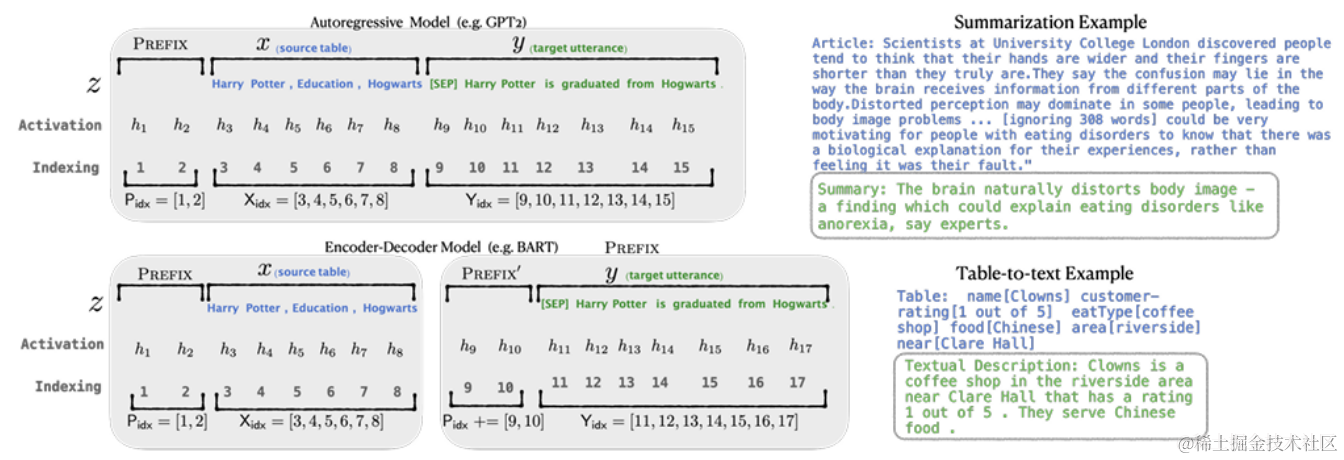
Encoder端增加前缀是为了引导输入部分的编码,Decoder 端增加前缀是为了引导后续token的生成。
3.0 prefix前置知识 加前缀tuning
hard prompt等同于discrete prompt;
离散prompt是一个实际的文本字符串(自然语言,人工可读),通常由中文或英文词汇组成;
soft prompt等同于continuous prompt。
连续prompt通常是在向量空间优化出来的提示,通过梯度搜索之类的方式进行优化。
所以离散的prompts中,提示语的变化对模型最终的性能特别敏感,加一个词、少一个词或者变动位置都会造成比较大的变化。成本比较高,并且效果不太好。
显然,Prefix Tuning属于Soft prompt。
个人理解:instruction 用于训练的一种技术,推理阶段,可以叫其prompt。hard-prompt在训练阶段之所以有效果,相当于约束了模型的某一部分分布,训练阶段也就主要更新这块的分布情况,所以微调或再次训练效果就会显现。
类似 luotuo的prompts。
| 12345 | def generate_prompt(instruction, ``input``):`` ``if len``(``input``) > ``0``:`` ``return f``"Below is an instruction that describes a task,<br> paired with an input that provides further context.<br> Write a response that appropriately completes the request.<br>\n\n### Instruction:\n{instruction}\n\n### Input:\n{input}\n\n### Response:\n"`` ``else``:`` ``return f``"Below is an instruction that describes a task.<br> Write a response that appropriately completes the request.<br>\n\n### Instruction:\n{instruction}\n\n### Response:\n" |
|---|
讨论一下Prompt Tuning : 提示词tuning
论文:The Power of Scale for Parameter-Efficient Prompt Tuning
论文地址:https://arxiv.org/pdf/2104.08691.pdf
该方法可以看做是Prefix Tuning的简化版本,它给每个任务都定义了自己的Prompt,拼接到数据上作为输出,但只在输入层加入prompt tokens。
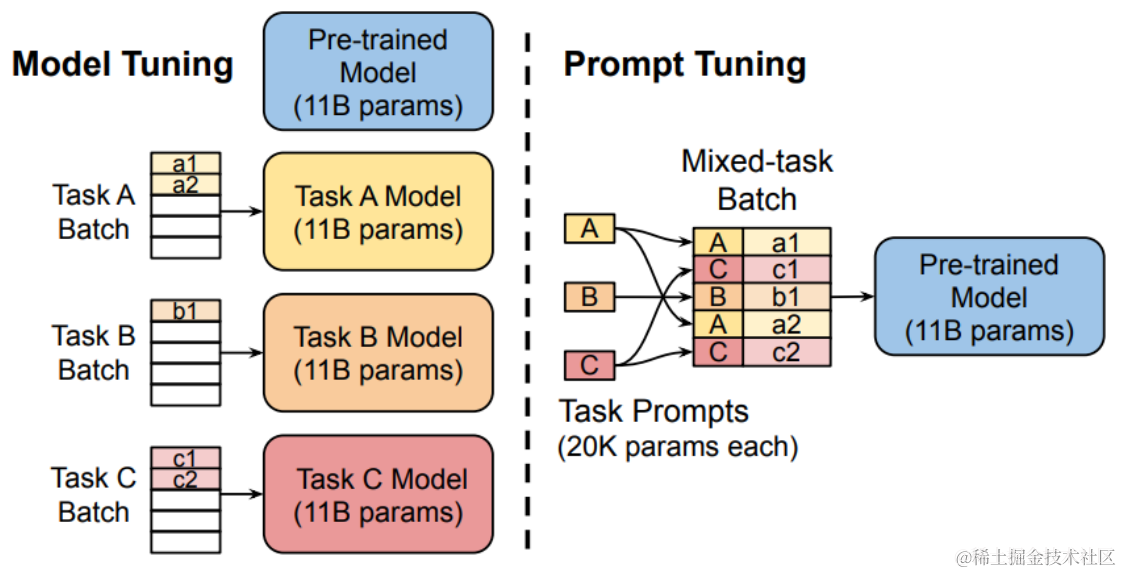
举一个例子:

3.1 P-Tuning V1:将自然语言的离散模版转化为可训练的隐式prompt (连续参数优化问题)
论文:GPT Understands, Too 论文地址:https://arxiv.org/abs/2103.10385
该方法的核心是使用可微的virtual token替换了原来的discrete tokens,
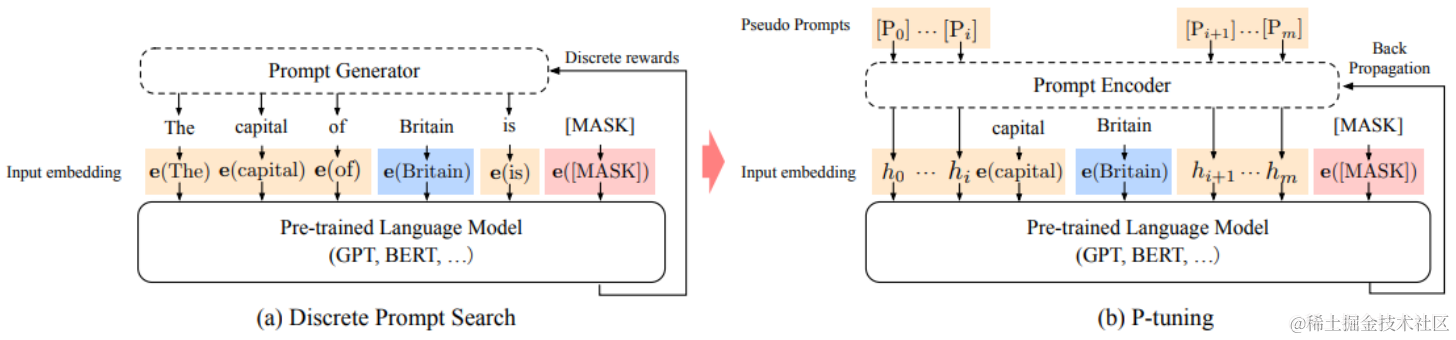
再使用prompt encoder(BiLSTM+MLP)对virtual token进行编码学习。
缺点
之前的Prompt Tuning和P-Tuning等方法存在两个主要的问题: 第一,缺乏模型参数规模和任务通用性。 缺乏规模通用性:Prompt Tuning论文中表明当模型规模超过100亿个参数时,提示优化可以与全量微调相媲美。但是对于那些较小的模型(从100M到1B),提示优化 和全量微调的表现有很大差异,这大大限制了提示优化的适用性。 缺乏任务普遍性:尽管Prompt Tuning和P-tuning在一些 NLU 基准测试中表现出优势,但提示调优对硬序列标记任务(即序列标注)的有效性尚未得到验证。 第二,缺少深度提示优化,在Prompt Tuning和P-tuning中,连续提示只被插入transformer第一层的输入embedding序列中,在接下来的transformer层中,插入连续提示的 位置的embedding是由之前的transformer层计算出来的,这可能导致两个可能的优化挑战。 由于序列长度的限制,可调参数的数量是有限的。 输入embedding对模型预测只有相对间接的影响。
3.2 P-Tuning V2:在输入前面的每层加入可微调的参数
P1 问题在P-tuning v2得到了改进。
论文:P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks 论文地址:https://arxiv.org/abs/2110.07602
P-Tuning v2主要是基于P-tuning和prefix-tuning技术,引入Deep Prompt Encoding和Multi-task Learning等策略进行优化的
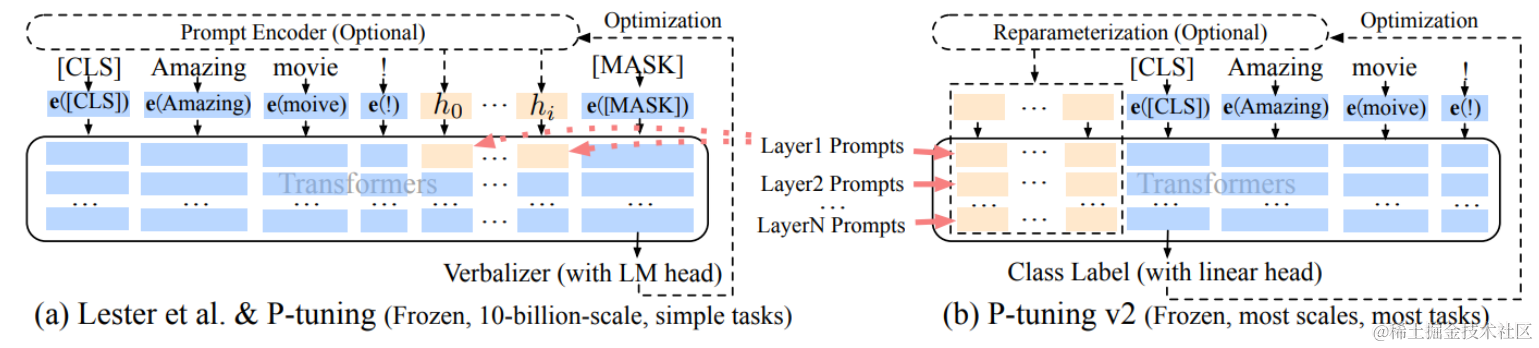
deep Prompt Encoding
P-Tuning v2在每一层都加入了Prompts tokens作为输入,而不是仅仅加在输入层,这带来两个方面的好处: 更多可学习的参数(从P-tuning和Prompt Tuning的0.01%增加到0.1%-3%),同时也足够参数高效。 加入到更深层结构中的Prompt能给模型预测带来更直接的影响。
Multi-task learning
基于多任务数据集的Prompt进行预训练,然后再适配到下游任务。对于pseudo token的continous prompt,随机初始化比较难以优化,因此采用multi-task方法同时训 练多个数据集,共享continuous prompts去进行多任务预训练,可以让prompt有比较好的初始化。
总结
P-Tuning v2是一种在不同规模和任务中都可与微调相媲美的提示方法。P-Tuning v2对从330M到10B的模型显示出一致的改进,并在序列标注等困难的序列任务上以很大的 幅度超过了Prompt Tuning和P-Tuning。
四 Freeze方法
Freeze是冻结的意思,Freeze方法指的是参数冻结,对原始模型的大部分参数进行冻结,仅训练少部分的参数,这样就可以大大减少显存的占用,从而完成对大模型的微 调。 这是一种比较简单微调方法,由于冻结的参数是大部分,微调的参数是少部分,因此在代码中只需要设置需要微调的层的参数即可,核心部分如下:
| 1234 | for name, param ``in model.named_parameters():`` ``# 说明准备调整列表中的层,不在列表中的都被冻结。`` ``if not any``(nd ``in name ``for nd ``in [``"layers.27"``, ``"layers.26"``, ``"layers.25"``, ``"layers.24"``, ``"layers.23"``]):``param.requires_grad ``= False |
|---|
缺点只微调接近下游任务的那几层参数,又难以达到较好的效果。
如何系统的去学习AI大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。
- 内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践 - L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
- 内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例 - L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词 - L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用 - L2.4 总结与展望
- L2.1 API接口
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
- 内容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节 - L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景 - L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例 - L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例 - L3.5 其他大模型介绍
- L3.1 Agent模型框架
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
- 内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的所有 ⚡️ 大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
全套 《LLM大模型入门+进阶学习资源包》↓↓↓ 获取~















 5706
5706

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









