



检索增强生成(RAG)是一种流行的技术,通过在生成答案之前从知识库中检索相关的外部知识来增强 LLM 的响应。RAG 提高了准确性,减少了幻觉,并使模型能够提供更符合上下文和更新的信息。
RAG 包括三个步骤:检索、增强和生成。
检索 - 在此步骤中,系统会在外部知识源(例如向量数据库)中搜索相关信息,以基于用户查询找到相关的信息。
增强 - 检索到的信息随后与原始用户查询结合,形成 LLM 的提示。
生成 - LLM 处理提示并生成响应,整合其预训练知识和检索到的信息。这使得响应更加准确且符合上下文。
让我们通过一个简单的例子来理解 RAG。
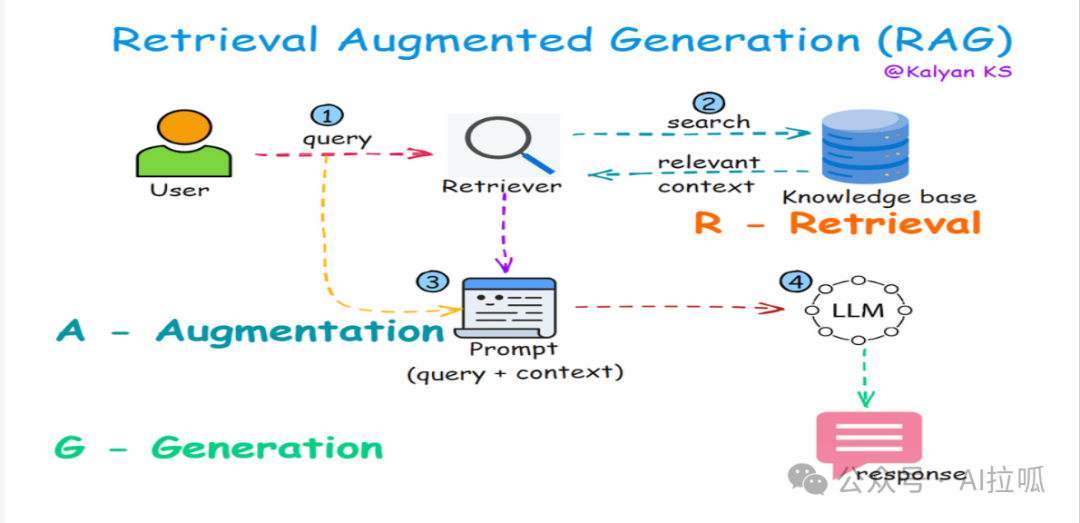
1 - 用户提出查询
示例:2025年ICC冠军奖杯的获胜者是谁?
2 - 检索器在知识源(例如维基百科或互联网)中搜索,并返回相关上下文。
示例检索上下文:"2025年ICC冠军奖杯于2月19日至3月9日在巴基斯坦和阿拉伯联合酋长国举行,最终印度成为胜利的冠军,赢得了该赛事历史上的第三个冠军。主要由巴基斯坦主办——这是自1996年以来他们的首次全球板球赛事——该赛事实施了混合模式,由于地缘政治考虑,印度的所有比赛都在迪拜进行。决赛在迪拜国际板球场上演了一场紧张的比赛,印度以四个门柱的优势击败新西兰,追平了252分的目标,并且还剩下一局。 "
3 - 查询、相关上下文和指令被组合成一个提示。
示例提示:
"仅根据上下文回答查询。如果在上下文中找不到查询的答案,请回复 - 我无法回答该查询。
查询:2025年ICC冠军奖杯的获胜者是谁?
*上下文:*2025年ICC冠军奖杯于2月19日至3月9日在巴基斯坦和阿拉伯联合酋长国举行,最终印度成为胜利的冠军,赢得了该赛事历史上的第三个冠军。主要由巴基斯坦主办——这是自1996年以来他们的首次全球板球赛事——该赛事实施了混合模式,由于地缘政治考虑,印度的所有比赛都在迪拜进行。决赛在迪拜国际板球场上演了一场紧张的比赛,印度以四个门柱的优势击败新西兰,追平了252分的目标,并且还剩下一局。"
4 - 提示被输入到大型语言模型 (LLM) 中,LLM 根据提供的上下文为用户查询生成答案。
示例输出:“印度在迪拜国际板球场举行的决赛中以四个门柱的优势击败新西兰,赢得了2025年ICC冠军奖杯。”
RAG 应用
AI 搜索引擎
AI 搜索引擎使用 RAG 通过将大型语言模型与实时数据检索相结合来增强搜索结果,提供准确且符合上下文的答案。它们擅长理解自然语言查询并从海量数据集中提取信息,使搜索更加直观和高效。
客户服务聊天机器人
客户服务聊天机器人利用 RAG 通过检索公司特定数据(如常见问题或产品手册)并生成类似人类的回复,提供个性化和准确的响应。这缩短了响应时间,提高了客户满意度,并处理了超出简单脚本答案的复杂查询。
法律文件分析
法律文件分析采用 RAG 筛选大量的法律文本、合同或判例法,检索相关的条款或先例,并用通俗易懂的语言总结它们。它通过加速研究、确保准确性并从密集的文档中识别关键见解来帮助律师。
科学研究辅助
科学研究辅助使用 RAG 通过检索和综合来自科学论文、数据集或实验的信息,为研究人员提供简洁的摘要或假设。它简化了文献综述、事实核查和跨大量研究存储库探索复杂主题的过程。
医疗决策支持
医疗决策支持将 RAG 集成到患者数据、医学文献或治疗指南中,协助医生做出基于证据的建议或诊断。它通过提供最新的、特定上下文的见解来增强决策过程,同时优先考虑患者隐私和准确性。
个性化教育
个性化教育应用 RAG 定制学习体验,检索相关的教育资源并生成适合学生学习进度和理解水平的解释。它通过适应个人需求并有效填补知识空白来支持导师或自学者。
技术文档搜索
技术文档搜索利用 RAG 导航复杂的手册、代码库或故障排除指南,检索精确的解决方案并清晰地解释它们。它通过快速解决技术查询并提供具有上下文感知的详细响应,为开发人员和工程师节省时间。
为什么需要 RAG?
大型语言模型(LLMs)通常在庞大的数据集上进行训练,这些数据集包括书籍、维基百科、网站的文本以及来自 GitHub 仓库的代码。这些训练数据收集到特定日期为止,这意味着 LLM 的知识有一个与训练数据最后更新时间相关的截止点。例如,如果 LLM 的训练数据只到2023年12月,那么它对之后发生的事情一无所知。
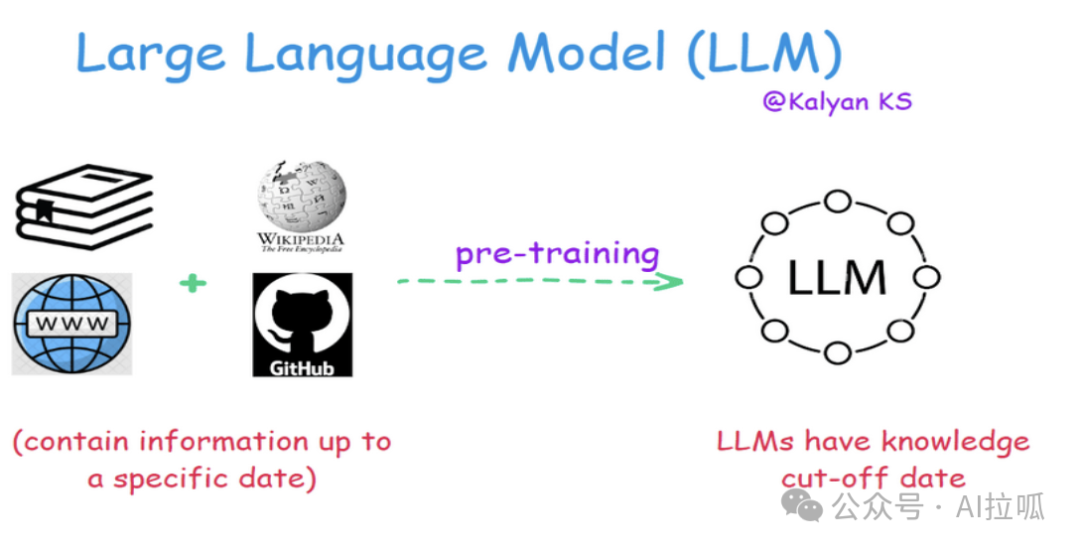
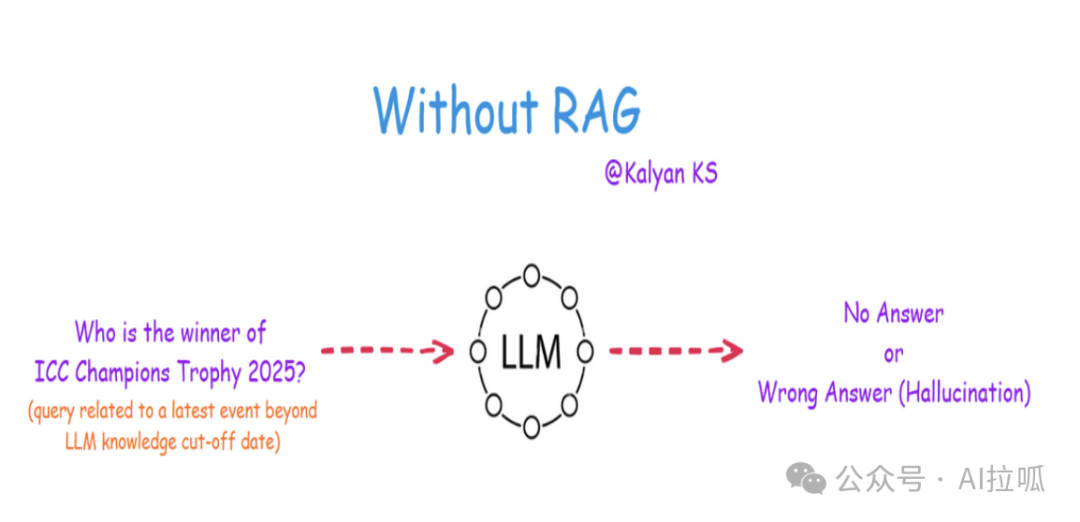
没有 RAG 时,当用户询问超出该截止日期的事件、发展或信息时,LLM 面临一个问题:它要么无法提供答案(使查询未解决),更糟糕的是,它可能会“幻觉”,生成听起来合理但不正确的响应。这是因为 LLM 被设计为根据其训练数据中的模式预测和生成文本,而不是天生能够区分它们知道什么和不知道什么。
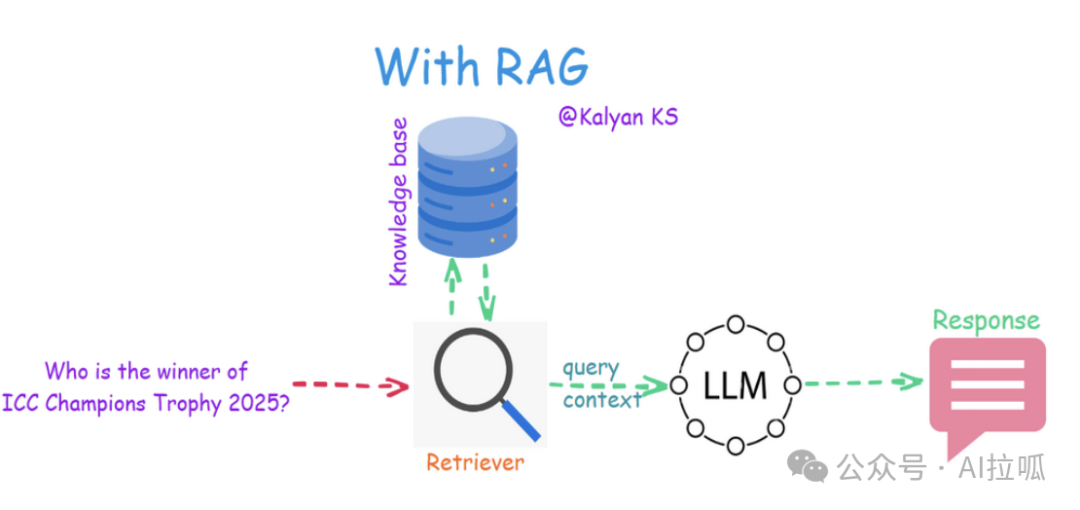
通过 RAG,这一限制通过集成检索机制得以解决。当提出查询时——尤其是与近期事件相关的查询——检索器会从外部来源(如网络数据、数据库或 X 等平台上的帖子)实时获取相关且最新的上下文。
然后将检索到的信息作为附加上下文提供给 LLM,使其能够基于最新可用数据生成准确且有依据的响应,而不仅仅是依赖其静态的预训练知识。本质上,RAG 弥补了 LLM 固定训练截止点与不断变化的世界之间的差距,确保更可靠和当前的答案。
总结如下:
LLMs 在大量书籍、维基百科、网站文本和 GitHub 代码库中进行训练。然而,它们的训练数据仅限于特定日期之前可用的信息。这意味着它们的知识在该日期被截断。
没有 RAG 的问题
-
LLMs 无法回答 关于其训练截止日期之后发生的事件或事实的查询。
-
它们可能会生成不正确或幻觉的响应,使得它们在提供最新信息时不可靠。
带有 RAG 的解决方案
- 检索
来自外部知识源(如数据库、API 或私人文档)的相关内容。
- 提供
检索到的相关内容作为上下文与查询一起提供给 LLM,使其能够生成事实准确的答案。
-
确保响应以检索到的信息为依据,减少幻觉。
因此,RAG 通过保持 LLM 更新来增强它们,而无需频繁重新训练。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 111
111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









