







1.定义:
分析(如何对样品或变量)进行量化分类的问题。
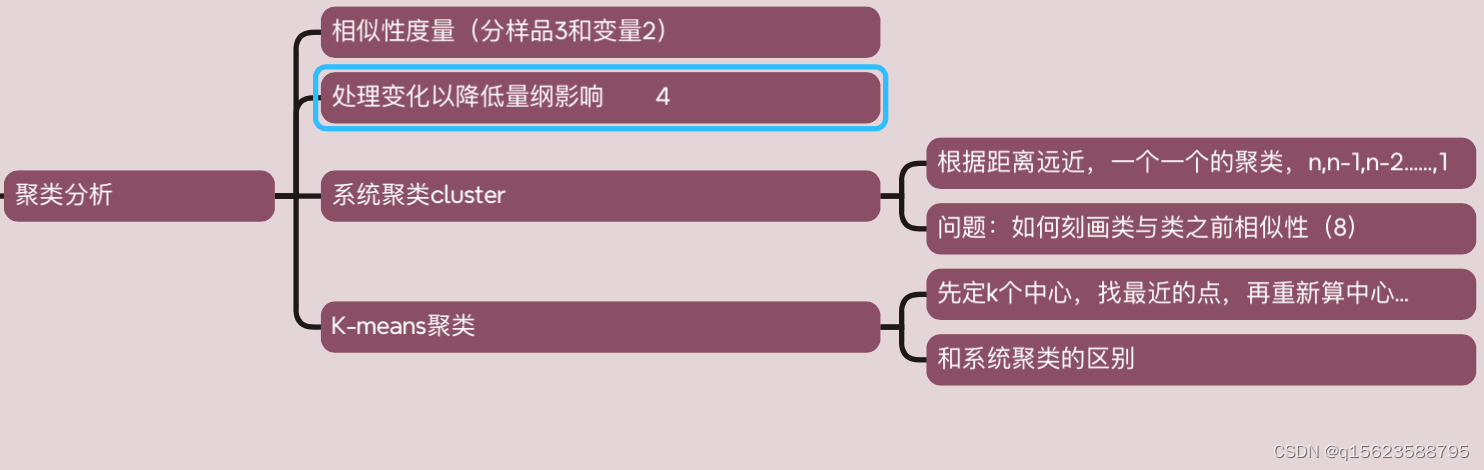
分为Q型聚类(样品分类),R型聚类(指标分类)。系统聚类和k--means聚类
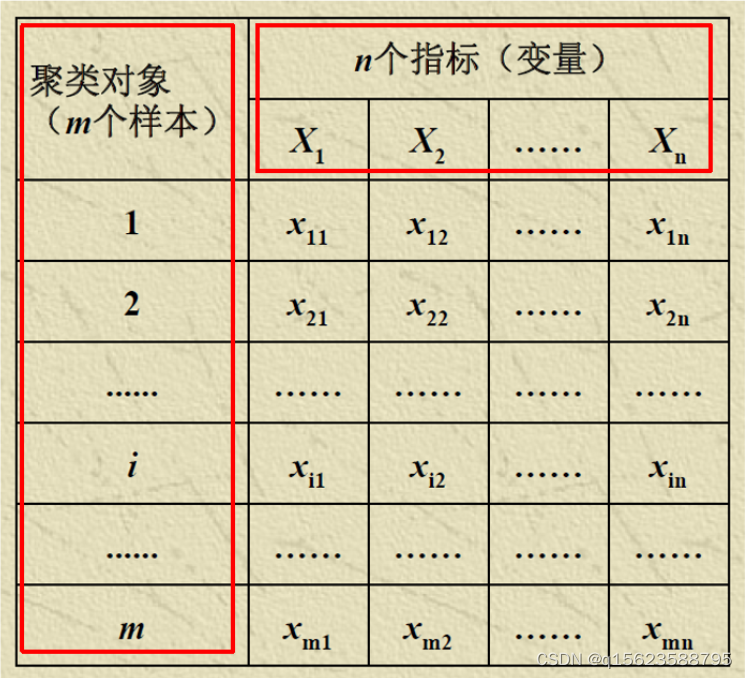
eg:医生医疗质量研究中,有N个医生参加医疗质量评比,每一个医生有K个医疗质量指标被记录。
聚类分析可以将N个医生按其医疗质量的优劣分成几类,或者把K个医疗质量指标所反映的问题侧重点不同分成几类。
前者是聚类分析中的样品聚类,后者是指标聚类。
准备:处理量纲
由于不同的变量具有不同的计量单位(或量纲),并且具有不同的数量级,为了使具有不同计量单位和数量级的数据能够放在一起进行比较分析,通常都要对数据进行变换处理,常见的处理方式有:

2.相似性度量


简单来说,样品相似性是指不同的数据记录(即样本)之间的相似程度,而变量相似性是指不同的数据特征(即变量)之间的相似程度。例如,在一个人口普查数据集中,每个样本可能包含多个变量,如年龄、性别、收入、教育程度等。那么,样品相似性可能会用于评估两个人口普查调查对象之间的相似程度,而变量相似性可能会用于评估年龄和收入、性别和教育程度等变量之间的相关性。
类与类之间如何刻画相似程度
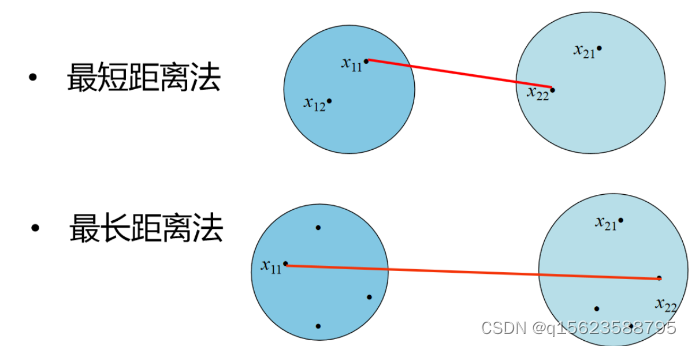
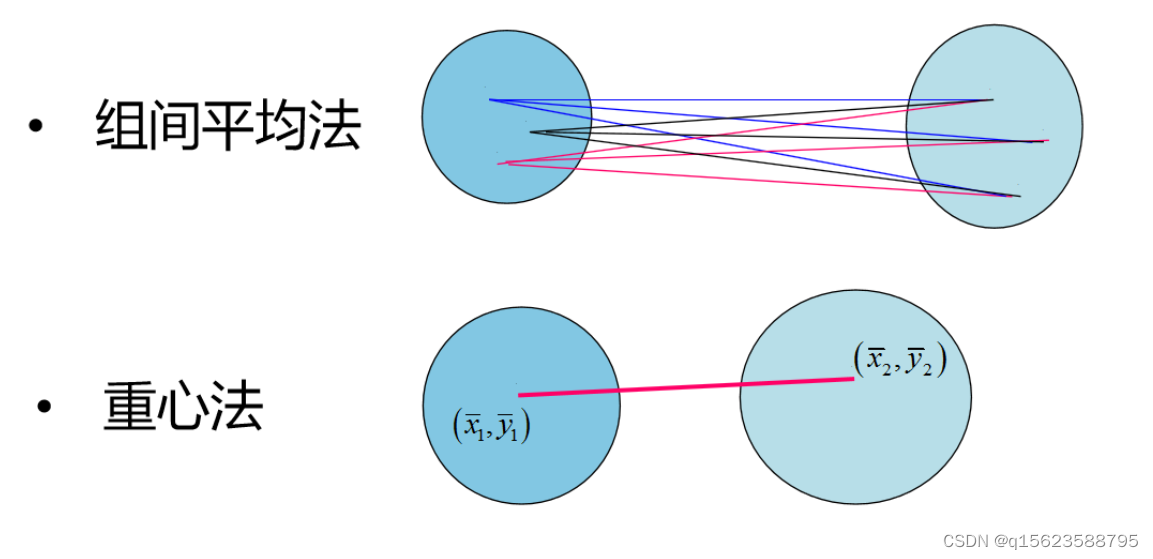
其它常见类间距离:
中间距离法、可变类平均、可变法、离差平方和
离差平方和法:该方法是Ward提出来的,又称为Ward法。该方法的基本思想来自于方差分析。如果分类正确,同类样品的离差平方和(各项与平均项之差的平方的总和)应当较小,类与类的离差平方和较大。
具体做法是先将n个样品各自成一类,然后每次缩小一类,每缩小一类,离差平方和就要增大,选择使其增加最小的两类合并,直到所有的样品归为一类为止。
3、系统聚类分析法
系统聚类的基本思想
1)将每个样品(或变量)独自聚成一类,共有 n类;
2)根据所确定的样品(或变量)“距离”公式,把距离较近的两个样品(或变量)聚合为一类,其它的样品(或变量)仍各自聚为一类,共聚成 n-1类;
3)将“距离”最近的两个类进一步聚成一类,共聚成n-2类;
4)以上步骤一直进行下去,最后将所有的样品(或变量)聚成一类.
4、K-means聚类分析法
主要步骤:
将所有的样品分成k个初始类;
通过欧式距离将某个样品划入离中心最近的类中并对获得样品与失去样品的类重新计算中心坐标;
重复第二步,直到所有的样品都不能再分配为止
思考:系统聚类法与k-means聚类法的不同点?
-
分层结构:
- 系统聚类法:它创建了一个树状结构,称为聚类树或 dendrogram,从每个样本开始,逐步合并相似的簇,直到所有样本在一个大的簇中。这个过程可以是自上而下(上聚类,Agglomerative)或自下而上(下聚类,Divisive)。
- k-means聚类法:它假设数据集被划分为k个独立且等大小的簇,每个簇中心(质心)由该簇内的所有点的均值计算得出。每次迭代中,样本被分配到最近的质心所在的簇,然后更新所有簇的质心。
-
初始条件:
- 系统聚类法:不需要预先设定簇的数量k,而是自动确定聚类结构,这可能需要对聚类树进行剪枝来确定最终的k值。
- k-means聚类法:需要预先设定k值,这是其一个缺点,因为它可能对结果敏感,如果选择的k值不合适,可能得到较差的聚类效果。
-
收敛性:
- 系统聚类法:由于其分层结构,不保证一定能收敛到全局最优解,特别是上聚类方法,可能会陷入局部最优。
- k-means聚类法:如果初始簇中心选择得当,k-means通常能收敛到局部最优解,但并非全局最优。
-
计算复杂性:
- 系统聚类法:计算成本可能随着数据集大小增加而急剧上升,特别是当使用自下而上的方法时。
- k-means聚类法:计算成本相对较低,因为每次迭代只需要计算每个样本到簇中心的距离和重新分配。
-
解释性:
- 系统聚类法:由于其分层结构,可以直观地理解数据之间的关系,有助于发现层次结构。
- k-means聚类法:结果通常更容易量化,但难以直观地表示簇之间的关系。
总之,系统聚类法更注重数据的全局结构,而k-means聚类法更适用于处理大规模数据并快速得到结果,但可能需要对k值有良好的选择。
5.例题
例一:产品分类 从21个工厂中抽出同类产品,每个产品测两个指标,欲将各厂的质量情况进行分类。
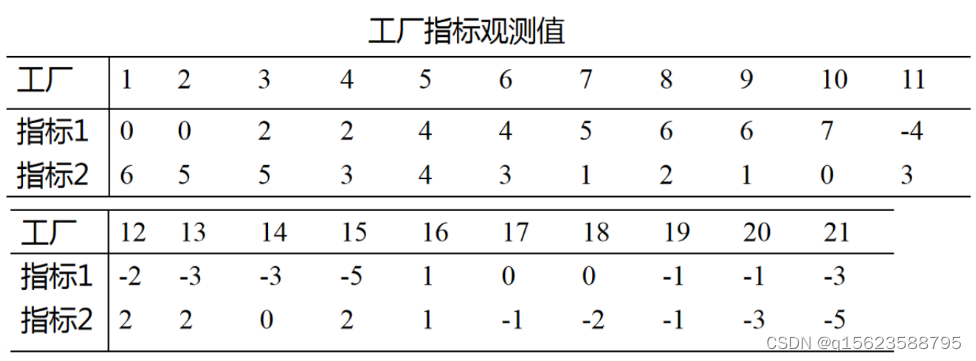
data ex;input x1 x2 factory$@@;
cards;
0 6 f1 0 5 f2 2 5 f3 2 3 f4 4 4 f5 4 3 f6 5 1 f7 6 2 f8 6 1 f9 7 0 f10 -4 3 f11 -2 2 f12 -3 2 f13
-3 0 f14 -5 2 f15 1 1 f16 0 -1 f17 0 -2 f18 -1 -1 f19 -1 -3 f20 -3 -5 f21
;
proc cluster /*系统聚类*/
data=ex method=ward ccc pseudo outtree=tree;
id factory; /*工厂为样本*/
run;
proc tree data=tree horizontal; /*聚类树型输出过程*/
id factory;
run;1.cluster过程,用来进行系统聚类
2.method=ward或method=war,表示类间距离使用离差平方和法
3.ccc选项,计算半偏R平方、R平方、ccc统计量
4.pseudo,输出伪F、伪t平方统计量
5.outtree=tree,将树形分类结果输出到数据集tree
6.id factory ,用factory变量的值作为每一个样品的id
7.tree过程,输出CLUSTER过程产生的树形分类结果
8.method=算法--包括 ward(离差平方和法 )average(类平均法),centroid(重心法)complete(最长距离法),single(最短距离法)median(中间距离法),density(密度法)flexible(可变类平均法),twostage(两阶段密度法),eml(最大似然法),mcquitty(相似分析法)
1.当把数据从G+1类合并为G类时,半偏R2统计量说明了本次合并信息的损失程度,统计量大表明损失程度大。
2.R2统计量反映类内离差平方和的大小,统计量大表明类内离差平方和小。
3.ccc统计量的值大说明聚类的效果好,
Pseudo说明要计算伪F和伪t2统计量。
4.一般认为,伪F统计量出现峰值时的所对应的分类是较佳的分类选择。
5.当把数据从G+1类合并为G类时,伪t2统计量的值大,说明不应该合并这两类。
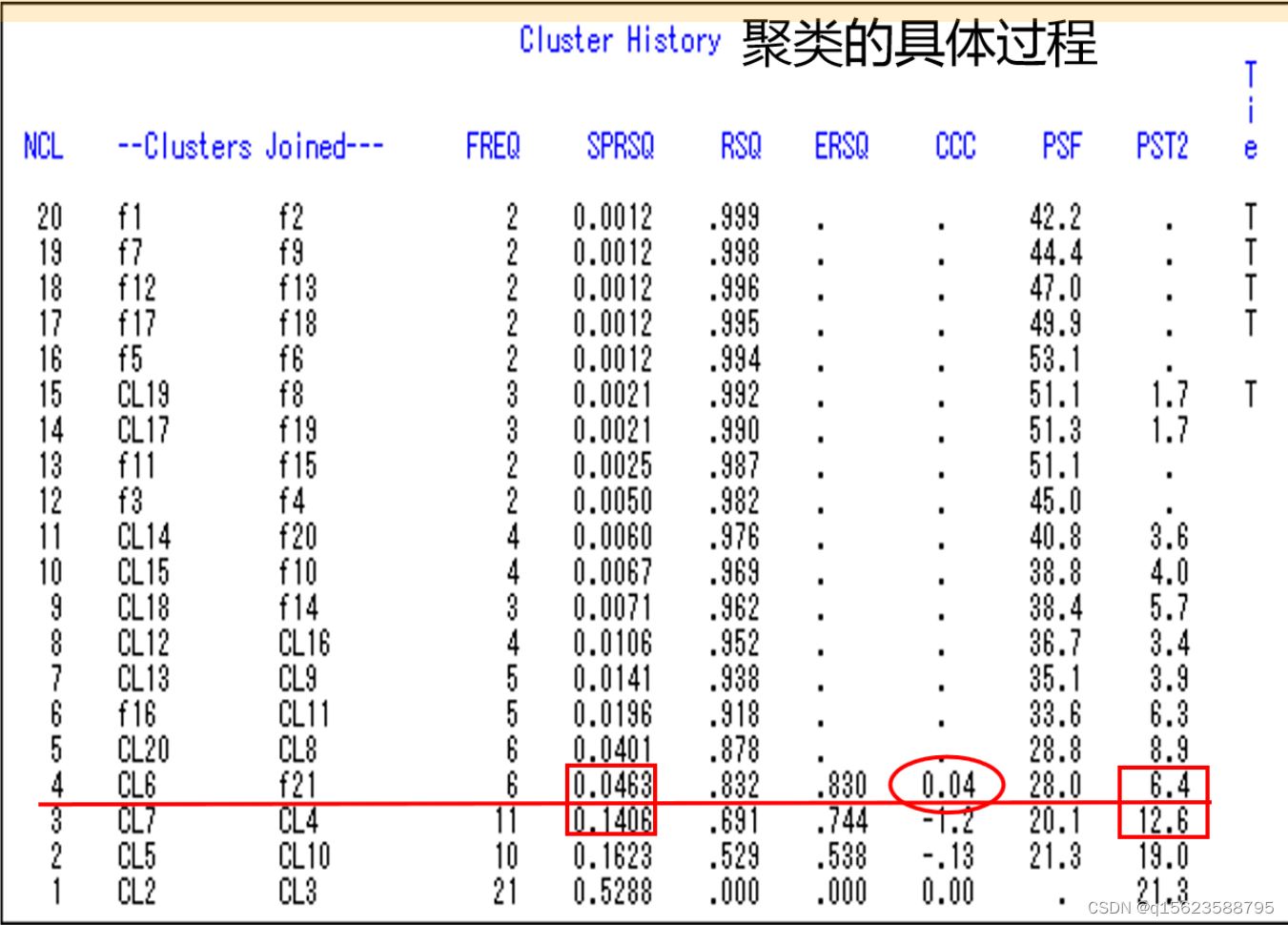
1. NCL表示当前系统存在类的总个数;
2.Clusters joined表示当前加入的编号,例如NCL等于20时,是类1,2聚为一类;
3. FREQ表示新类的元素个数;
4.SPRSO表示半偏R2统计量;
5.RSO表示R2统计量,ERSQ表示R2统计量的近似期望值;
6.PSF为伪F统计量,PST2为伪t2统计量;
7.Tie表示“节”,是指当前类间最小距离不止一个的时候,此时可以任意选择一对最短距离进行聚类,再计算其他类与新类的距离。
从CCC统计量的结果可以看出,最大值对应的类数为4。从四类合并为三类时,伪t2统计量显著的增加,伪F统计量下降显著,综合各方面的结果,因此分4类最为合适。
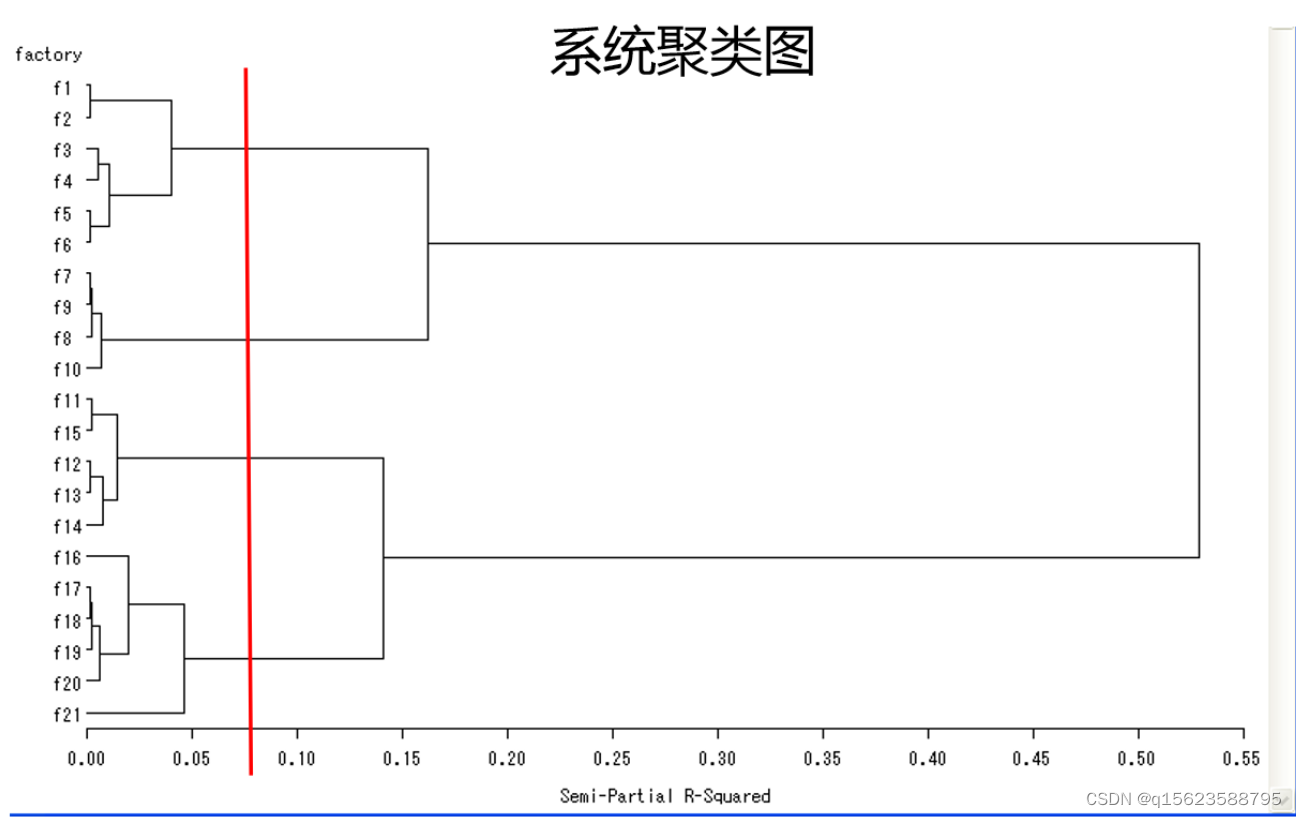
注:由于只能在二维的情况下我们才便于画散点图观察,所以对于高维的情况,我们可以使用主成分分析降维处理,然后画出第一主成分与第二主成分的散点图,来观察分类是否合理。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









