







Mask RCNN
Mask RCNN: 简单、灵活和通用的对象实例分割框架。可以有效地检测图像中的对象,同时为每个实例生成高质量的分割掩码。通过添加分支来预测对象掩码与现有分支并行以进行边界框识别来扩展 Faster R-CNN。
1. 前人研究
ROI pooling: 在feature map中预设一个大小,即pooled_w和pooled_h。将proposal层得到的每一个Proposal特征进行尺度统一。方便后续处理实现固定大小的输出。具体步骤为:
- 首先将proposal的(x1,y1,x2,y2)映射回到(M/16.N/16)大小
- 将每一个proposal对应的feature map中的区域划分为pooled_w*pooled_h网格
- 对网格每一部分做max-pooling
- 使得最终输出结果都是固定的大小,使得输出固定长度的ROI
DeepMask: 根据RCNN的启发,很多方法是基于候选区域分割的。先得到候选区,然后由Fast RCNN进行分类。这类方法分割先于分类。
多阶段级联网络:从预测得到的bbox和分类结果来进行分割。Mask RCNN不同于以上两类方法,其属于并行架构
FCIS:全卷积实例分割网络,全卷积地预测一组位置敏感的输出通道。这些通道同时处理对象类、框和掩码,使系统快速。缺点是其会再重叠物体上出现错误,并且带有虚假边缘。
FCN:逐像素分类,并标出不同实例。利用逐像素的softmax以及多项式交叉熵损失函数
Faster RCNN:两阶段目标检测网络,首先是RPN网络生成候选框,第二阶段则是利用ROI pool提取特征进行分类和预测框回归。
2. 网络结构
网络组成结构:CNN backbone(ResNet + FPN) + RPN + Head(分类、回归、mask)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qSaO2mkC-1675580908433)(C:\Users\1\AppData\Roaming\Typora\typora-user-images\image-20230205133123703.png)]
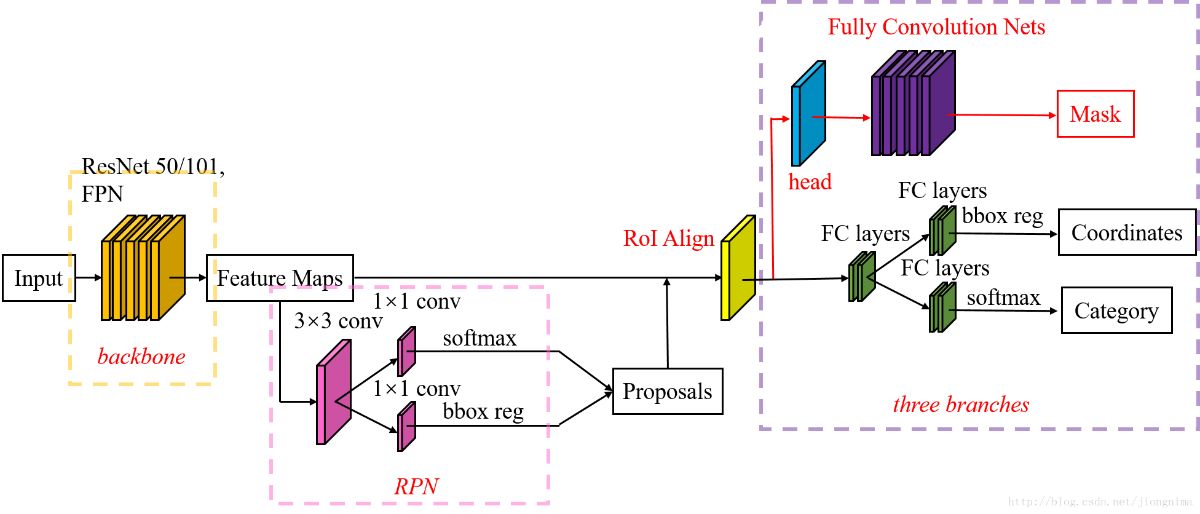
图片来源引用:https://zhuanlan.zhihu.com/p/432100214
Faster RCNN 不是为网络输入和输出之间的像素到像素对齐而设计的。提出了ROI Align层,它保留了精确的位置信息、修复了错位、并且是无量化的。
- faster rcnn中的ROIpooling层用于进行ROI的像素对齐,将筛选后的proposal在原feature-map上进行非裁剪或者变形意义上的映射和对齐。保持输出的一致大小。
Mask rcnn独立预测每个类的二进制掩码,并且基于ROI分类分支来进行类别预测。FCNs则进行逐像素的预测,结合了分类和分割。直观而自然地,添加了第三分支用于输出对象掩码,但是掩码输出需要更细致的空间信息。所以需要ROI align进行像素对齐。
Without bells and whistles: 不带任何技巧下的训练
其他细节:
- Proposal中正负样本选取原则:如果 RoI 与真实框的 IoU 至少为 0.5,则认为 RoI 为正,否则为负。掩码损失 L m a s k L_{mask} Lmask仅在正 RoI 上定义。
- Softmax耦合了掩码和类预测的任务导致了严重的精度下降。而现有分支下为每一个类生成掩码,Sigmoid就足以预测一个二进制掩码,避免了类之间的竞争。
- Faster RCNN+ROI align比Mask RCNN的目标检测框精度要低,作者认为是多任务带来的Mask RCNN精度提升
3. idea模块
损失函数定义:掩码分支的输出对应的是k* m * m的大小。其中k代表k类
L
=
L
c
l
s
+
L
b
o
x
+
L
m
a
s
k
L = L_{cls}+L_{box}+L_{mask}
L=Lcls+Lbox+Lmask
其中的
L
m
a
s
k
L_{mask}
Lmask与类别高度相关联的。比如是某一个ROI对应一个类别k,则
L
m
a
s
k
L_{mask}
Lmask只定义计算在第k个mask的结果,其他的ROI是不算的。
解耦结构: L m a s k L_{mask} Lmask 的定义允许网络为每个类生成掩码,而不会在类之间竞争。只利用逐像素SIgmoid以及二值分类损失。mask分支对空间进行编码,提供了像素到像素的空间对应关系。允许掩码分支中的每一层保持显式的m × m对象空间布局,而不将其折叠成缺乏空间维度的向量表示。与以往采用fc层进行掩码预测的方法不同,FCN需要更少的参数,实验表明效果更好。
ROI align: 一个标准操作用于对每个ROI提取特定大小的特征图,可以理解为一个特征映射的过程。
传统的ROI 特征映射:引起特征错位
- 首先将浮点数RoI量化为特征映射的离散粒度
- 将这个量化的RoI细分为自己量化的空间bin
- 聚合每个bin覆盖的特征值(通常通过最大池化)
ROI align: 消除了RoIPool的苛刻量化,正确地将提取的特征与输入对齐。使用双线性插值计算每个RoI bin中四个规则采样位置输入特征的精确值,并聚合结果(使用最大值或平均值)

整个过程可以解释为
- 首先对得到的ROI坐标大小进行映射,但此时并不取整数。比如(550/16,550/16)= (34.375,34.375)
- 在映射到的原始特征图中,如果分为7*7份,即池化后特征图统一大小为(7,7),则有
(34.375,34.375)/7 = (4.91,4.91)。即每个bin小块大小为(4.91,4.91)
- 对小块进行采样。如采样四个点,则将bin小块分四份,并取重心点的像素,中心点的像素采用双线性插值计算得到。这样就得到了所有的49个bin的像素值,组成新的特征图。
4. 多任务
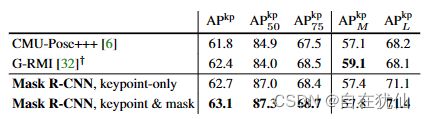
关键点检测:采用 ResNet-FPN 变体,关键点的检测头采用8个3*3的conv组成。并且采用了deconv层和2倍双线性插值,输出特征图精度为56 * 56 。
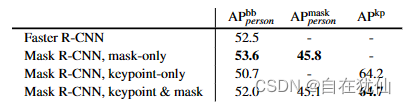
将掩码分支添加到仅框(即Faster R-CNN)或仅关键点版本可以持续改进这些单体任务的AP。添加关键点分支会略微降低框/掩码 AP,关键点检测受益于多任务训练分支,但关键点分支任务并没有反过来帮助其他任务提升AP。















 5736
5736











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









