







因为这章内容比较多,分开来叙述,前面先讲理论后面是讲代码。最重要的是代码部分,结合代码去理解思想。
SGD优化器
思想:
根据梯度,控制调整权重的幅度

公式:
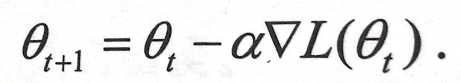
权重(新) = 权重(旧) - 学习率 × 梯度
Adam优化器
思想:
在我看来,Adam优化器重点是能动态调整学习率,防止学习率较大时反复震荡,比如说当梯度一直为正的时候,权重一直减小,这时直到梯度为负的时候,权重不应该一下子增长太多,而是应该缓慢增长。

这个公式可以在Diy框架代码中找到对应的代码并进行了解释。
优势:
- 实现简单,计算高效,对内存需求少
- 超参数具有很好的解释性,且通常无需调整或仅需很少的微调
- 更新的步长能够被限制在大致的范围内(初始学习率)
- 能够表现出自动调整学习率
- 很适合应用于大规模的数据及参数的场景
- 适用于不稳定目标函数
- 适用于梯度稀疏或梯度存在很大噪声的问题
BP反向传播
传播过程:
1.根据输入x和模型当前权重,计算预测值y’
2.根据y’和y使用loss函数计算loss
3.根据loss计算模型权重的梯度
4.使用梯度和学习率,根据优化器调整模型权重
Pytorch框架下实现代码:
import torch
import torch.nn as nn
import numpy as np
import copy
"""
基于pytorch的网络编写
实现梯度计算和反向传播
加入激活函数
"""
class TorchModel(nn.Module):
def __init__(self, hidden_size):
super(TorchModel, self).__init__()
self.layer = nn.Linear(hidden_size, hidden_size, bias=False) #线性层,输入输出维度都是hidden_size
self.activation = torch.sigmoid #套一个激活函数(不套也可以)
self.loss = nn.functional.mse_loss #loss采用均方差损失
#当输入真实标签,返回loss值;无真实标签,返回预测值
def forward(self, x, y=None):
y_pred = self.layer(x) #将输入放入线性层中,获得预测值
y_pred = self.activation(y_pred) #将预测值激活
if y is not None:
return self.loss(y_pred, y)
else:
return y_pred
x = np.array([1, 2, 3, 4]) #输入
y = np.array([3, 2, 4, 5]) #预期输出
#torch实验
torch_model = TorchModel(len(x)) #给torchmodel函数传入x的维度作为hidden_size
torch_model_w = torch_model.state_dict()["layer.weight"]
print(torch_model_w, "初始化权重")
numpy_model_w = copy.deepcopy(torch_model_w.numpy()) #拷贝一下,用于diy中对初始权重计算
torch_x = torch.FloatTensor([x])
torch_y = torch.FloatTensor([y])
#torch的前向计算过程,得到loss
torch_loss = torch_model.forward(torch_x, torch_y)
print("torch模型计算loss:", torch_loss)
#设定优化器
learning_rate = 0.1
optimizer = torch.optim.SGD(torch_model.parameters(), lr=learning_rate) #SGD优化器
#torch_model.parameters传递模型中所有的参数,也可以只有选择想传递的参数
# optimizer = torch.optim.Adam(torch_model.parameters()) #Adam优化器
optimizer.zero_grad() #先把优化器归零
#pytorch的反向传播操作
torch_loss.backward() #完成梯度计算
print(torch_model.layer.weight.grad, "torch 计算梯度") #查看某层权重的梯度
#torch梯度更新
optimizer.step()
#查看更新后权重
update_torch_model_w = torch_model.state_dict()["layer.weight"]
print(update_torch_model_w, "torch更新后权重")
接下来是DIY手动框架实现
"""
手动实现梯度计算和反向传播
加入激活函数
"""
#自定义模型,接受一个参数矩阵作为入参
class DiyModel:
def __init__(self, weight):
self.weight = weight
def forward(self, x, y=None):
y_pred = np.dot(self.weight, x)
y_pred = self.diy_sigmoid(y_pred)
if y is not None:
return self.diy_mse_loss(y_pred, y)
else:
return y_pred
#sigmoid
def diy_sigmoid(self, x):
return 1 / (1 + np.exp(-x))
#手动实现mse,均方差loss
def diy_mse_loss(self, y_pred, y_true):
return np.sum(np.square(y_pred - y_true)) / len(y_pred)
#手动实现梯度计算
def calculate_grad(self, y_pred, y_true, x):
#前向过程与反向过程对比看
# wx = np.dot(self.weight, x)
# sigmoid_wx = self.diy_sigmoid(wx)
# loss = self.diy_mse_loss(sigmoid_wx, y_true)
#反向过程(通过前向的loss来获得对权重w的导数)
# 均方差函数 (y_pred - y_true) ^ 2 / n 的导数 = 2 * (y_pred - y_true) / n
grad_loss_sigmoid_wx = 2/len(x) * (y_pred - y_true)
# sigmoid函数 y = 1/(1+e^(-x)) 的导数 = y * (1 - y)
grad_sigmoid_wx_wx = y_pred * (1 - y_pred)
# wx对w求导 = x
grad_wx_w = x
#导数链式相乘
grad = grad_loss_sigmoid_wx * grad_sigmoid_wx_wx
grad = np.dot(grad.reshape(len(x),1), grad_wx_w.reshape(1,len(x))) #转化为矩阵形式相乘
return grad
#sgd梯度更新
def diy_sgd(grad, weight, learning_rate):
return weight - grad * learning_rate
#adam梯度更新
def diy_adam(grad, weight):
#参数应当放在外面,此处为保持后方代码整洁简单实现一步
alpha = 1e-3 #学习率
beta1 = 0.9 #超参数(推荐)
beta2 = 0.999 #超参数(推荐)
eps = 1e-8 #超参数
t = 0 #初始化
mt = 0 #初始化
vt = 0 #初始化
#开始计算
t = t + 1
gt = grad
mt = beta1 * mt + (1 - beta1) * gt #前面的mt累积在后面的mt中,使前面的梯度占高比例,本轮的占低比例
vt = beta2 * vt + (1 - beta2) * gt ** 2
mth = mt / (1 - beta1 ** t) #分母不断增大,mth不断减小
vth = vt / (1 - beta2 ** t)
weight = weight - alpha * mth / (np.sqrt(vth) + eps) #alpha学习率动态调整
return weight
#手动实现loss计算
diy_model = DiyModel(numpy_model_w)
diy_loss = diy_model.forward(x, y)
print("diy模型计算loss:", diy_loss)
#手动实现反向传播
grad = diy_model.calculate_grad(diy_model.forward(x), y, x)
print(grad, "diy 计算梯度") #梯度的维度应与矩阵维度一致
#手动梯度更新
diy_update_w = diy_sgd(grad, numpy_model_w, learning_rate) #grad优化器
# diy_update_w = diy_adam(grad, numpy_model_w) #adam优化器
print(diy_update_w, "diy更新权重")
运行结果:
SGD优化器情况下:

Adam优化器的情况下:
















 2574
2574











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









