










毕业设计:2023-2024年计算机专业毕业设计选题汇总(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕设选题推荐汇总
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、项目介绍
技术栈:
Python语言、Flask框架、MySQL数据库、requests爬虫、多元线性回归预测算法、中国天气网、全国气象数据、requests爬虫 多元线性回归预测模型 scikit-learn机器学习LinearRegression()、定时爬虫
基于Flask机器学习的全国气象数据采集预测可视化系统
基于Flask的机器学习全国气象数据采集预测可视化系统是一个功能强大、易于使用的综合平台。它利用Python语言、Flask框架、MySQL数据库、requests爬虫、多元线性回归预测算法等技术手段,实现了对全国气象数据的采集、预测和可视化展示,为用户提供了准确、及时的气象信息服务。
2、项目界面
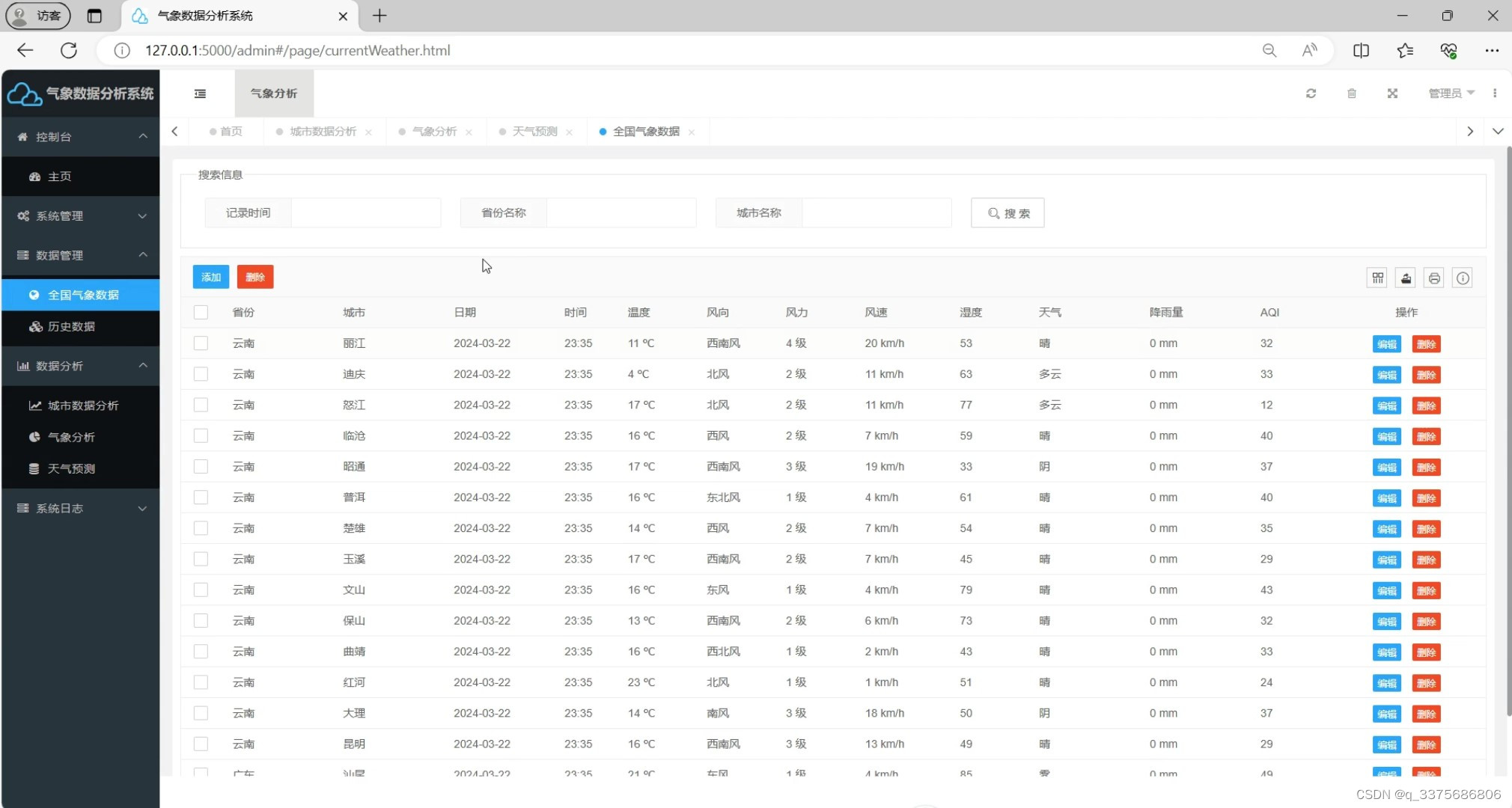
(1)全国气象数据概况
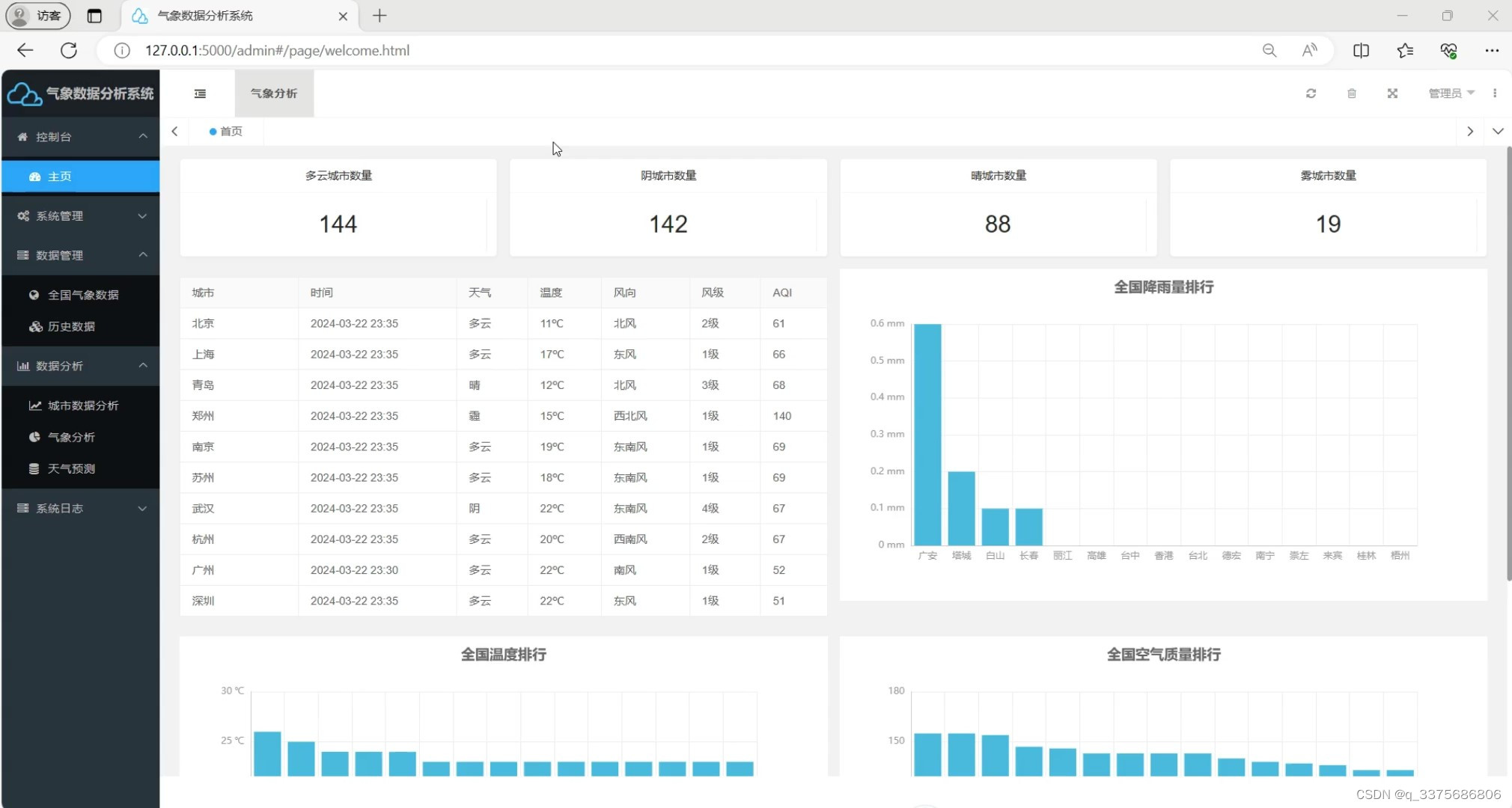
(2)全国各城市气象数据分析
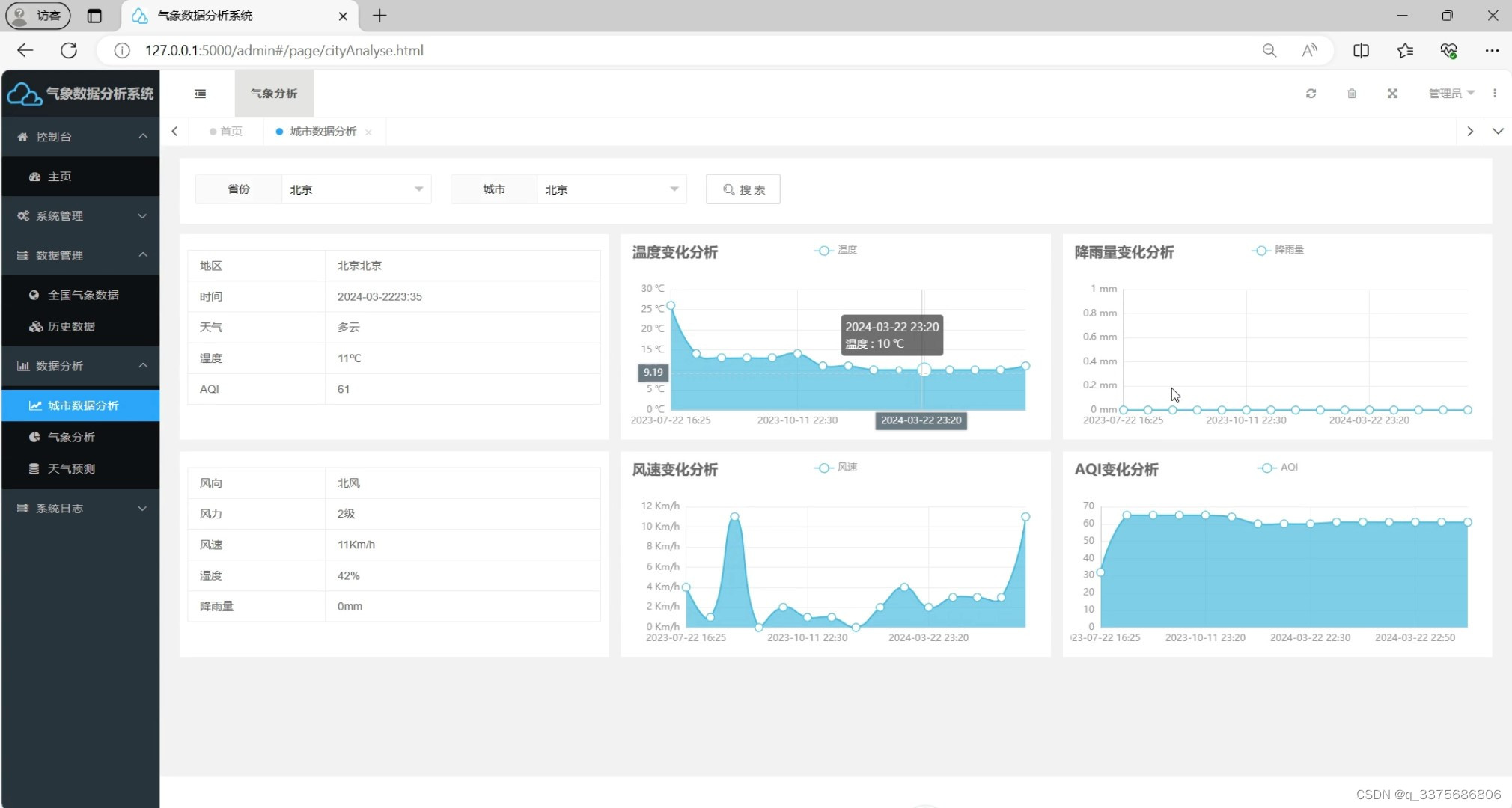
(3)气象数据分析
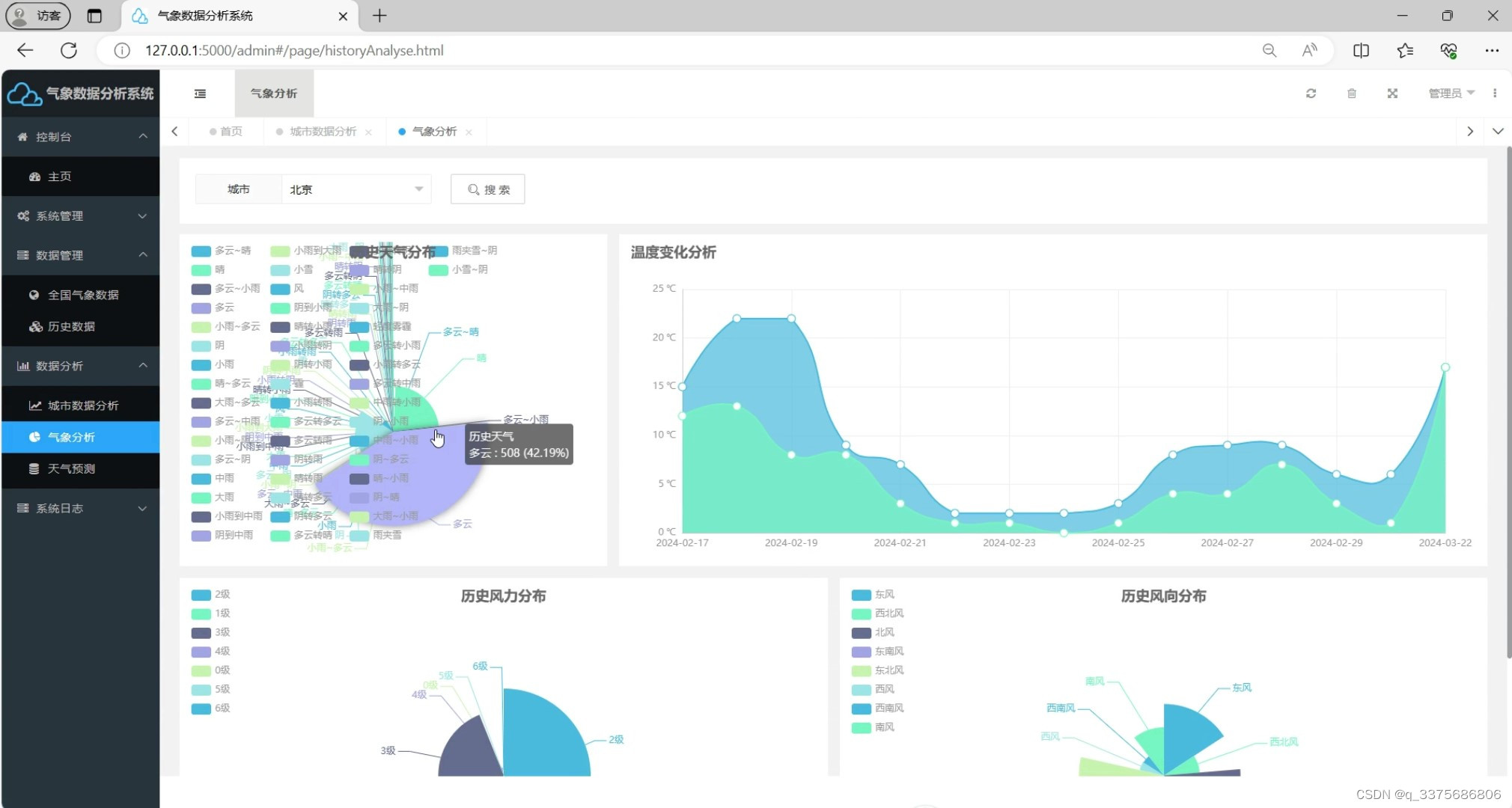
(4)天气预报-----天气预测(机器学习多元线性回归预测算法)
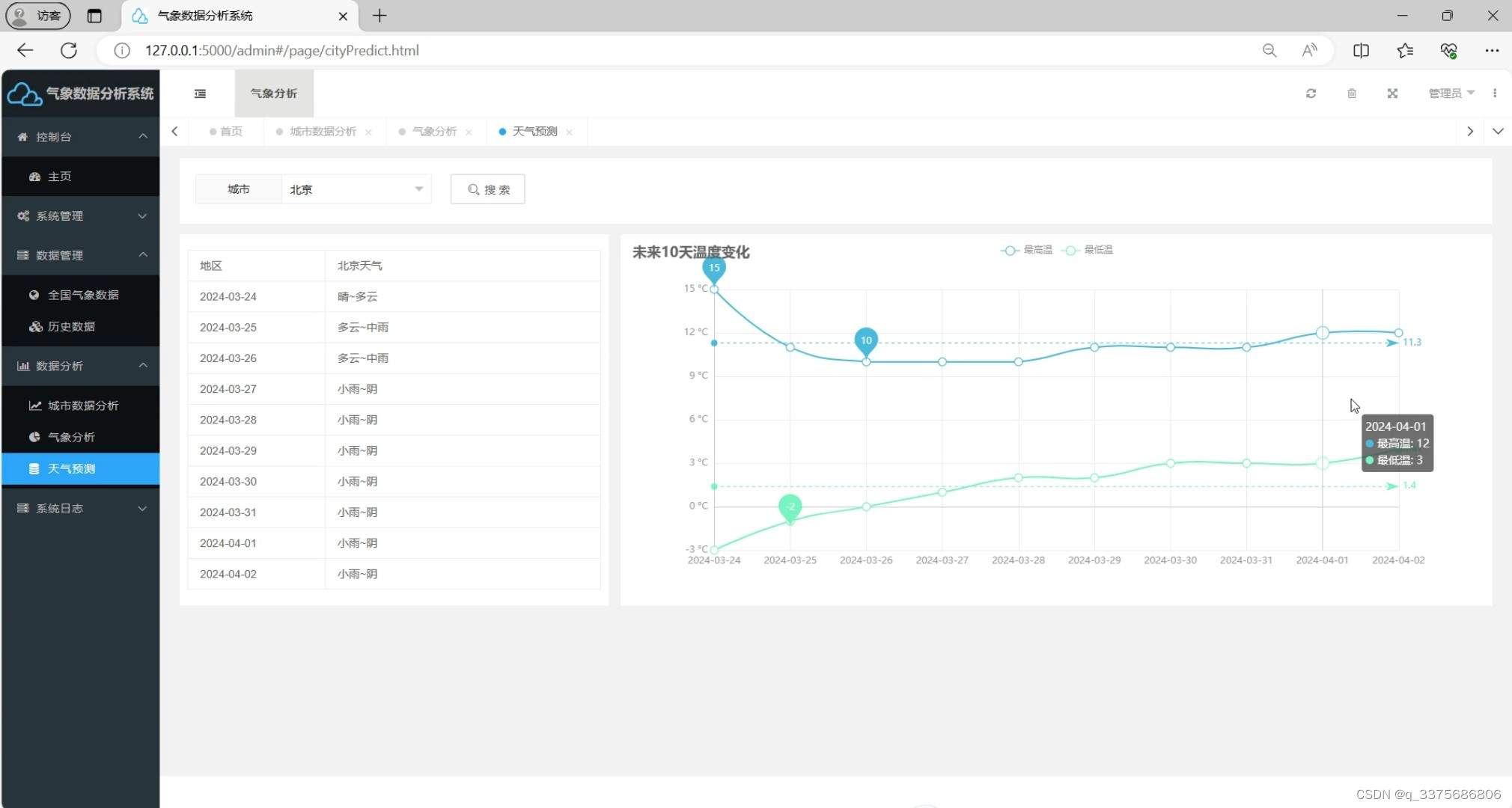
(5)全国气象数据管理
(6)注册登录界面
3、项目说明
基于Flask的机器学习全国气象数据采集预测可视化系统是一个集数据采集、处理、预测和可视化于一体的综合平台。该系统利用Python语言强大的数据处理能力和Flask框架的轻量级与灵活性,结合MySQL数据库进行数据存储和管理,旨在为用户提供准确、及时的气象预测信息。
系统首先通过requests爬虫技术,定时从全国各大气象站点抓取最新的气象数据,包括温度、湿度、风速等关键指标。这些原始数据经过清洗、整合后,被存储在MySQL数据库中,以便后续的分析和预测。
在数据预测方面,系统采用了多元线性回归预测算法,利用scikit-learn机器学习库中的LinearRegression()函数进行模型训练。通过对历史气象数据的分析,系统能够预测未来一段时间内的天气变化趋势,为用户提供科学、准确的预测结果。
Flask框架的引入,使得系统能够快速搭建Web界面,实现用户与系统的交互。用户可以通过Web界面查看实时的气象数据、历史数据走势图以及预测结果。同时,系统还提供了可视化工具,将复杂的数据以直观、易懂的方式展现出来,帮助用户更好地理解气象数据的变化规律。
此外,该系统还具备高度的可扩展性和灵活性。用户可以根据自己的需求,自定义爬虫规则、调整预测算法参数等,以满足不同场景下的气象数据采集和预测需求。
总之,基于Flask的机器学习全国气象数据采集预测可视化系统是一个功能强大、易于使用的综合平台。它利用Python语言、Flask框架、MySQL数据库、requests爬虫、多元线性回归预测算法等技术手段,实现了对全国气象数据的采集、预测和可视化展示,为用户提供了准确、及时的气象信息服务。
4、核心代码
import joblib
"""
多元线性回归预测
"""
import os
import machine_learning.deal_data as deal_data
# 加载模型
module_path = os.path.dirname(__file__)
path = module_path + '/model.joblib'
model = joblib.load(path)
# 预测数据(cityname, record_date, high, low, weather, wd, ws)
def predict(cityname, record_date, high, low, weather, wd, ws):
city = cityname
cityname, record_date, high, low, weather, wd, ws = deal_data.transformer_item(cityname, record_date, high, low,
weather, wd, ws)
next_input = [float(cityname), float(record_date), float(high), float(low), float(weather), float(wd), float(ws)]
result = []
for i in range(1, 11):
record_date, record_str = deal_data.getNextDay(i)
pred_y = model.predict([next_input])[0]
next_input = [float(cityname), float(record_date)]
next_input.extend(pred_y)
result.append(
deal_data.de_transformer_item(city, record_str, pred_y[0], pred_y[1], pred_y[2], pred_y[3], pred_y[4]))
return result
if __name__ == '__main__':
print(predict("闵行", "2023-10-15", 34, 28, "阴", "东南风", 2))
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻

















 1674
1674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









