










毕业设计:2023-2024年计算机专业毕业设计选题汇总(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕设选题推荐汇总
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、项目介绍
Python语言、Django框架 Scrapy爬虫框架、Echarts可视化、HTML、游侠网游戏数据爬取
http://www.youxiawang.com
字段:名称、时间、链接、类型、评分、热度、评分人数、简介
游戏数据采集可视化分析系统
在当今数字化时代,数据已经成为推动决策的重要力量。对于游戏行业而言,了解玩家的喜好、游戏的市场表现以及游戏类型的流行趋势等信息至关重要。为了满足这一需求,我们基于Python语言、Django框架、Scrapy爬虫框架以及Echarts可视化技术,打造了一款专注于游侠网游戏数据爬取与可视化分析的系统。
2、项目界面
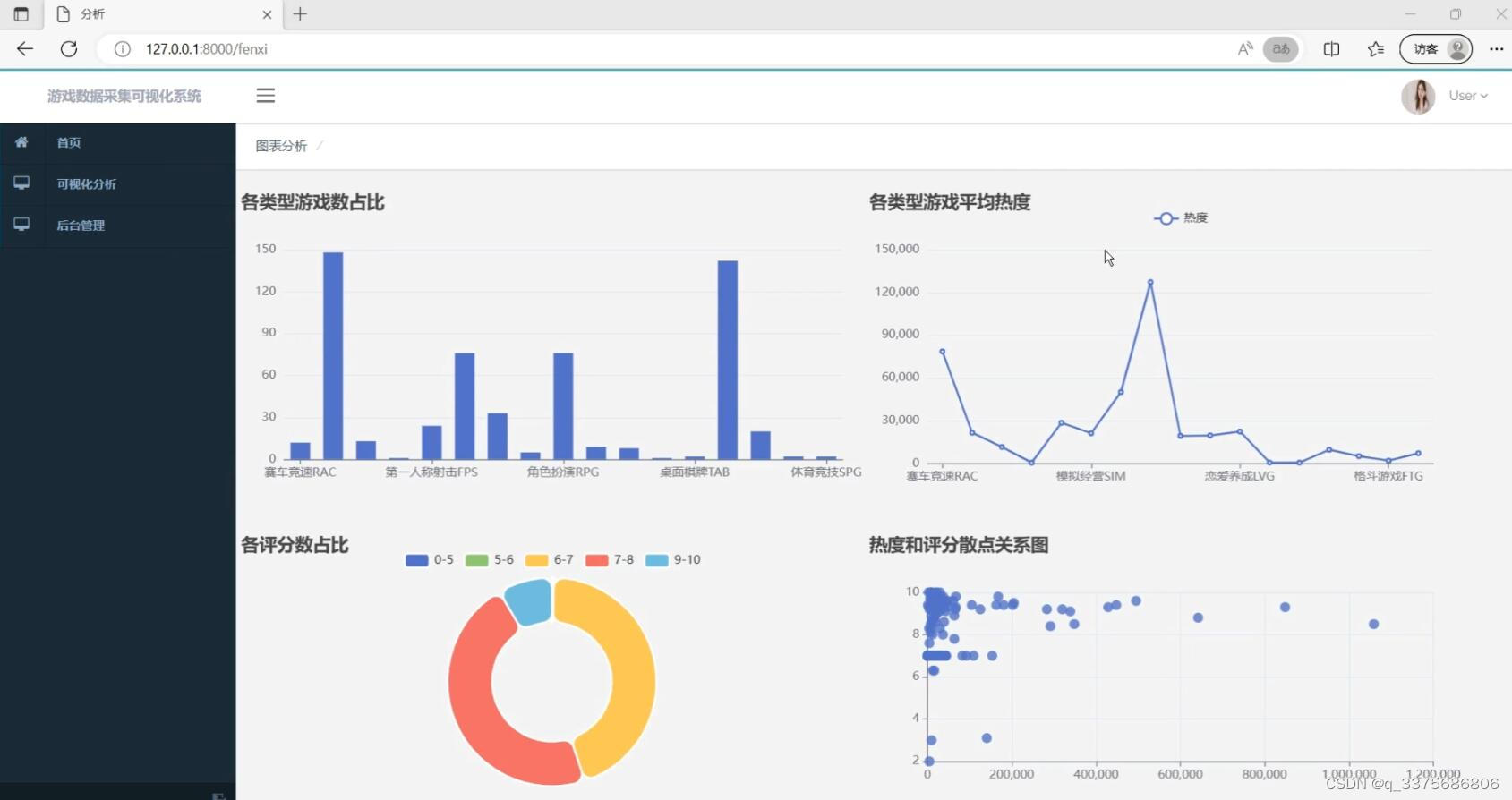
(1)游戏数据可视化分析
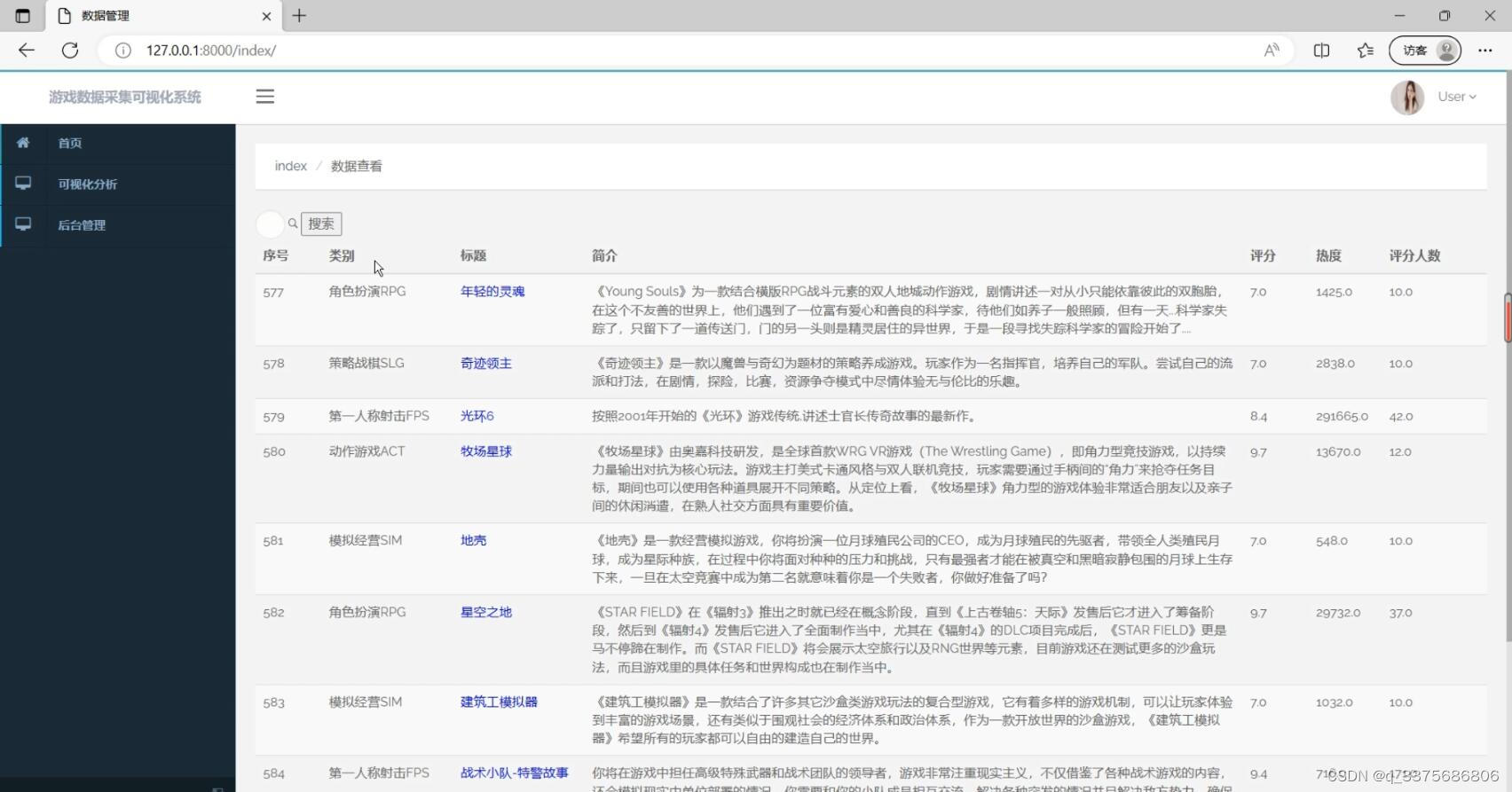
(2)游戏数据查看
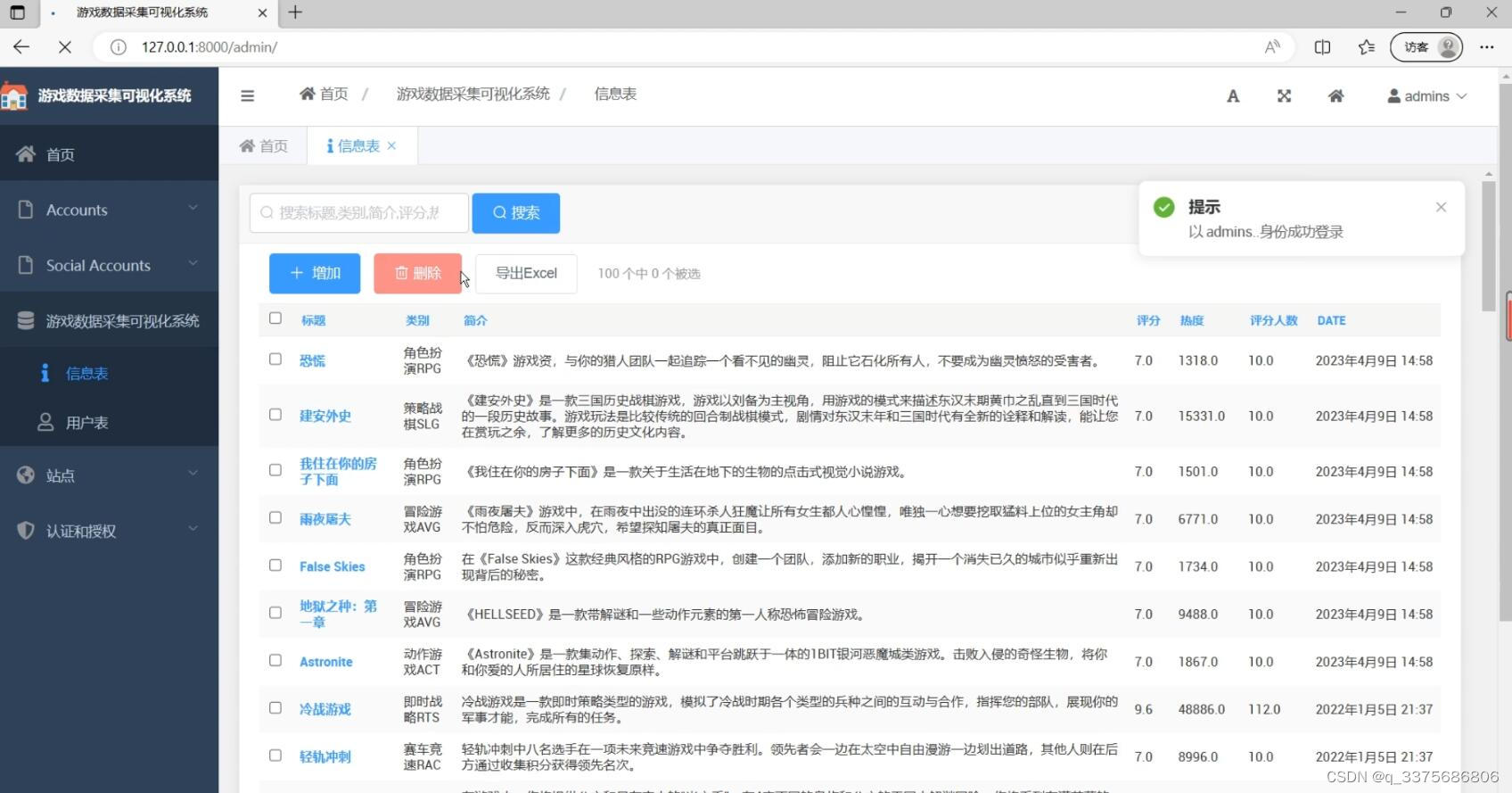
(3)后台管理
(4)注册登录界面
(5)数据爬取
3、项目说明
在当今数字化时代,数据已经成为推动决策的重要力量。对于游戏行业而言,了解玩家的喜好、游戏的市场表现以及游戏类型的流行趋势等信息至关重要。为了满足这一需求,我们基于Python语言、Django框架、Scrapy爬虫框架以及Echarts可视化技术,打造了一款专注于游侠网游戏数据爬取与可视化分析的系统。
该系统的主要功能是从游侠网(http://www.youxiawang.com)爬取游戏数据,并进行深入的分析和可视化展示。我们选取的关键字段包括游戏的名称、发布时间、游戏链接、类型、评分、热度、评分人数以及简介等,这些信息能够全面反映游戏的各方面情况。
首先,Scrapy爬虫框架负责从游侠网抓取数据。Scrapy是一个快速、高级的Web爬取框架,它可以帮助我们高效地获取网页数据。通过配置Scrapy的爬虫规则,我们可以精确地定位到目标数据,并将其抓取到本地数据库中。
接下来,Django框架负责数据的存储、管理和分析。Django是一个成熟、稳定的Web开发框架,它提供了丰富的功能组件和强大的ORM(对象关系映射)系统。我们将抓取到的数据存储在Django的模型中,并通过ORM系统进行管理和查询。同时,Django还提供了强大的模板系统和视图系统,我们可以利用这些系统构建出功能丰富的Web应用。
在数据分析方面,我们利用Python的数据处理库(如pandas)对游戏数据进行清洗、转换和聚合等操作。通过这些操作,我们可以从原始数据中提取出有价值的信息,如游戏的平均评分、评分分布、热度变化趋势等。
最后,Echarts可视化技术负责将分析结果以图表的形式展示出来。Echarts是一个使用JavaScript实现的开源可视化库,它提供了丰富的图表类型和灵活的配置选项。我们可以根据分析需求选择合适的图表类型(如柱状图、折线图、饼图等),并通过Echarts的配置选项对图表进行定制和优化。最终,这些图表将被嵌入到Django的模板中,并通过Web应用展示给用户。
通过这款游戏数据采集可视化分析系统,用户可以轻松地了解游侠网上游戏的各项数据指标,并根据这些指标进行深入的分析和决策。同时,该系统还具有良好的扩展性和可定制性,可以根据用户需求进行灵活的定制和优化。我们相信,这款系统将为游戏行业的从业者提供有力的数据支持和分析工具,帮助他们更好地把握市场动态和玩家需求。
4、核心代码
from django.shortcuts import render,HttpResponse,reverse,redirect
from django.contrib.auth.decorators import login_required
from KeShiHua import models
from django.db.models import Q
from django.shortcuts import get_object_or_404,HttpResponseRedirect
import json
import random
# Create your views here.
@login_required
def index(request):
if request.method == 'GET':
datas = models.XinXi.objects.all()
return render(request,r"app\table.html",locals())
elif request.method == 'POST':
data = request.POST
projects_name = data.get('search')
if not projects_name:
return redirect('web:index')
datas = models.XinXi.objects.filter(Q(name__icontains=projects_name)|Q(type__icontains=projects_name)|Q(jianjie__icontains=projects_name))
return render(request,r"app\table.html",locals())
@login_required
def fenxi(request):
if request.method == 'GET':
return render(request,'app/tubiao.html',locals())
def mean(a):
if len(a) == 0:
return 0
return round(sum(a) / len(a),2)
@login_required
def tubiao(request):
if request.method == 'GET':
datas = models.XinXi.objects.all()
# #各类型数量
types1 = []
for da1 in datas:
types1.append(da1.type)
type_name = []
type_count = []
for ty1 in list(set(types1)):
type_name.append(ty1)
type_count.append(types1.count(ty1))
#各类型游戏平均热度
redu_name = []
redu_count = []
for ty1 in list(set(types1)):
redu_name.append(ty1)
data11 = models.XinXi.objects.filter(type=ty1)
redu_count.append(mean([da3.rendu for da3 in data11]))
#各评分数占比
a1 = models.XinXi.objects.filter(pingfen__range=(0,5))
a2 = models.XinXi.objects.filter(pingfen__range=(5, 6))
a3 = models.XinXi.objects.filter(pingfen__range=(6, 7))
a4 = models.XinXi.objects.filter(pingfen__range=(7, 9))
a5 = models.XinXi.objects.filter(pingfen__range=(9, 10))
pingfe_name = ['0-5','5-6','6-7','7-8','9-10']
pingfe_count = [len(a1),len(a2),len(a3),len(a4),len(a5)]
pingfe_dict = []
for i in range(len(pingfe_name)):
pingfe_dict.append({'name':pingfe_name[i],'value':pingfe_count[i]})
#热度和评分散点关系图
redu_pingfen_dict2 = []
for resu in datas:
redu_pingfen_dict2.append([resu.rendu, resu.pingfen])
# 评价人数和评分关系图
pingjia_count_pingjia_dict2 = []
for resu in datas:
pingjia_count_pingjia_dict2.append([resu.pingfen_count, resu.pingfen])
return render(request,'app/keshihua.html',locals())
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻















 2265
2265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









