






本文首发于公众号:机器感知
多视角视频MAE;把任意人像插入到任意场景中;高分辨率可编辑视频卡通化;显示建模运动实现一致且可控的视频生成
Object-Driven One-Shot Fine-tuning of Text-to-Image Diffusion with Prototypical Embedding

As large-scale text-to-image generation models have made remarkable progress in the field of text-to-image generation, many fine-tuning methods have been proposed. However, these models often struggle with novel objects, especially with one-shot scenarios. Our proposed method aims to address the challenges of generalizability and fidelity in an object-driven way, using only a single input image and the object-specific regions of interest. To improve generalizability and mitigate overfitting, in our paradigm, a prototypical embedding is initialized based on the object's appearance and its class, before fine-tuning the diffusion model. And during fine-tuning, we propose a class-characterizing regularization to preserve prior knowledge of object classes. To further improve fidelity, we introduce object-specific loss, which can also use to implant multiple objects. Overall, our proposed object-driven method for implanting new objects can integrate seamlessly with existing concepts as well as with high fidelity and generalization.
MV2MAE: Multi-View Video Masked Autoencoders
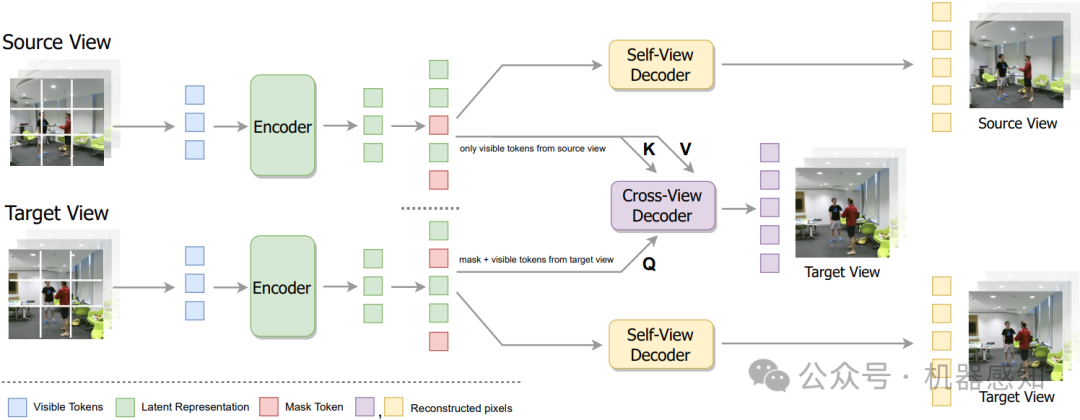
Videos captured from multiple viewpoints can help in perceiving the 3D structure of the world and benefit computer vision tasks such as action recognition, tracking, etc. In this paper, we present a method for self-supervised learning from synchronized multi-view videos. We use a cross-view reconstruction task to inject geometry information in the model. Our approach is based on the masked autoencoder (MAE) framework. In addition to the same-view decoder, we introduce a separate cross-view decoder which leverages cross-attention mechanism to reconstruct a target viewpoint video using a video from source viewpoint, to help representations robust to viewpoint changes. For videos, static regions can be reconstructed trivially which hinders learning meaningful representations. To tackle this, we introduce a motion-weighted reconstruction loss which improves temporal modeling.
StableIdentity: Inserting Anybody into Anywhere at First Sight

Recent advances in large pretrained text-to-image models have shown unprecedented capabilities for high-quality human-centric generation, however, customizing face identity is still an intractable problem. Existing methods cannot ensure stable identity preservation and flexible editability, even with several images for each subject during training. In this work, we propose StableIdentity, which allows identity-consistent recontextualization with just one face image. More specifically, we employ a face encoder with an identity prior to encode the input face, and then land the face representation into a space with an editable prior, which is constructed from celeb names. By incorporating identity prior and editability prior, the learned identity can be injected anywhere with various contexts. In addition, we design a masked two-phase diffusion loss to boost the pixel-level perception of the input face and maintain the diversity of generation. Extensive experiments demonstrate our method outperforms previous customization methods. In addition, the learned identity can be flexibly combined with the off-the-shelf modules such as ControlNet.
Motion-I2V: Consistent and Controllable Image-to-Video Generation with Explicit Motion Modeling
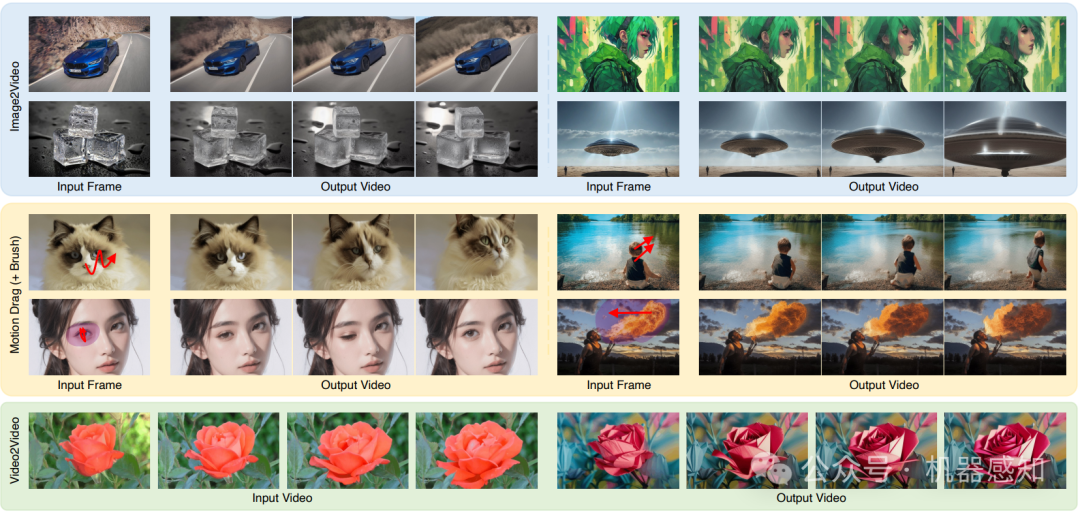
We introduce Motion-I2V, a novel framework for consistent and controllable image-to-video generation (I2V). In contrast to previous methods that directly learn the complicated image-to-video mapping, Motion-I2V factorizes I2V into two stages with explicit motion modeling. For the first stage, we propose a diffusion-based motion field predictor, which focuses on deducing the trajectories of the reference image's pixels. For the second stage, we propose motion-augmented temporal attention to enhance the limited 1-D temporal attention in video latent diffusion models. This module can effectively propagate reference image's feature to synthesized frames with the guidance of predicted trajectories from the first stage. Compared with existing methods, Motion-I2V can generate more consistent videos even at the presence of large motion and viewpoint variation. By training a sparse trajectory ControlNet for the first stage, Motion-I2V can support users to precisely control motion trajectories and motion regions with sparse trajectory and region annotations. This offers more controllability of the I2V process than solely relying on textual instructions. Additionally, Motion-I2V's second stage naturally supports zero-shot video-to-video translation.
Spatial-Aware Latent Initialization for Controllable Image Generation

Recently, text-to-image diffusion models have demonstrated impressive ability to generate high-quality images conditioned on the textual input. However, these models struggle to accurately adhere to textual instructions regarding spatial layout information. While previous research has primarily focused on aligning cross-attention maps with layout conditions, they overlook the impact of the initialization noise on the layout guidance. To achieve better layout control, we propose leveraging a spatial-aware initialization noise during the denoising process. Specifically, we find that the inverted reference image with finite inversion steps contains valuable spatial awareness regarding the object's position, resulting in similar layouts in the generated images. Based on this observation, we develop an open-vocabulary framework to customize a spatial-aware initialization noise for each layout condition. Without modifying other modules except the initialization noise, our approach can be seamlessly integrated as a plug-and-play module within other training-free layout guidance frameworks.
Diffutoon: High-Resolution Editable Toon Shading via Diffusion Models

Toon shading is a type of non-photorealistic rendering task of animation. Its primary purpose is to render objects with a flat and stylized appearance. As diffusion models have ascended to the forefront of image synthesis methodologies, this paper delves into an innovative form of toon shading based on diffusion models, aiming to directly render photorealistic videos into anime styles. In video stylization, extant methods encounter persistent challenges, notably in maintaining consistency and achieving high visual quality. In this paper, we model the toon shading problem as four subproblems: stylization, consistency enhancement, structure guidance, and colorization. To address the challenges in video stylization, we propose an effective toon shading approach called \textit{Diffutoon}. Diffutoon is capable of rendering remarkably detailed, high-resolution, and extended-duration videos in anime style. It can also edit the content according to prompts via an additional branch.
InternLM-XComposer2: Mastering Free-form Text-Image Composition and Comprehension in Vision-Language Large Model

We introduce InternLM-XComposer2, a cutting-edge vision-language model excelling in free-form text-image composition and comprehension. This model goes beyond conventional vision-language understanding, adeptly crafting interleaved text-image content from diverse inputs like outlines, detailed textual specifications, and reference images, enabling highly customizable content creation. InternLM-XComposer2 proposes a Partial LoRA (PLoRA) approach that applies additional LoRA parameters exclusively to image tokens to preserve the integrity of pre-trained language knowledge, striking a balance between precise vision understanding and text composition with literary talent. Experimental results demonstrate the superiority of InternLM-XComposer2 based on InternLM2-7B in producing high-quality long-text multi-modal content and its exceptional vision-language understanding performance across various benchmarks, where it not only significantly outperforms existing multimodal models but also matches or even surpasses GPT-4V and Gemini Pro in certain assessments. This highlights its remarkable proficiency in the realm of multimodal understanding.
















 1539
1539











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









