







 本文介绍了支持向量机的基本概念,包括线性分类器、最大间隔超平面和法向量。讨论了如何通过拉格朗日乘数法寻找最优超平面,以及支持向量机的目标是最大化数据点到超平面的最短距离。最终,文章简要提到了求解过程中的序列最小化算法(SMO)。
本文介绍了支持向量机的基本概念,包括线性分类器、最大间隔超平面和法向量。讨论了如何通过拉格朗日乘数法寻找最优超平面,以及支持向量机的目标是最大化数据点到超平面的最短距离。最终,文章简要提到了求解过程中的序列最小化算法(SMO)。
这篇文章仅介绍支持向量机的基础知识,不涉及特别复杂的求解。不清楚基础知识的小伙伴可以看一下这篇文章。
首先呢,支持向量机解决的是将数据点分成两类的问题。本文只考虑线性分类器。对于二维的数据而言,就是要找到一条直线,将数据点分成两类,一类在直线这边,另一类在直线那边。对于更高维,比如 n n n维的数据,就是要找到一个“超平面”,将数据分到超平面两侧。这里的“超平面”一定是 n − 1 n-1 n−1维的,它的方程一定是 a 1 x 1 + a 2 x 2 + ⋯ + a n x n + b = 0 a_1x_1+a_2x_2+\cdots+a_nx_n+b=0 a1x1+a2x2+⋯+anxn+b=0因为增加一个(有效的)约束条件就相当于降一维,在原来没有约束条件( n n n维)的基础上增加一个方程就降到了 ( n − 1 ) (n-1) (n−1)维。例如,在三维中,“超平面”就是二维的平面;二维中,“超平面”就是一维的直线。不论如何,超平面的方程一定是线性函数,这就是为什么叫线性分类器。
观察上面那个式子,用线性代数的知识我们很容易看出左边可以写成两个向量内积的形式。令 w = [ a 1 a 2 ⋯ a n ] \bm w=\begin{bmatrix}a_1\\a_2\\\cdots\\a_n\end{bmatrix} w= a1a2⋯an , x = [ x 1 x 2 ⋯ x n ] \bm x=\begin{bmatrix}x_1\\x_2\\\cdots\\x_n\end{bmatrix} x= x1x2⋯xn ,则超平面的方程一定可以表示为 w T x + b = 0 {\bm w}^T\bm x+b=0 wTx+b=0特别地,在二维的情况下, x = [ x y ] \bm x=\begin{bmatrix}x\\y\end{bmatrix} x=[xy], w T x + b = 0 {\bm w}^T\bm x+b=0 wTx+b=0就是直线 A x + B y + C = 0 Ax+By+C=0 Ax+By+C=0。
这个向量 w \bm w w的含义是什么呢?其实它就是超平面的法向量。我们知道,法向量与超平面上的任意向量正交(垂直)。任取超平面上两点 x 1 , x 2 \bm x_1,\bm x_2 x1,x2,则 x 2 − x 1 \bm x_2-\bm x_1 x2−x1就是平面上的一个向量,而 w T ( x 2 − x 1 ) = w T x 1 − w T x 2 = ( − b ) − ( − b ) = 0 \bm w^T(\bm x_2-\bm x_1)={\bm w}^T\bm x_1-{\bm w}^T\bm x_2=(-b)-(-b)=0 wT(x2−x1)=wTx1−wTx2=(−b)−(−b)=0,所以 w T \bm w^T wT与 x 2 − x 1 \bm x_2-\bm x_1 x2−x1正交, w \bm w w与超平面上的任意向量垂直,故 w \bm w w是超平面的法向量。特别地,直线 A x + B y + C = 0 Ax+By+C=0 Ax+By+C=0的法向量就是 ( A , B ) (A,B) (A,B)。
那我们的目标是什么呢?且看下图:
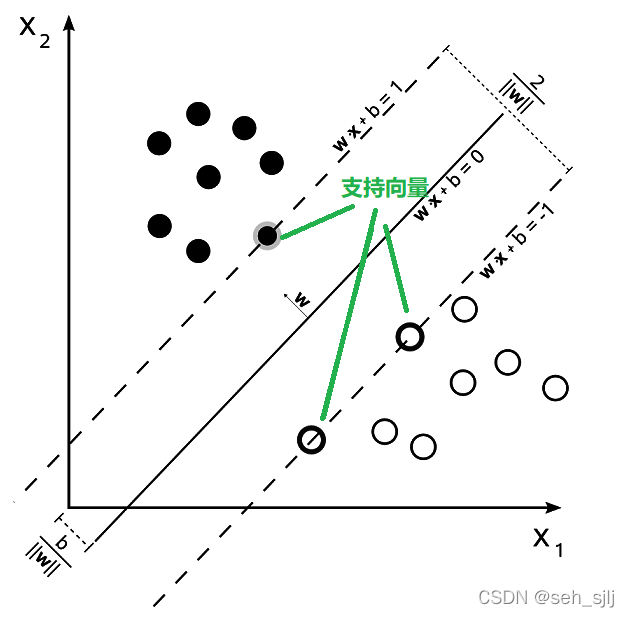
对于这些数据点,显然有无数条直线可以把它们完全分成两类。选哪条最好呢?答案是:选择的这条直线,离它最近的数据点距离它的距离必须最大。换言之:我们要最大化数据点到直线的最短距离。离直线最近的数据点就是支持向量(Support Vector),任意维数中分割数据的超平面称为最大间隔超平面(在这里就是这条直线)。
怎么计算一个点到直线的距离呢?假设对于数据点
x
\bm x
x,我们要计算它到直线
w
T
x
+
b
=
0
\bm w^T\bm x+b=0
wTx+b=0的距离。取直线上任一点
x
0
\bm x_0
x0,则
x
\bm x
x到
x
0
\bm x_0
x0的距离为
∥
x
−
x
0
∥
\|\bm x-\bm x_0\|
∥x−x0∥。令
x
−
x
0
\bm x-\bm x_0
x−x0垂直于直线,则
x
−
x
0
\bm x-\bm x_0
x−x0于直线的法向量
w
\bm w
w平行,即
x
−
x
0
=
λ
w
\bm x-\bm x_0=\lambda\bm w
x−x0=λw,
x
0
=
x
−
λ
w
\bm x_0=\bm x-\lambda\bm w
x0=x−λw。而
x
0
\bm x_0
x0在直线上,有
w
T
x
0
+
b
=
0
\bm w^T\bm x_0+b=0
wTx0+b=0,带入得
w
T
x
−
λ
w
T
w
+
b
=
0
\bm w^T\bm x-\lambda\bm w^T\bm w+b=0
wTx−λwTw+b=0,
λ
w
T
w
=
w
T
x
+
b
\lambda\bm w^T\bm w=\bm w^T\bm x+b
λwTw=wTx+b,解得
λ
=
w
T
x
+
b
∥
w
∥
2
\lambda=\frac{\bm w^T\bm x+b}{\|\bm w\|^2}
λ=∥w∥2wTx+b
∥
x
−
x
0
∥
=
∥
λ
w
∥
=
∣
w
T
x
+
b
∣
∥
w
∥
\|\bm x-\bm x_0\|=\|\lambda\bm w\|=\frac{|\bm w^T\bm x+b|}{\|\bm w\|}
∥x−x0∥=∥λw∥=∥w∥∣wTx+b∣这就是
x
\bm x
x到直线的距离。这个公式对于任意维数的超平面都成立。
怎么表示分类的结果呢?其实就是一个函数 y = f ( x ) y=f(\bm x) y=f(x),使得对于一类 x \bm x x有 f ( x ) = 1 f(\bm x)=1 f(x)=1,另一类有 f ( x ) = − 1 f(\bm x)=-1 f(x)=−1。
回到点 x \bm x x到直线的距离公式,如果我们把分子的绝对值去掉,那这个距离就可能是负的。但是,有一个很好的性质:在直线上方的这类点距离为正,下面为负。如果我们定义上面这类点 y y y值为 + 1 +1 +1,下面为 − 1 -1 −1,那 y w T x + b ∥ w ∥ y\cfrac{\bm w^T\bm x+b}{\|\bm w\|} y∥w∥wTx+b就是恒正的。我们称 γ ~ ( x ) = y w T x + b ∥ w ∥ \tilde{\gamma}(\bm x)=y\cfrac{\bm w^T\bm x+b}{\|\bm w\|} γ~(x)=y∥w∥wTx+b为 x \bm x x的几何间隔,它恒正,如果是负的,表示出现了分类错误。
假设数据点到直线的最短距离为
d
d
d,则
y
w
T
x
+
b
∥
w
∥
=
d
y\cfrac{\bm w^T\bm x+b}{\|\bm w\|}=d
y∥w∥wTx+b=d。令
∥
w
∥
=
1
d
\|\bm w\|=\frac1d
∥w∥=d1,则有
min
y
(
w
T
x
+
b
)
=
1
\min y(\bm w^T\bm x+b)=1
miny(wTx+b)=1。这样做是为了方便计算,此时支持向量在直线
w
T
x
+
b
=
±
1
\bm w^T\bm x+b=\pm 1
wTx+b=±1上。(其中
γ
^
(
x
)
=
y
(
w
T
x
+
b
)
\hat\gamma(\bm x)=y(\bm w^T\bm x+b)
γ^(x)=y(wTx+b)称为函数间隔。)那么,对于任意数据点
x
i
\bm x_i
xi,有
y
i
(
w
T
x
i
+
b
)
≥
1
y_i(\bm w^T\bm x_i+b)\ge 1
yi(wTxi+b)≥1。这个约束条件相当于规定了数据点不能落在直线
w
T
x
+
b
=
1
\bm w^T\bm x+b=1
wTx+b=1与
w
T
x
+
b
=
−
1
\bm w^T\bm x+b=-1
wTx+b=−1之间。现在要让
d
d
d最大,就是让
1
∥
w
∥
\frac1{\|\bm w\|}
∥w∥1最大。问题转化为求
max
w
,
b
1
∥
w
∥
,
s.t.
y
i
(
w
T
x
i
+
b
)
≥
1
\max_{\bm w,b}\frac1{\|\bm w\|},\ \text{s.t. }y_i(\bm w^T\bm x_i+b)\ge1
w,bmax∥w∥1, s.t. yi(wTxi+b)≥1要让
1
∥
w
∥
\frac1{\|\bm w\|}
∥w∥1最大,就是让
1
2
∥
w
∥
2
\frac12\|\bm w\|^2
21∥w∥2最小。问题又转化为求
min
w
,
b
1
2
∥
w
∥
2
,
s.t.
y
i
(
w
T
x
i
+
b
)
≥
1
\min_{\bm w,b}\frac12\|\bm w\|^2,\ \text{s.t. }y_i(\bm w^T\bm x_i+b)\ge1
w,bmin21∥w∥2, s.t. yi(wTxi+b)≥1这里平方是为了去除
∥
w
∥
\|\bm w\|
∥w∥的根号,乘
1
2
\frac12
21是为了简化计算。
接下来就要用拉格朗日乘数法了。设有
n
n
n个数据,就有
n
n
n个约束条件。于普通的拉格朗日乘数法不同,这里的约束条件是“大于等于”,不是等于,所以需要一些别出心裁的设计。按照套路,定义拉格朗日函数
L
(
w
,
b
,
α
)
=
1
2
∥
w
∥
2
−
∑
i
=
1
n
α
i
[
y
i
(
w
T
x
i
+
b
)
−
1
]
L(\bm w,b,\bm\alpha)=\frac12\|\bm w\|^2-\sum_{i=1}^n\alpha_i[y_i(\bm w^T{\bm x}_i+b)-1]
L(w,b,α)=21∥w∥2−i=1∑nαi[yi(wTxi+b)−1]其中
α
=
(
α
1
,
α
2
,
⋯
,
α
n
)
\bm\alpha=(\alpha_1,\alpha_2,\cdots,\alpha_n)
α=(α1,α2,⋯,αn)是拉格朗日乘数。令
θ
(
w
)
=
max
α
i
≥
0
L
(
w
,
b
,
α
)
\theta(\bm w)=\max_{\alpha_i\ge0}L(\bm w,b,\bm\alpha)
θ(w)=αi≥0maxL(w,b,α)添加约束条件
α
i
≥
0
\alpha_i\ge0
αi≥0就是解决“大于等于”的问题。试想,假如某个约束条件不满足,即
y
i
(
w
T
x
i
+
b
)
<
1
y_i(\bm w^T\bm x_i+b)<1
yi(wTxi+b)<1,那么对应的那一项
−
α
i
[
y
i
(
w
T
x
i
+
b
)
−
1
]
>
0
-\alpha_i[y_i(\bm w^T\bm x_i+b)-1]>0
−αi[yi(wTxi+b)−1]>0,此时取
α
i
→
∞
\alpha_i\to\infty
αi→∞就有
θ
(
w
)
→
∞
\theta(\bm w)\to\infty
θ(w)→∞,所以条件不满足是很容易甄别出来的。
接下来令 ∂ L ∂ w = ∂ L ∂ b = 0 \frac{\partial L}{\partial \bm w}=\frac{\partial L}{\partial b}=0 ∂w∂L=∂b∂L=0,得到 w = ∑ i = 1 n α i y i x i 0 = ∑ i = 1 n α i y i \begin{aligned} \bm w&=\sum\limits_{i=1}^{n} \alpha_i y_i{\bm x}_i\\ 0&=\sum\limits_{i=1}^{n} \alpha_i y_i \end{aligned} w0=i=1∑nαiyixi=i=1∑nαiyi
代入拉格朗日方程得到 L ~ ( α ) = ∑ i = 1 n α i − 1 2 ∑ i = 1 n ∑ j = 1 n α i α j y i y j x i T x j s.t. α i ≥ 0 , i = 1 , 2 , ⋯ , n ∑ i = 1 n α i y i = 0 \tilde{L}(\bm\alpha)=\sum\limits_{i=1}^{n} \alpha_i-\frac{1}{2}\sum\limits_{i=1}^{n}\sum\limits_{j=1}^{n}\alpha_i \alpha_j y_i y_j {{\bm x}_i}^{T}{\bm x}_j\\ \text{s.t. }\alpha_i\ge 0,\ i=1,2,\cdots,n\\ \sum\limits_{i=1}^{n}\alpha_i y_i=0 L~(α)=i=1∑nαi−21i=1∑nj=1∑nαiαjyiyjxiTxjs.t. αi≥0, i=1,2,⋯,ni=1∑nαiyi=0
根据上述条件,我们使用序列最小化算法(Sequential Minimal Optimization, SMO)(详见http://chubakbidpaa.com/svm/2020/12/27/smo-algorithm-simplifed-copy.html)获得 α \bm\alpha α的最优值,最后分类器的形式为 f ( x ) = ∑ i = 1 n α i y i x T x i + b f(\bm x)=\sum\limits_{i=1}^{n}\alpha_i y_i{\bm x}^{T}{\bm x}_i+b f(x)=i=1∑nαiyixTxi+b其正负代表了 x \bm x x处于 + 1 +1 +1类还是 − 1 -1 −1类。
好啦,这篇文章的使命到此就结束了,关于SMO算法的内容就超出我的知识范围了,涉及到二次规划、KTT条件什么的。希望对你理解SVM的基础知识有帮助~

















 5023
5023

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









