






day1
环境:远程服务器(完全空白)
Linux version 5.4.0-150-generic (buildd@bos03-amd64-012) ~内核版本
(gcc version 7.5.0 (Ubuntu 7.5.0-3ubuntu1~18.04)) ->gcc编译版本/ubuntu18.04
问题1:无法使用git指令
解决方案:https://blog.csdn.net/wyf2017/article/details/122026573
换源操作:将官方源更换为阿里源
https://www.cnblogs.com/ledzb/p/17818699.html
出现签名错误
提升tmp权限
https://blog.csdn.net/MEIYOUDAO_JIUSHIDAO/article/details/103512888
问题2:python安装
方式1:apt安装~安装失败
方式二:源码安装~安装版本3.10.0(yolov5/yolov8均适用)
csdn:https://blog.csdn.net/weixin_43935402/article/details/121416812
bilibili:https://www.bilibili.com/video/BV1uT41197ih/?spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=07e4400c1b20fce3deaf5acec0b8e69b
问题三:标注工具闪退问题
自己电脑因路径中含中文所以造成闪退
解决方案:1.使用虚拟机进行标注(最终生成.txt文件)
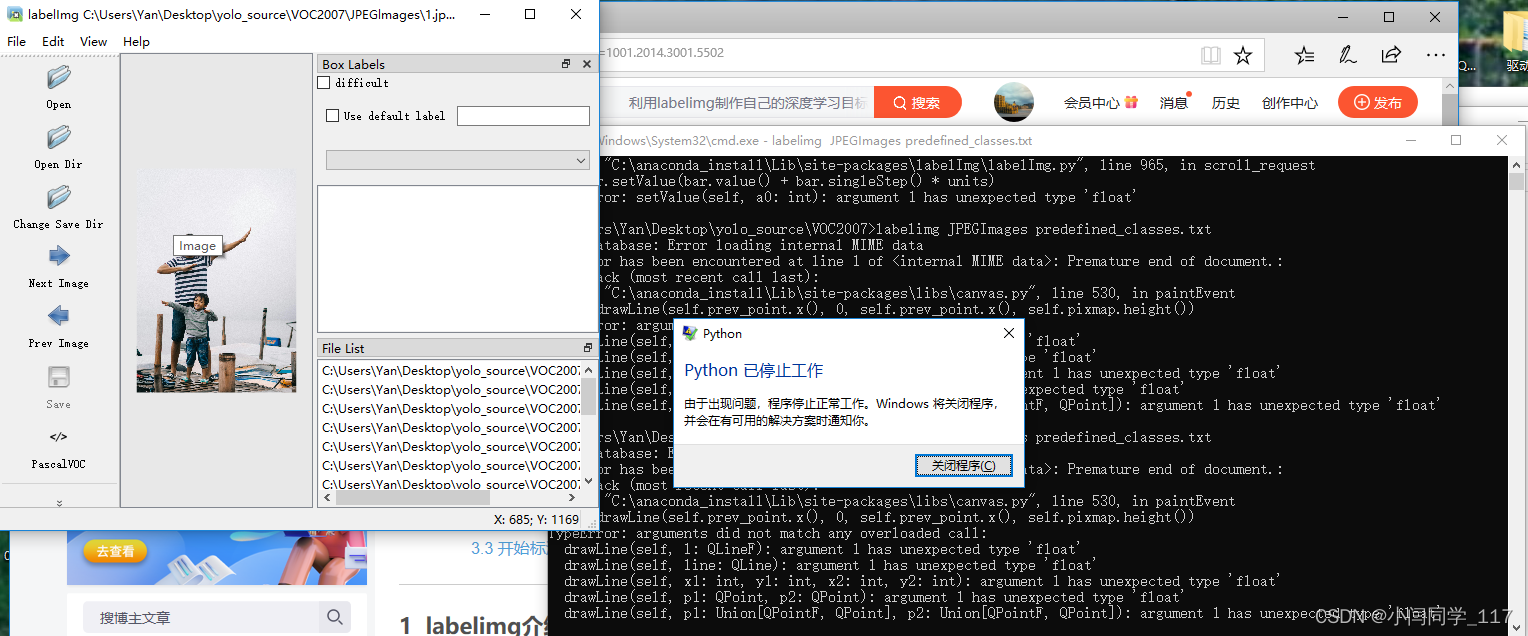
基于此解决方案
1.2解决问题
1.2更换标注工具
1.3使用plan2
2.完全依托于服务器在服务器中搭建环境进行标注
3.更换设备进行标注(标注最终结果要的是.txt文件)
环境中缺少libc6相关依赖由于升级至高版本服务器以至于最终

头一次这么快玩坏一个端口😂 ~ 24.4.7
day2
因为昨天把端口玩坏了,所以一切重来
使用git下载代码
git clone https://github.com/ultralytics/ultralytics
问题1:bash: git: command not found
apt-get update
问题2:E: Unable to fetch some archives, maybe run apt-get update or try with --fix-missing?
apt-get update
问题3: Some index files failed to download. They have been ignored, or old ones used instead.
解决方案:进行换源操作(阿里)并且提升用户权限
学姐指点安装anaconda
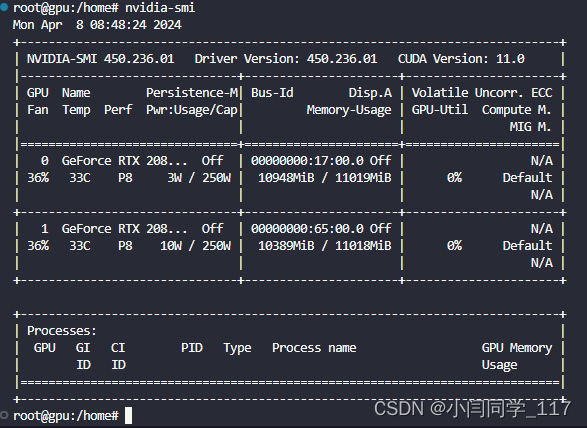
支持cuda最高版本为11.0
当前环境
环境安装
https://learnku.com/articles/59694使用清华源
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
出现错误

解决:https://blog.csdn.net/qq_50195602/article/details/124188467
字体错误
https://blog.csdn.net/ZHUO__zhuo/article/details/124412730
https://blog.csdn.net/aaallf/article/details/121803582?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522165085728416782395322009%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=165085728416782395322009&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allbaidu_landing_v2~default-1-121803582.142%5Ev9%5Epc_search_result_control_group,157%5Ev4%5Econtrol&utm_term=+check_font&spm=1018.2226.3001.4187
labelimg解决方案root
https://blog.csdn.net/m0_63924821/article/details/133993216
day3
重新安装yolov5环境
按照b站视频
pytorch及cuda版本安装,由于服务器最高支持11.0所以采用如下解决方案
清华源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
conda config --set show_channel_urls yes
pytorch版本
https://pytorch.org/get-started/previous-versions/
官网代码
https://blog.csdn.net/qq_43426078/article/details/123516446
conda install pytorch1.7.0 torchvision0.8.0 torchaudio==0.7.0 cudatoolkit=11.0 -c pytorch
下面这行代码
conda install pytorch torchvision torchaudio cudatoolkit=10.2 -c pytorch
b站教程https://www.bilibili.com/video/BV1pG4y1h72V/?spm_id_from=333.880.my_history.page.click&vd_source=07e4400c1b20fce3deaf5acec0b8e69b
查看cuda版本号
nvidia-smi
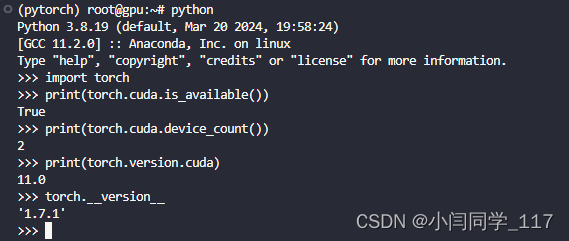
使用这个命令安装的刚好是学校服务器可以接受最高版本:conda install pytorch1.7.1 torchvision0.8.2 torchaudio==0.7.2 cudatoolkit=11.0 -c pytorch
>>> import torch
>>> print(torch.cuda.is_available())
True
>>> print(torch.__version__)
1.7.1
>>> print(torch.version.cuda)
11.0
>>> print(torch.cuda.device_count())
2
由于服务器断网,使用cpu在本地搭建anaconda、yolo环境(由于c盘用户路径存在中文所以对数据进行备份并且进行恢复出厂设置)最终达到预期
day4
学姐给的是json文件编写python代码将其转换为txt文件由于不确定自己转换的代码能否使用,所以将json代码转换为txt文件在使用txt文件转换为xml文件最终使用官方代码将xml文件转换为txt文件
学校服务器实现gpu历程~事实证明这样不对,直接将json文件转换为txt文件==>第一次运行(训练集与测试集相同)效果挺好的(523张图片/300轮)
day5
学姐讲不能使用相同的训练集与测试集于是乎将训练集与测试集按照4:1比例进行分割对模型进行训练训练300轮(训练结果非常差要么识别不出要么预测结果非常不好),所以将训练轮数增大为600轮==>结果比较不错(411:112)+600先保存生成的.pt文件
------------------------------------------这是一条线(yolo部分暂时结束)-----------------------------------------------
day6
对于deepstream的初步探索
0.Jetson nano(可行但是没必要~没有硬件支持)
1.服务器开整
于是乎~~
1.服务器使用deepstream
deepstream环境搭建
<1.新建虚拟环境
conda create -n deepstream python=3.8
<2.检查cuda版本号 输出cuda11.0(之前安装yolo时可能已经配置好了)以及driver version(版本号)
nvidia-smi
< 3.使用这个命令安装的刚好是学校服务器可以接受最高版本:conda install pytorch1.7.1 torchvision0.8.2 torchaudio==0.7.2 cudatoolkit=11.0 -c pytorch
<4.检查pytorch相关信息
>>> import torch
>>> print(torch.cuda.is_available())
True
>>> print(torch.backends.cudnn.is_available())
True
>>> print(torch.__version__)
1.7.0
>>> print(torch.version.cuda)
11.0
>>> print(torch.cuda.device_count())
2
>>> print(torch.backends.cudnn.version())
8003
<5.检查必要安装依赖
检查cuda是否安装好
import torch #包引用
print(torch.cuda.is_available()) #cuda是否安装好
print(torch.backends.cudnn.is_available()) #cudnn是否安装好
print(torch.cuda.version()) #cuda版本号
print(torch.backends.cudnn.version()) #cudnn版本号
<6.tensorRT
参考博客如下
https://blog.csdn.net/m0_73702795/article/details/127940733
一定要下载与cuda相同的不然将是一场浩劫,当我按照上面的博客稳扎稳打解决无数的问题之后以为马上就要柳暗花明了,结果到最后安装deepstream时发现服务器所能容忍的版本根本没有对应版本的deepstream,于是乎采用如下命令将废了九牛二虎之力下载下来的tensorrt卸载掉(那个版本是对应于cuda11.0的)至于后面所安装的librdkafka和GStreamer先不用管
day7
因为服务器最高能够安装cuda版本为11.0并且考虑到deepstream能够接受的版本最终选择安装cuda10.2版本,于是乎踩坑安装流程如下:
<1.在anaconda里面新建虚拟环境
conda create -n deepstream_test python=3.8
<2.查看cuda容忍最大版本号
nvidia-smi
< 3.安装cuda驱动(这一步以及之前和yolo的相同)
conda install pytorch==1.10.0 torchvision torchaudio cudatoolkit=10.2
<4.使用python验证一下,代码及输出类似下面
>>> import torch
>>> print(torch.cuda.is_available())
True
>>> print(torch.backends.cudnn.is_available())
True
>>> print(torch.__version__)
1.10.0
>>> print(torch.version.cuda) //cuda
10.2
>>> print(torch.cuda.device_count())
2
>>> print(torch.backends.cudnn.version()) //cudnn
7605
<5.在确定自己的cuda安装的没有问题后进入tensorrt的安装tentorrt官网(必要的时候科学上网),在这里一定一定一定要找到合适的版本不然会出现巨多的错误,还有就是在这之后貌似会添加一个英伟达的源(这个非常重要)会让你安装密匙,解决方案如下:
1.直接从乌班图官方下载(未通过,原因:未知)
2.从英伟达官网下载密匙(未通过,原因:未知)~这两个真的巨耗时
3.从乌班图官网下载上传到服务器通过指令添加(pass)~自己csdn一下吧指令忘记了😂
<6.如果你的终端出现了如下的输出那么恭喜你已经完成了60%
<7.按照上面的博客对librdkafka和GStreamer进行安装,虽然之前安装过但是如果不把这些命令执行一遍会有警告~这一步执行过了就可以了没啥大坑
<8.重头戏~安装deepstream
<8.1要选择适配的版本、要选择适配的版本、要选择适配的版本;不然将会出现很多依赖没有的情况(第一天就是在这里被打趴下的),当然即使选择了适配的版本可能还是会有依赖未进行安装(还记得之前将英伟达源添加到系统并且进行一个耗时操作吗,这时候就要起作用了),缺啥安啥,例如
这个报错
The following packages have unmet dependencies:
tensorrt : Depends: libnvinfer-dev (= 6.0.1-1+cuda10.2) but 8.6.1.6-1+cuda12.0 is to be installed
Depends: libnvinfer-plugin-dev (= 6.0.1-1+cuda10.2) but 8.6.1.6-1+cuda12.0 is to be installed
Depends: libnvparsers-dev (= 6.0.1-1+cuda10.2) but 8.6.1.6-1+cuda12.0 is to be installed
Depends: libnvonnxparsers-dev (= 6.0.1-1+cuda10.2) but 8.6.1.6-1+cuda12.0 is to be installed
Depends: libnvinfer-samples (= 6.0.1-1+cuda10.2) but 8.6.1.6-1+cuda12.0 is to be installed
Depends: libnvinfer-doc (= 6.0.1-1+cuda10.2) but 7.0.0-1+cuda10.2 is to be installed
E: Unable to correct problems, you have held broken packages.
解决方案如下:
1.移除旧依赖
sudo apt-get remove libnvinfer-dev libnvinfer-plugin-dev libnvparsers-dev libnvonnxparsers-dev libnvinfer-samples libnvinfer-doc
2.安装新依赖~对应终端输出信息进行修改相应的版本
sudo apt-get install libnvinfer-dev=6.0.1-1+cuda10.2 libnvinfer-plugin-dev=6.0.1-1+cuda10.2 libnvparsers-dev=6.0.1-1+cuda10.2 libnvonnxparsers-dev=6.0.1-1+cuda10.2 libnvinfer-samples=6.0.1-1+cuda10.2 libnvinfer-doc=6.0.1-1+cuda10.2
<8.2当将依赖包的问题解决掉后就可以再一次尝试安装了,按照上面博客里面提到的步骤即可,移动文件时要注意和自己的要适配
当采用指令
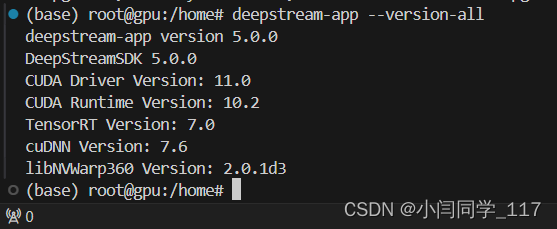
deepstream-app --version-all
可以看到类似如下输出,那么恭喜插件安装的没什么问题了(完成度80%)
当然,在你按照之前的博客运行到
deepstream-app -c source4_1080p_dec_infer-resnet_tracker_sgie_tiled_display_int8.txt
这一步时你可能会出现类似这样的错误
deepstream-app: error while loading shared libraries: libjson-glib-1.0.so.0: cannot open shared object file: No such file or directory
对于这个坑有两种一种直接使用
sudo apt update
sudo apt install libjson-glib-1.0-0
类似这样的命令就可以解决,还有一种类似于下面这个
deepstream-app: error while loading shared libraries: libnvrtc.so.10.2: cannot open shared object file: No such file or directory
当时我在网上找以及chatgpt都给出了看似合理但实施性几乎不可能的方法,无论是创建doker容器或者安装另一个版本的cudatoolkit都不太行,但是在我的系统里面真的没有吗,一篇帖子讲出他可能存在的位置,但我去找发现真的没有,但是想到另一个问题我的cudatoolkit是装载在anaconda里面的啊,虽然确切的位置我不知道,但是在linux里面有一个可以搜索全局的命令啊使用命令如下,全局搜索libnvrtc.so.10.2库
find / -name libnvrtc.so.10.2 2>/dev/null
回头来看因为没有安装在默认路径以至于找了好久找不到,既然找到了之后的事就简单了,创建软连接
ln -s /root/anaconda3/pkgs/cudatoolkit-10.2.89-hfd86e86_1/lib/libnvrtc.so.10.2 /usr/lib/libnvrtc.so.10.2
接下来测试上面博客里面出现的例子,还有一点问题,问题倒也不大就是运行就挂掉了真心搞人心态,输出如下:

day8
耗时1.5h完成deepstream部分总结,接下来改错ing
因为之前的确有长时间工作以至于有点学不进去 ~ 于是乎开摆
day9
沿着之前错误的信息去查看日志(因为太简陋了),搜集资料得到使用命令“export GST_DEBUG=*:3
”(4)得到比较详细的信息如下

于是乎开整呗
好吧好吧今天最大的收获算是将问题具象化,前进的方向有两个
1.使用“cd /opt/nvidia/deepstream/deepstream-5.0/samples/configs/deepstream-app”去到该路径下使用“deepstream-app -c source4_1080p_dec_infer-resnet_tracker_sgie_tiled_display_int8.txt”命令最终报出一堆egl的错
2.进入到deepstream-test1路径下对文件进行修改最终使用“make”指令进行编译使用“./deepstream-test1-app /opt/nvidia/deepstream/deepstream-5.0/samples/streams/sample_720p.h264
”进行测试,但是显然依然有错,错误在于没有找到英伟达相关的解释器
对于进度推进几乎为零,但是有将问题具象化
day 10
历时大概两个小时似乎找见了问题所在,在服务器上面并没有视频解码器但是在deepstream上面的确是要使用这个解码器的当然在英伟达官网上面也有对于此的描述关于链接: 视频解码器对于此的解决方案似乎是将英伟达显卡驱动卸载重装(必须得承认这是一个危险的操作暂时停止尝试听一听学姐的意见)重载驱动命令
sudo rmmod nvidia
sudo modprobe nvidia
一直以来一个问题就是说可行性分析,的确使用deepstream可以做到实时检测但是有一点我当前环境运行在服务器上面有一点值得深思当我尝试deepstream的示例代码总会报出关于egl的错误一开始不明所以后面当我发现说egl是关于图像渲染那么我连个屏都没有怎么渲染😂
另一个问题当我试图运行“/opt/nvidia/deepstream/deepstream-5.0/sources/apps/sample_apps/deepstream-test1”路径下代码也总会报与硬件接口相关错误有一点当我查看deepstream版本号或者相关插件信息时似乎并没有问题~小小的脑袋大大的疑惑
基于此我必须对这个方案重新进行考虑,这真的可行吗,能够完成我的预期吗
补:
要查看更详细的日志信息,您可以尝试以下几种方法:
增加日志级别: 在 DeepStream 应用程序的配置文件中,通常会有一个参数用于指定日志级别,例如 log-level。您可以尝试将日志级别设置为更详细的级别,例如 3 或 4,以便记录更多的详细信息。请注意,设置更高的日志级别可能会导致日志文件变得很大,因此请谨慎使用。
查看系统日志: 您可以查看系统日志文件,通常位于 /var/log 目录下,例如 syslog 或 messages 文件。在启动 DeepStream 应用程序时,可能会记录一些相关的错误或警告信息。
使用 GStreamer 调试信息: DeepStream 应用程序通常使用 GStreamer 库来处理视频流,您可以尝试设置 GStreamer 库的调试环境变量,以记录更详细的 GStreamer 日志信息。您可以使用以下命令设置 GStreamer 调试级别:
export GST_DEBUG=*:<desired_debug_level>
其中 <desired_debug_level> 是您希望设置的调试级别,例如 3 或 4。然后再运行 DeepStream 应用程序,查看输出的调试信息。
查看应用程序输出: 在运行 DeepStream 应用程序时,它通常会输出一些信息到终端。您可以查看这些输出,看是否有任何错误或警告信息。
通过这些方法,您应该能够获取更详细的日志信息,从而更容易地诊断问题所在。















 1615
1615











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









