






ViViT: A Video Vision Transformer
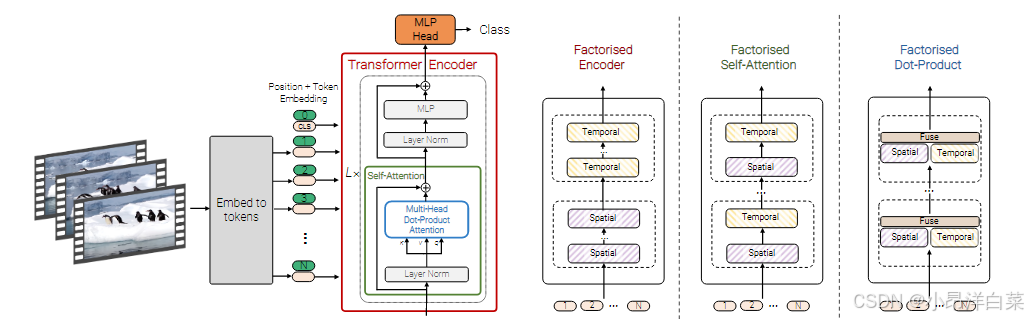
这篇论文提出了 ViViT(Video Vision Transformer),一种基于 Transformer 架构的视频分类模型。与传统的卷积神经网络(CNN)相比,ViViT 采用了自注意力机制来建模视频数据中的时空依赖关系。
-
代码链接:- ViViT GitHub 仓库
这些资源包含了关于 ViViT 模型的详细实现和使用方法。你可以在 GitHub 上找到具体的代码和模型训练细节,也可以通过论文深入了解模型的理论背景和设计细节。
1.Embedding video clips
将视频的时空信息有效地嵌入到 Transformer 中,便于后续的处理和特征提取。具体过程包括以下几个步骤:首先进行嵌入,接着加上位置嵌入,最后通过 reshape 操作将其转换为 Transformer 输入所需的形状。
1.1 Uniform Frame Sampling
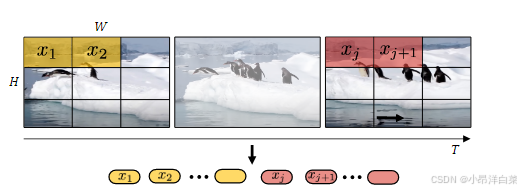
这种方法比较直接,它通过从视频中 均匀采样 n t nt nt 帧来进行令牌化,然后对每帧进行独立的 2D 图像嵌入(类似 ViT 的处理方式)。步骤如下:
- 视频帧采样:从输入视频中均匀地选取 n t nt nt 帧,每一帧代表一个独立的图像。
- 图像嵌入:对每帧图像进行 ViT 中常用的 2D 图像切片(patch)嵌入,即将每一帧分割成大小为 n h × n w nh \times nw nh×nw 的非重叠块,并将每个块展平并线性变换成一个嵌入向量。
- 令牌拼接:将所有采样的帧的嵌入令牌连接在一起,形成一个大的令牌序列。该序列的长度为 n t × n h × n w nt \times nh \times nw nt×nh×nw,即所有视频帧的嵌入令牌被整合在一起传入 Transformer 编码器。
这种方法可以直观地看作是将视频作为一个大 2D 图像输入,并按 ViT 的方式处理每一帧图像。Uniform Frame Sampling 的优点是实现简单、直观,但是它没有融合时空信息,而是依赖 Transformer 层通过自注意力机制在序列中处理时空依赖。
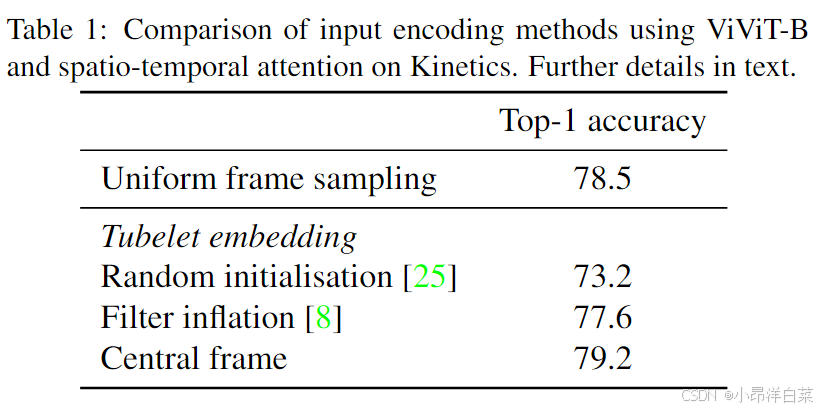
1.2. Tubelet Embedding
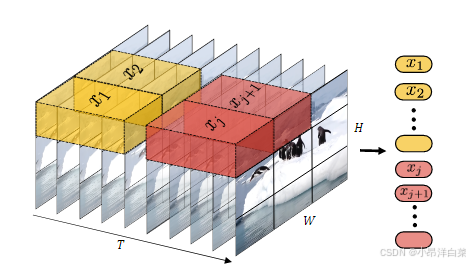
另一种方法是 Tubelet Embedding,它将视频的时空信息进行融合,通过提取视频的 时空 tubelets(时间-空间块)来构建输入。这是 ViT 中 2D 图像嵌入的 3D 扩展,步骤如下:
- 视频块提取:从视频的时空体积(即 T×H×W)中提取 非重叠的时空 tubelets。每个 tubelet 的尺寸为 t × h × w t \times h \times w t×h×w,其中 t t t 表示时间维度, h h h 和 w w w 分别表示空间维度。
- 线性嵌入:每个 tubelet 通过线性变换投影到 R d \mathbb{R}^d Rd 空间,形成一个嵌入向量。这种方式与 3D 卷积非常类似,它将时空信息融合到单一的令牌中。
- 令牌提取:根据 tubelet 的维度 t × h × w t \times h \times w t×h×w,从视频的时间、空间高度和宽度维度中提取多个令牌。每个 tubelet 的大小直接决定了输出令牌的数量。更小的 tubelet 会产生更多的令牌,从而增加计算量。
这种方法与 Uniform Frame Sampling 的区别在于,Tubelet Embedding 在令牌化阶段就已经融合了时空信息,而不是依赖于 Transformer 自注意力机制来融合这些信息。通过将时间和空间的信息直接融合到每个令牌中,模型能够在早期就捕获时空依赖关系。
2.Transformer Models for Video
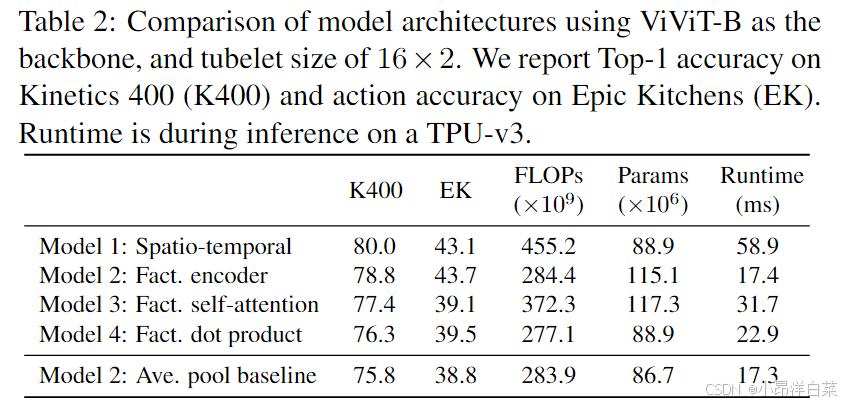
2.1 Model 1: Spatio-temporal attention
在自注意力机制中同时考虑空间维度和时间维度的依赖。将视频输入转化为一系列时空令牌 z 0 z_0 z0,然后将这些令牌通过 Transformer 编码器传递。
例如,如果视频有 T 帧,每帧被分解为 n h × n w nh \times nw nh×nw 个图像块,那么令牌的总数就是 N = T × n h × n w N = T \times nh \times nw N=T×nh×nw。对于每个 Transformer 层,自注意力机制需要计算所有令牌之间的相互作用,这使得计算复杂度为 O ( N 2 ) O(N^2) O(N2)。如果输入视频的帧数 T 很大,这种复杂度会导致计算瓶颈。
2.2 Model 2: Factorised encoder
通过 分解编码器(Factorised Encoder)来高效地处理视频数据中的时空特征。这个模型的核心思想是通过分解自注意力操作来降低计算复杂度,同时保留对时空依赖的建模能力。
空间编码器:首先通过空间编码器计算每个帧的表示。空间编码器是针对每一帧独立操作的,只考虑来自同一帧的空间位置之间的相互关系。经过空间编码器后,会得到每帧的表示 h i ∈ R d h_i \in \mathbb{R}^d hi∈Rd。
时间编码器:接着,空间编码器输出的帧级别表示会被送入时间编码器,时间编码器会建模不同时间步(帧)之间的依赖关系。最终,时间编码器输出的表示会被用于分类任务。
在 Spatio-temporal attention 中,由于计算的是全时空自注意力,计算复杂度是 O ( ( n t × n h × n w ) 2 ) O((nt \times nh \times nw)^2) O((nt×nh×nw)2),即需要处理整个视频序列的所有时间步和空间位置的组合。
而在 Factorised Encoder 中,计算被分解为两个独立的部分:空间自注意力 的复杂度是 O ( ( n h × n w ) 2 ) O((nh \times nw)^2) O((nh×nw)2),只考虑同一时间步内的空间依赖;时间自注意力 的复杂度是 O ( n t 2 ) O(n_t^2) O(nt2),只考虑时间步之间的依赖。
因此,整体复杂度为: O ( ( n h × n w ) 2 + n t 2 ) O((nh \times nw)^2 + n_t^2) O((nh×nw)2+nt2)
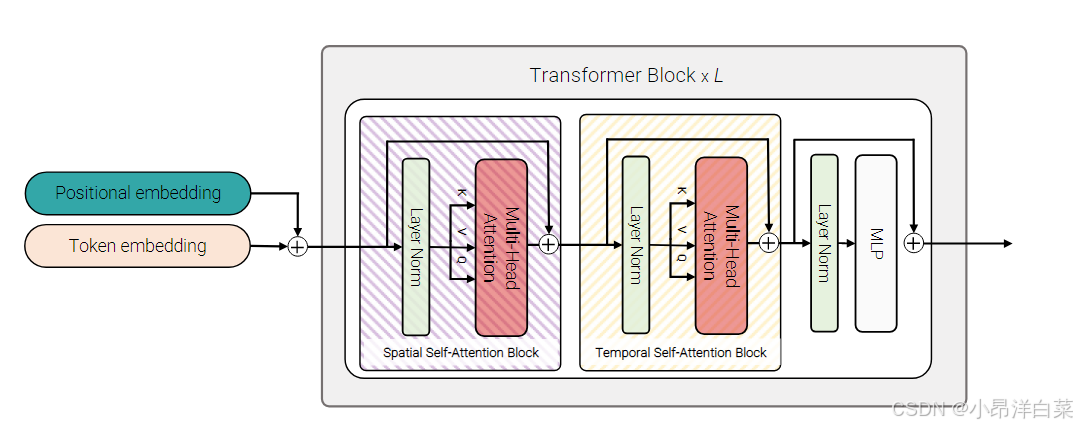
2.3 Model 3: Factorised self-attention
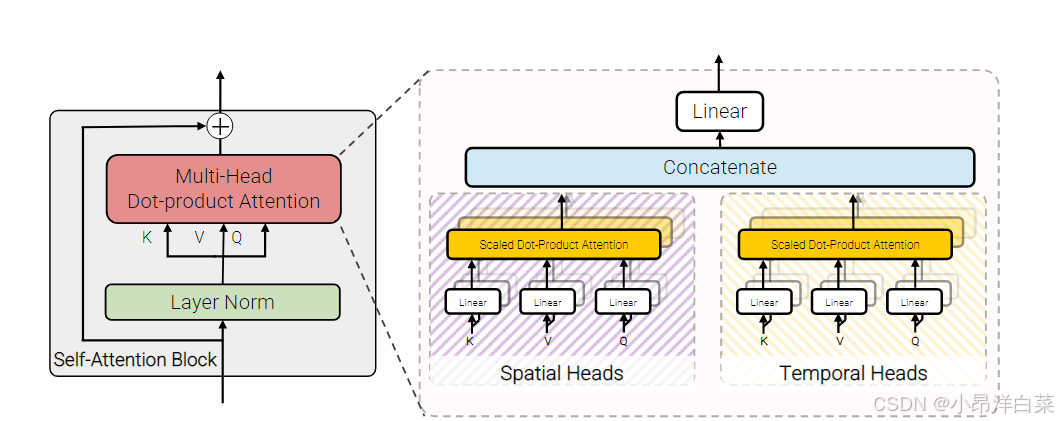
在标准的 ViViT 模型(Model 1)中,多头自注意力(Multi-Head Self-Attention,MSA)操作会在所有输入的令牌(tokens)对之间进行计算,也就是说,每一层都会计算所有空间(图像块)和时间(帧)维度的交互。这种计算方式虽然能捕捉到时空之间的依赖关系,但计算量非常庞大,尤其是在处理视频这种时空数据时,随着输入的帧数和每帧的图像块数增多,计算复杂度急剧上升。为了减少计算量,Model 3 采用了 因式分解(factorisation) 的方式,即将空间和时间自注意力操作拆分开来。具体来说,它将 空间注意力 计算和 时间注意力 计算分别进行,从而减少了每次计算的元素数量,并提高了计算效率。
Model 3的结构与Model 1相似,依然包含相同数量的Transformer层,但与Model 1不同的是,它对每一层的自注意力计算进行了因式分解。其主要分为两个步骤:
-
空间自注意力(Spatial Self-Attention):在这一阶段,所有来自同一时间索引的令牌(即同一帧中的所有图像块)进行自注意力计算。这相当于仅在每一帧内进行自注意力操作。输入的令牌 z s z_s zs会被重塑为一个新的形状: R n t × n h × n w × d R^{nt \times nh \times nw \times d} Rnt×nh×nw×d 转换为 R n t × n h × n w × d R^{nt \times nh \times nw \times d} Rnt×nh×nw×d,然后在空间维度上进行自注意力计算。具体来说,计算空间自注意力之后得到的输出是 y s y_s ys。
KaTeX parse error: \tag works only in display equations
这里, MSA \text{MSA} MSA 是多头自注意力操作, LN \text{LN} LN是层归一化操作。输入令牌 z s z_s zs 经过空间自注意力计算后得到 y s ′ y_s' ys′。
-
时间自注意力(Temporal Self-Attention):接着,进行时间维度上的自注意力计算。在这一步,所有来自同一空间索引的令牌(即来自同一位置的所有时间帧的图像块)进行自注意力计算。这相当于跨帧(时间)进行自注意力计算。输入的令牌 z t z_t zt 会被重塑为一个新的形状: R n h × n w × n t × d R^{nh \times nw \times nt \times d} Rnh×nw×nt×d转换为 R n h × n w × n t × d R^{nh \times nw \times nt \times d} Rnh×nw×nt×d,然后在时间维度上进行自注意力计算。计算完后得到的输出是 y t y_t yt。
KaTeX parse error: \tag works only in display equations
在空间自注意力计算的输出 y s ′ y_s' ys′′的基础上,进行时间自注意力计算,得到 y t ′ y_t' yt′。
2.4 Model 4: Factorised dot-product attention
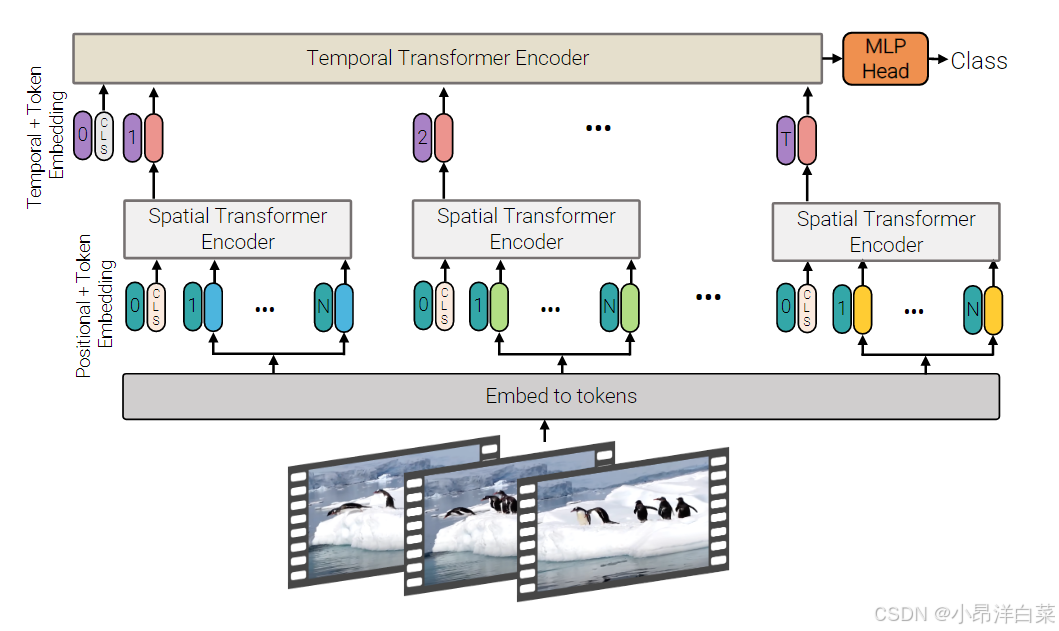
在Model 3 中,空间自注意力和时间自注意力被分开进行计算,首先计算时间自注意力,然后计算空间自注意力。这种方法的优点在于它减少了每次自注意力计算时需要处理的令牌数量,从而降低了计算复杂度。然而,Model 4 进一步改进了自注意力的计算过程,通过 因式分解点积注意力(Factorised Dot-Product Attention)来提高计算效率,特别是在计算注意力权重的过程中。传统的自注意力计算方式(如 Model 1 和 Model 3)会在所有令牌对之间计算点积,计算量较大。而因式分解点积注意力通过将计算过程进一步分解,减少了计算量。
-
时间自注意力(Temporal Self-Attention):
输入令牌 $z_t^{(l)} 会被重塑为 = = 会被重塑为 == 会被重塑为==R^{nh \cdot nw \times nt \cdot d}$==,然后进行 点积注意力 的计算。在计算时,模型会利用因式分解技术,减少计算量。
公式为:
KaTeX parse error: \tag works only in display equations
这里的 Dot-Product Attention 表示的是时间维度上的注意力计算,它只会在每一帧中跨时间维度建模依赖关系。与传统的自注意力计算不同,因式分解点积注意力会对计算进行优化。
-
空间自注意力(Spatial Self-Attention):
对 时间自注意力 计算后的输出 y t ( l ) y_t^{(l)} yt(l),进行空间自注意力计算。首先将输出 y t ( l ) y_t^{(l)} yt(l) 重塑为 R n t × n h ⋅ n w × d R^{nt \times nh \cdot nw \times d} Rnt×nh⋅nw×d,然后在空间维度上进行点积注意力计算。
公式为:
KaTeX parse error: \tag works only in display equations
在空间维度上,点积注意力会计算每帧内不同位置之间的依赖关系。
和 Model 3 一样,最终输出通过前馈神经网络(MLP)进一步处理:
KaTeX parse error: \tag works only in display equations
前馈神经网络对每个位置进行非线性变换,并且通过跳跃连接(residual connection)加以更新。最终的输出 z ( l + 1 ) z^{(l+1)} z(l+1)将传递到下一层的计算中。
3.Initialisation by leveraging pretrained models
如何通过利用预训练的图像模型来初始化视频分类模型,以便更高效地训练。这一部分主要解决了以下几个问题:视频数据集通常缺少与图像数据集相当的标签数据量,这使得从零开始训练大型模型变得非常困难。视频模型的初始化:通过借用图像模型的预训练参数来加速训练,并解决如何初始化不兼容或者未在图像模型中存在的参数。
3.1. 位置嵌入(Positional Embeddings)
Transformer 模型使用位置嵌入来表示令牌的位置信息,在 ViViT 中,这一策略也被沿用到视频序列中。
- 对于图像分类任务,ViT 模型中有一个位置嵌入 ppp 被加到每个输入令牌(如图像的切片)上。然而,在视频分类任务中,输入令牌的数量会增加,因为视频不仅有空间维度(图像的高和宽),还增加了时间维度(视频的帧数)。
- 由于视频模型中的令牌数量是图像模型的 n t nt nt 倍( n t nt nt是视频帧数),因此 位置嵌入需要通过 “时间重复”来初始化,将原本二维的嵌入(来自图像模型)沿着时间维度复制,从而生成 3D 的位置嵌入。具体做法是将图像模型中的位置嵌入 p image p_{\text{image}} pimage 从 R n h × n w × d R^{nh \times nw \times d} Rnh×nw×d 扩展到 R n t × n h × n w × d R^{nt \times nh \times nw \times d} Rnt×nh×nw×d。
3.2. 嵌入权重(Embedding Weights)
ViViT 使用了“管道嵌入”(tubelet embedding)方法来表示视频中的令牌。相比图像模型中的二维卷积嵌入,视频模型需要在三维卷积滤波器上进行初始化。
- 图像模型中的嵌入权重 E image E_{\text{image}} Eimage 是一个二维矩阵( R n h × n w × d R^{nh \times nw \times d} Rnh×nw×d)。
- 视频模型中,嵌入权重 E E E 是一个三维张量( R n t × n h × n w × d R^{nt \times nh \times nw \times d} Rnt×nh×nw×d),这个三维张量表示视频的时空嵌入。
有几种初始化三维卷积滤波器的方法:
-
滤波器扩展(Inflating filters):一种常见的方法是“膨胀”二维卷积滤波器,将其沿着时间维度复制,并对这些复制的滤波器进行平均。例如:
KaTeX parse error: \tag works only in display equations
这里 t 是时间维度(即帧数),这种方法会将每一帧的空间信息复制到所有时间步长上。
-
中心帧初始化(Central Frame Initialisation):另一种初始化方法是通过零初始化所有时间位置的滤波器参数,只有在视频的中心帧上才使用图像模型中的嵌入权重。这意味着,初始化时,卷积滤波器的行为类似于 “均匀帧采样(Uniform Frame Sampling)”,仅在中心帧时获取空间信息:
KaTeX parse error: \tag works only in display equations
这种方法通过让模型初始时只关注中心帧的空间信息,同时使模型在训练过程中学会如何从多个时间帧聚合时序信息。
3.4 Transformer 权重初始化(Model 3 的 Transformer 权重)
Model 3 中的 Transformer 模块与预训练的 ViT 模型有所不同,主要体现在模型中包含了两个多头自注意力(MSA)模块:一个用于空间自注意力,另一个用于时间自注意力。
对于空间自注意力模块,初始化时直接采用预训练的 ViT 模型的参数;对于时间自注意力模块,所有的权重在初始化时被设置为零。这样一来,在初始化时,时间自注意力模块的行为相当于一个残差连接(residual connection),即其输出等于输入。通过这种初始化,模型在训练开始时并没有通过时间自注意力进行计算,而是让时间自注意力的功能在训练中逐渐发挥作用。
4. Empirical evaluation

















 3584
3584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









