







特征重要性排序–Permutation Importance
参考:Permutation Importance | Kaggle
相比于其他衡量特征重要性的方法,Permutation Importance的优点:
- 计算量低
- 广泛使用和容易理解
- 与我们要测量特征重要性的属性一致
Permutation Importance的计算是在模型训练完成后进行的,即,模型参数不再改变。如果我们将验证集中的单独一列的数据进行打乱,并保持其他列和目标值不变,那么,预测打乱后的验证集的结果会怎么变化?

上图示例是将第二列的数据进行shaffle,如果模型预测对该列特征的依赖性很大,那么打乱后,预测精度会受到很大的影响。
具体实施流程:
- 训练模型
- 打乱其中一列的数据,用该数据集进行预测,评估预测精度下降来提现该特征变量的重要性
- 将验证数据集还原,并重复第二步,分析其他特征变量
代码示例:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
data = pd.read_csv('../input/fifa-2018-match-statistics/FIFA 2018 Statistics.csv')
y = (data['Man of the Match'] == "Yes") # Convert from string "Yes"/"No" to binary
feature_names = [i for i in data.columns if data[i].dtype in [np.int64]]
X = data[feature_names]
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state=1)
my_model = RandomForestClassifier(n_estimators=100,
random_state=0).fit(train_X, train_y)
import eli5
from eli5.sklearn import PermutationImportance
perm = PermutationImportance(my_model, random_state=1).fit(val_X, val_y)
eli5.show_weights(perm, feature_names = val_X.columns.tolist())
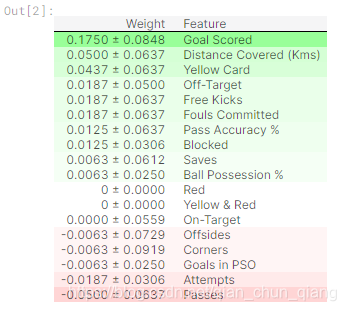
像大部分数据科学中的结果一样,当打乱单个列的时候的结果变化会存在一定随机性,我们通过重复这个过程多次打乱来测量permutation importance计算的随机性大小。
我们通过重复这个过程多次打乱来测量permutation importance计算的随机性大小。
经常会遇到一些负的值,在这种情形下,在打乱(噪声)数据上的预测会得到比真实数据更高精度的结果,该特征的重要性接近于0,但存在一定的机会导致在打乱数据上的预测会更精确。这种情形一般更容易发生在小数据集,因为会有更大几率好运。

















 940
940

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









