







 文章探讨了实时语义分割技术在复杂背景下实现人像分割的应用,重点介绍了BiSeNetV2算法的原理及其在提高分割速度与精度方面的优势。通过Paddle深度学习框架,实现了模型训练、多平台推理部署,包括Python脚本、Django Web服务及C++推理,展示了在自动驾驶、面部分析等领域的广泛应用。
文章探讨了实时语义分割技术在复杂背景下实现人像分割的应用,重点介绍了BiSeNetV2算法的原理及其在提高分割速度与精度方面的优势。通过Paddle深度学习框架,实现了模型训练、多平台推理部署,包括Python脚本、Django Web服务及C++推理,展示了在自动驾驶、面部分析等领域的广泛应用。
目录
4.3.2 基于Paddle Inference的C++推理
一、语义分割概述
图像语义分割是一种将图像分割成一系列具有特定语义类别属性区域的方法,目前已成为当前图像理解分析和计算机视觉 等领 域的热点研究内容。简单举个例子,下图为例:


上边是一张自然街景拍摄的图片,下边是对应的语义分割图。可以看到,分割的结果就是将同类的物体全都用一种颜色标注出来,每一类物体就是一种“语义”,例如图中人是一类语义,马路是一类语义,树是一类语义,电线杆是一类语义,等等。语义分割就是要按照语义类别进行分割。如果两个像素靠的很近,例如图中的人和树,但是它们不属于同一个语义类别,那么语义分割算法就需要将他们分割开来。可以看到,语义分割相比传统的分割添加了语义的概念,它需要算法具备一定的先验知识,大体上“知道”人是什么样子、树是什么样子、马路是什么样子,有了这种先验知识,才能准确的对图像每个像素进行分割(标注)。
如果从分类的角度来看这个问题,那么语义分割可以理解为为图像中的每个像素进行分类,类别就是图像中所有的语义种类(个数)。相比计算机视觉中一般的分类问题,语义分割的难度更大,因为其精度需要精确至像素级别。
语义分割方法按照时间可以大致分为两类:传统方法和深度学习方法。
- 传统方法:主要采用马尔科夫随机场(MRF)和条件随机场(CRF)等方法进行数学建模,方法相对简单,运行速度快。缺点就是缺乏有效的先验知识,分割精度低;
- 深度学习方法:目前主流的语义分割算法都是采用深度学习来实现,较传统算法来说,深度学习方法可以充分利用大样本数据的先验知识得到更佳的分割性能;
语义分割技术可以对整幅图像进行像素级的分析,目前,语义分割已经被广泛应用于自动驾驶、无人机落点判定、地质检测、面部分析、精准农业等场景中。本文将从语义分割角度切入,以人像分割任务为例,详细讲解如何利用语义分割技术实现一款实时视频去背景产品,其核心在于利用语义分割技术实现复杂背景下的人像分割。
本文采用百度开源的Paddle深度学习框架,安装和使用方式可以参照官网执行。之所以采用百度Paddle框架是因为paddle有众多官方维护的CV代码套件,涵盖图像分类、目标检测、语义分割、OCR文字识别、GAN等,这些现成的代码套件可以开箱即用,有比较好的维护,几乎包含当前一系列主流深度学习算法。同时,最新的paddle动态图框架可以让我们像Pytorch一样非常容易的了解算法代码并且能够调试、改动代码。另外,我们训练出来的模型可以方便的使用动态图转静态图功能完成多平台部署。同时,如果部署环境资源受限(例如移动端),paddle也提供了相应的量化裁减工具和轻量级模型转换工具paddle lite,可以方便我们对这些模型进行生产级部署。整体来说,Paddle在国产框架中目前使用量第一,整个生态环境较好,相对其它国产框架更加成熟,即使和tensorflow和pytorch相比也有一定的优势,选择Paddle开发人工智能产品是一个不错的选择。
二、算法原理
目前,很多人像分割模型为了尽可能的提高分割精度,在模型选择上都选择了重量级模型,尽管精度较高,但是不能满足实时性分割要求,例如面向视频的实时背景替换。为了能够达到实时的分割速度,同时保证一定的分割精度,本文实现时以实时语义分割算法为主,借鉴论文BiSeNetV2实现人像分割任务,从而能够从相对复杂背景中分割出人像区域。
2.1 BiSeNetV2算法简述
本文采用BiSeNetV2来实现,考虑到实时性和精度双重要求,BiSeNetV2是一个性价比较高的折中方案。具体速度和精度指标如下图所示:
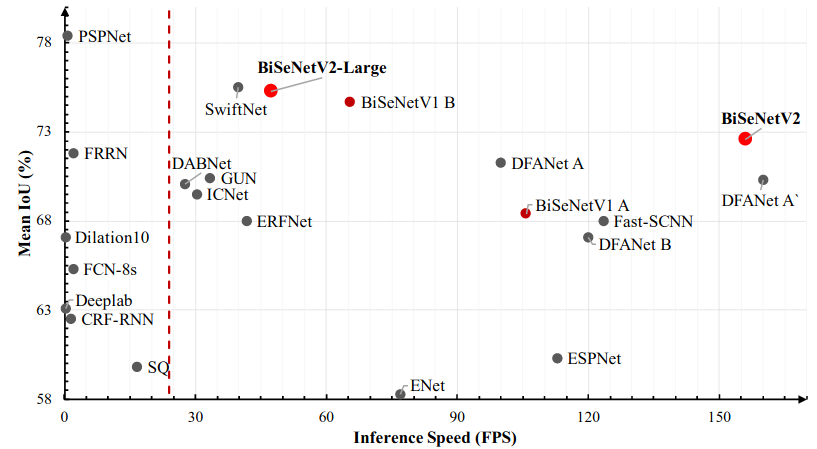
从BiSeNetV2论文中给出的数据来看,对于2048x1024分辨率的图像,其速度在1张GTX1080Ti上可以达到156FPS,当然这个速度需要借助tensorrt框架,但是其强劲的性能还是非常吸引人的。
BiSeNet算法基本原理如下:
(1) 整个网络分成两个分支,分别为语义分支和细节分支,其中语义分支网络层深、通道数窄,这样可以快速实现下采样,获得更多的上下文语义信息,而通道数窄则利于速度的提升。细节分支与之相反,网络层浅、通道数宽,这样可以将注意力集中于局部细节,减少细节的损失。从感性角度分析,这个模型在设计上是非常合理的,即对于语义部分,更应关注上下文语义信息,更应该准确的从宏观上进行类别区分,当然为了提高速度其通道数可以窄一些。对于细节部分,如果使用较深的层数势必会降低特征分辨率,进而丢失细节信息,因此,对于细节部分只需要使用迁层模型即可。在论文中,语义分支的通道数设置为细节分支的倍,
可以设置为1/4,基本结构如下图所示。
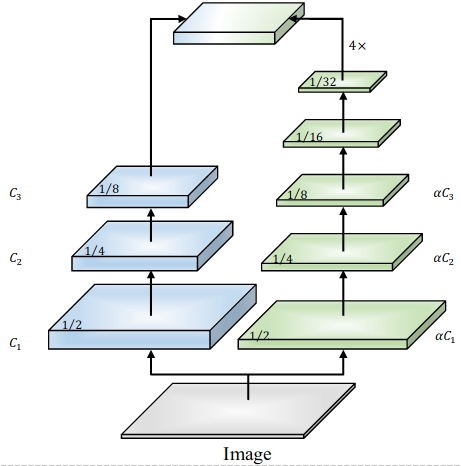
这里需要说明的是上述两个分支中间并没有链接,这个与典型的编解码网络是不同的,这样可以减少内存消耗。
(2)两个分支网络最后通过精心设计的聚合模块进行特征聚合,实现特征互补
BiSeNetV2完整的网络结构如下图所示:
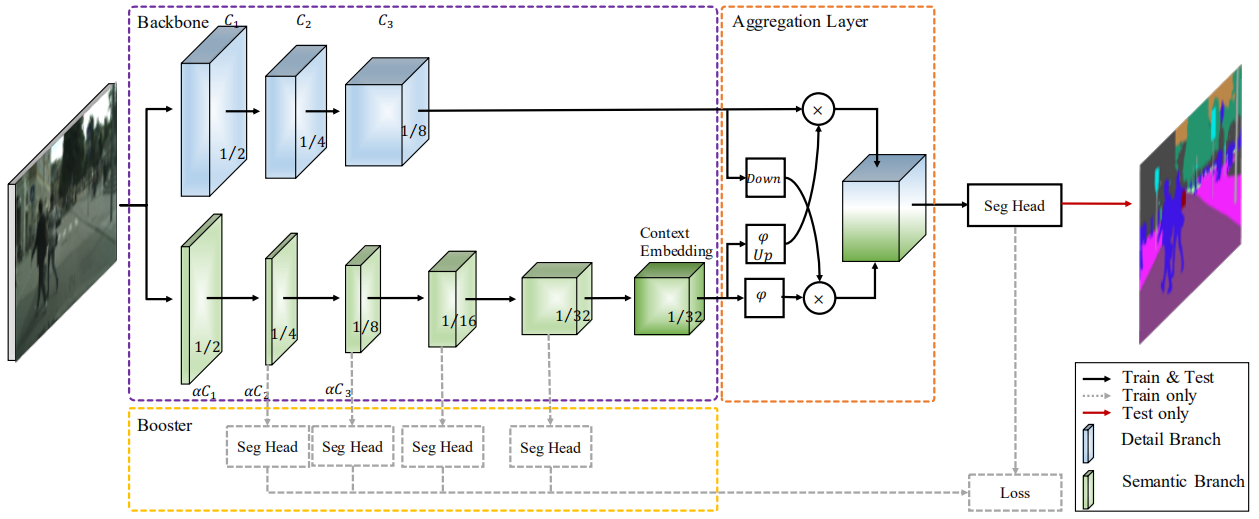
紫色虚框中的是对应的两个分支网络,然后橙色框中的是最后的特征聚合网络,最后通过一个Seg Head分割头得到最终的分割结果。为了进一步提高分割精度,作者额外设计了几个分割头,在黄色框中给出。这些额外的分割头只有在训练的时候会使用,在推理测试的时候是不需要这些分割头的,因此这种操作可以提高最终的推理精度但是又不会降低推理速度,是一个比较好的trick。上图中Down表示下采样,Up表示上采样,表示Sigmoid激活函数。
2.1.1 细节分支
细节分支一共包含3个阶段,每个阶段含有两个或3卷积,其中第一个卷积的滑动步长stride=2,其余卷积滑动步长stride=1,因此,每个阶段都会对图像特征缩小一倍。最后,三阶段结束后输出特征分辨率变为原始图像的1/8。详细的结构参数如下表所示:
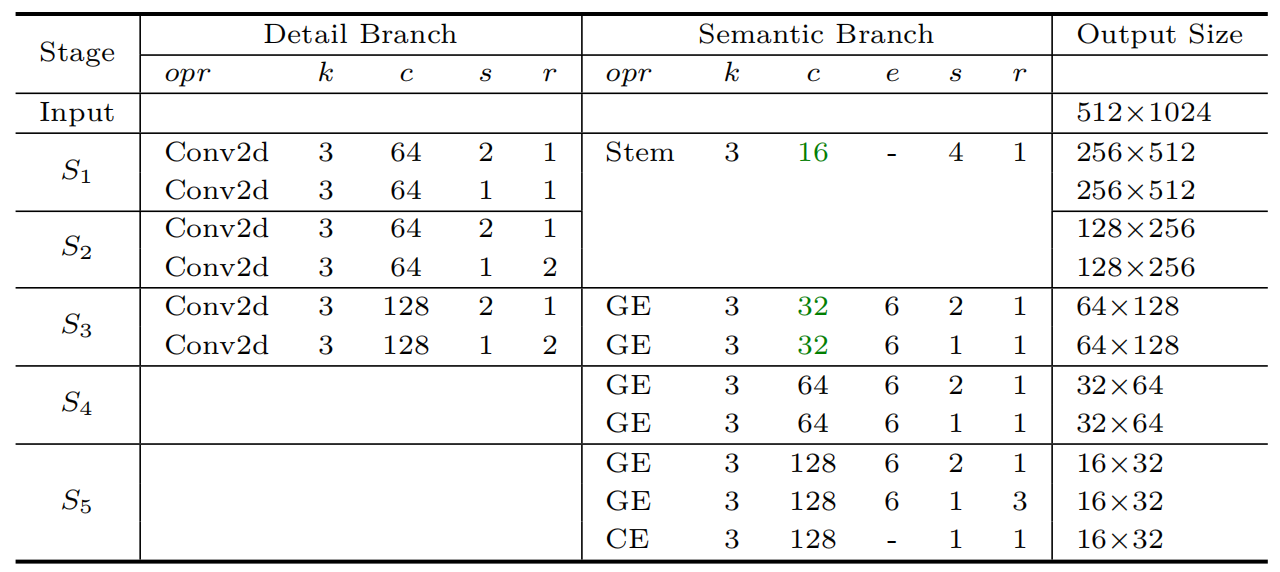
其中k表示核尺寸,c表示输出通道数,s表示滑动步长,r表示重复次数,e表示通道扩展倍数。下面对照动态图代码具体看一下细节分支的实现方式:
class DetailBranch(nn.Layer):
def __init__(self, in_channels):
super().__init__()
C1, C2, C3 = 64, 64, 128
self.convs = nn.Sequential(
# stage 1
layers.ConvBNReLU(3, C1, 3, stride=2),
layers.ConvBNReLU(C1, C1, 3),
# stage 2
layers.ConvBNReLU(C1, C2, 3, stride=2),
layers.ConvBNReLU(C2, C2, 3),
layers.ConvBNReLU(C2, C2, 3),
# stage 3
layers.ConvBNReLU(C2, C3, 3, stride=2),
layers.ConvBNReLU(C3, C3, 3),
layers.ConvBNReLU(C3, C3, 3),
)
def forward(self, x):
return self.convs(x)其中ConvBNReLU表示卷积、BN归一化和Relu激活三个操作。
2.1.2 语义分支
BiSeNetV2在设计语义分支的时候使用了很多特殊的子模块,具体包括3种:Stem Block(Stem)、Gather and Expansion Block(GE)、Context Embedding Block(CE)。下面逐步进行讲解。
(1)Stem Block(Stem)
参考前面的表格,Stem Block跨越两个阶段S1和S2,图像分辨率最终降低为原来的1/4。其基本结构如下图所示:
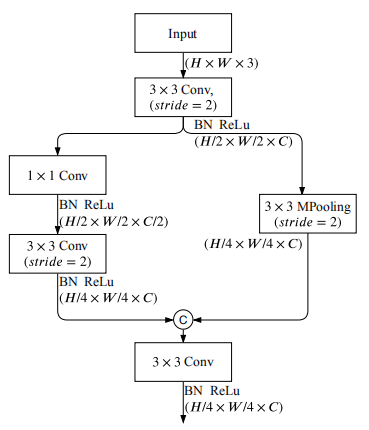
其结构思路是比较清晰的,也是分成两个短分支,一路分支正常的走两个卷积操作,另一路分支走一个最大池化操作,最后两路按通道级联(通道数扩大一倍)再经过一个卷积作为输出。模型代码如下所示:
class StemBlock(nn.Layer):
def __init__(self, in_dim, out_dim):
super(StemBlock, self).__init__()
self.conv = layers.ConvBNReLU(in_dim, out_dim, 3, stride=2)
self.left = nn.Sequential(
layers.ConvBNReLU(out_dim, out_dim // 2, 1),
layers.ConvBNReLU(out_dim // 2, out_dim, 3, stride=2))
self.right = nn.MaxPool2D(kernel_size=3, stride=2, padding=1)
self.fuse = layers.ConvBNReLU(out_dim * 2, out_dim, 3)
def forward(self, x):
x = self.conv(x)
left = self.left(x)
right = self.right(x)
concat = paddle.concat([left, right], axis=1)
return self.fuse(concat)(2)Gather and Expansion Block(GE)
在S3、S4、S5阶段主要使用Gather and Expansion Block(GE)来提取语义特征,图像分辨率进一步降低。这个GE操作主要借鉴MobileNet中的深度可分离卷积depth-wise convolution(关于深度可分离卷积的概念可以参考另一篇博客),相比普通cnn卷积其运算量大幅下降,而模型精度却可以得到有效保证。这里GE模块一共设计了两种结构,一种是针对stride=1的情况,还有一种是针对stride=2的情况。两种结构如下图所示:
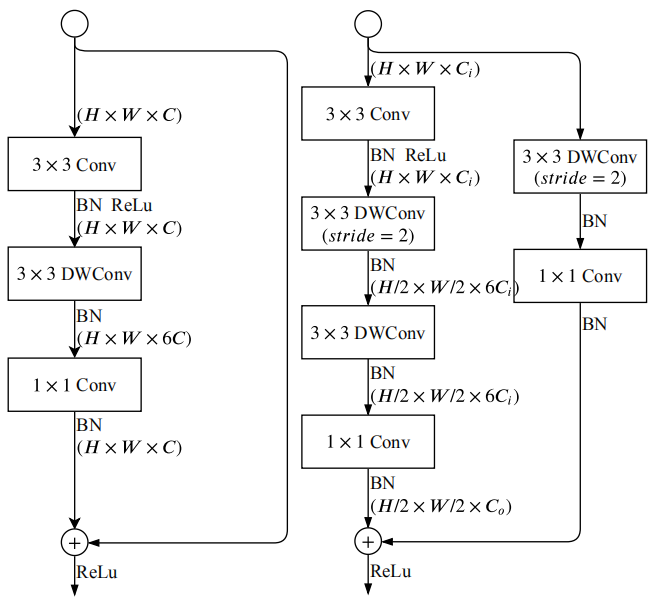
基本思路就是通过3x3卷积来聚合特征,然后使用3x3深度可分离卷积来扩展图像通道,最后再使用1x1卷积进行降维,因此这个子模型名称翻译过来就叫"聚合-扩展"模型。
第一种结构代码如下:
class GatherAndExpansionLayer1(nn.Layer):
"""Gather And Expansion Layer with stride 1"""
def __init__(self, in_dim, out_dim, expand):
super().__init__()
expand_dim = expand * in_dim
self.conv = nn.Sequential(
layers.ConvBNReLU(in_dim, in_dim, 3),
layers.DepthwiseConvBN(in_dim, expand_dim, 3),
layers.ConvBN(expand_dim, out_dim, 1))
def forward(self, x):
return F.relu(self.conv(x) + x)需要注意的是这里并没有像MobileNetV2那样使用ReLu6作为激活函数,这样也方便未来模型的静态导出和转化。
第二种结构代码如下:
class GatherAndExpansionLayer2(nn.Layer):
"""Gather And Expansion Layer with stride 2"""
def __init__(self, in_dim, out_dim, expand):
super().__init__()
expand_dim = expand * in_dim
self.branch_1 = nn.Sequential(
layers.ConvBNReLU(in_dim, in_dim, 3),
layers.DepthwiseConvBN(in_dim, expand_dim, 3, stride=2),
layers.DepthwiseConvBN(expand_dim, expand_dim, 3),
layers.ConvBN(expand_dim, out_dim, 1))
self.branch_2 = nn.Sequential(
layers.DepthwiseConvBN(in_dim, in_dim, 3, stride=2),
layers.ConvBN(in_dim, out_dim, 1))
def forward(self, x):
return F.relu(self.branch_1(x) + self.branch_2(x))(3)Context Embedding Block(CE)
在S5阶段的最后一个部分,使用了Context Embedding Block(CE)。该模块主要是为了进一步获取上下文语义信息,因此采用全局平均池化操作来提取特征。基本结构如下图所示:

值得注意的是该模块并没有改变原特征大小和通道数。模型代码如下:
class ContextEmbeddingBlock(nn.Layer):
def __init__(self, in_dim, out_dim):
super(ContextEmbeddingBlock, self).__init__()
self.gap = nn.AdaptiveAvgPool2D(1)
self.bn = layers.SyncBatchNorm(in_dim)
self.conv_1x1 = layers.ConvBNReLU(in_dim, out_dim, 1)
self.conv_3x3 = nn.Conv2D(out_dim, out_dim, 3, 1, 1)
def forward(self, x):
gap = self.gap(x)
bn = self.bn(gap)
conv1 = self.conv_1x1(bn) + x
return self.conv_3x3(conv1)整体实现还是比较简单的。
从上述语义分支可以看到,该分支整体上使用了多种模块结构,其必要性还需要后期实验验证。如果客户对模型速度非常苛刻的话,那么可以尝试删除其中一部分结构,让整体速度再快一点。
2.1.3 双边特征指导聚合(BGA)
前面介绍了BiSeNet的语义分支和细节分支,最后,需要设计一种结构模型将这两路分支的特征进行合并,实现特征互补融合。BiSeNetV2设计了名为BGA的融合模型,其模型结构如下:
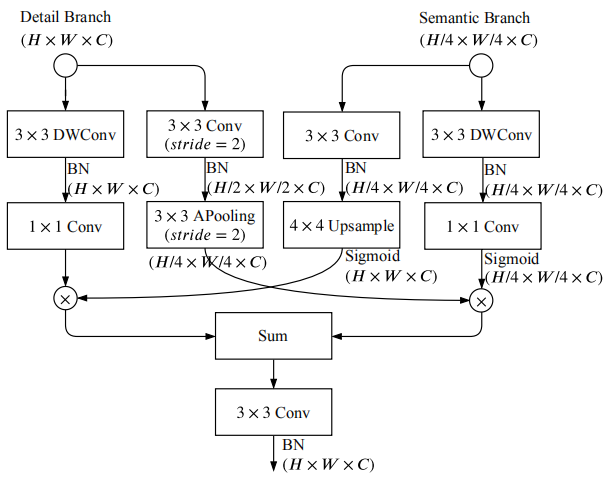
主要思想就是在两个尺度层面实现特征融合,由语义分割特征来指导细节特征。该模型代码如下:
class BGA(nn.Layer):
"""The Bilateral Guided Aggregation Layer, used to fuse the semantic features and spatial features."""
def __init__(self, out_dim, align_corners):
super().__init__()
self.align_corners = align_corners
self.db_branch_keep = nn.Sequential(
layers.DepthwiseConvBN(out_dim, out_dim, 3),
nn.Conv2D(out_dim, out_dim, 1))
self.db_branch_down = nn.Sequential(
layers.ConvBN(out_dim, out_dim, 3, stride=2),
nn.AvgPool2D(kernel_size=3, stride=2, padding=1))
self.sb_branch_keep = nn.Sequential(
layers.DepthwiseConvBN(out_dim, out_dim, 3),
nn.Conv2D(out_dim, out_dim, 1), layers.Activation(act='sigmoid'))
self.sb_branch_up = layers.ConvBN(out_dim, out_dim, 3)
self.conv = layers.ConvBN(out_dim, out_dim, 3)
def forward(self, dfm, sfm):
db_feat_keep = self.db_branch_keep(dfm)
db_feat_down = self.db_branch_down(dfm)
sb_feat_keep = self.sb_branch_keep(sfm)
sb_feat_up = self.sb_branch_up(sfm)
sb_feat_up = F.interpolate(
sb_feat_up,
db_feat_keep.shape[2:],
mode='bilinear',
align_corners=self.align_corners)
sb_feat_up = F.sigmoid(sb_feat_up)
db_feat = db_feat_keep * sb_feat_up
sb_feat = db_feat_down * sb_feat_keep
sb_feat = F.interpolate(
sb_feat,
db_feat.shape[2:],
mode='bilinear',
align_corners=self.align_corners)
return self.conv(db_feat + sb_feat)2.1.4 分割头设计和增强训练策略
分割头主要是为了输出最后的分割结果,其模型结构比较简单,如下图所示:

通过两个卷积完成特征的调整,最后再通过上采样还原成原始的特征大小。代码如下所示:
class SegHead(nn.Layer):
def __init__(self, in_dim, mid_dim, num_classes):
super().__init__()
self.conv_3x3 = nn.Sequential(
layers.ConvBNReLU(in_dim, mid_dim, 3), nn.Dropout(0.1))
self.conv_1x1 = nn.Conv2D(mid_dim, num_classes, 1, 1)
def forward(self, x):
conv1 = self.conv_3x3(x)
conv2 = self.conv_1x1(conv1)
return conv2需要注意,在BiSeNetV2的训练阶段,作者提出了利用多个分割头嵌入在语义分支的不同层来增强训练,各个分割头的输出结果一起作为损失函数来指导训练,在推理时则去除这些多余的分割头。这样可以在训练的时候更多的利用语义分割信息指导训练向更优的结果靠拢,同时在推理时几乎不降低推理速度。这种增强trick在实际使用时往往会有一定的精度提升。
2.2 BiSeNetV2完整模型
汇总前面讲述的各个子模型结构,下面给出BiSeNetV2完整的模型代码:
class BiSeNetV2(nn.Layer):
"""
The BiSeNet V2 implementation based on PaddlePaddle.
The original article refers to
Yu, Changqian, et al. "BiSeNet V2: Bilateral Network with Guided Aggregation for Real-time Semantic Segmentation"
(https://arxiv.org/abs/2004.02147)
Args:
num_classes (int): The unique number of target classes.
lambd (float, optional): A factor for controlling the size of semantic branch channels. Default: 0.25.
pretrained (str, optional): The path or url of pretrained model. Default: None.
"""
def __init__(self,
num_classes,
lambd=0.25,
align_corners=False,
pretrained=None):
super().__init__()
C1, C2, C3 = 64, 64, 128
db_channels = (C1, C2, C3)
C1, C3, C4, C5 = int(C1 * lambd), int(C3 * lambd), 64, 128
sb_channels = (C1, C3, C4, C5)
mid_channels = 128
self.db = DetailBranch(db_channels)
self.sb = SemanticBranch(sb_channels)
self.bga = BGA(mid_channels, align_corners)
self.aux_head1 = SegHead(C1, C1, num_classes)
self.aux_head2 = SegHead(C3, C3, num_classes)
self.aux_head3 = SegHead(C4, C4, num_classes)
self.aux_head4 = SegHead(C5, C5, num_classes)
self.head = SegHead(mid_channels, mid_channels, num_classes)
self.align_corners = align_corners
self.pretrained = pretrained
self.init_weight()
def forward(self, x):
dfm = self.db(x)
feat1, feat2, feat3, feat4, sfm = self.sb(x)
logit1 = self.aux_head1(feat1)
logit2 = self.aux_head2(feat2)
logit3 = self.aux_head3(feat3)
logit4 = self.aux_head4(feat4)
logit = self.head(self.bga(dfm, sfm))
logit_list = [logit, logit1, logit2, logit3, logit4]
logit_list = [
F.interpolate(
logit,
x.shape[2:],
mode='bilinear',
align_corners=self.align_corners) for logit in logit_list
]
return logit_list上述模型在输出时输出了5个分割头的结果,组成了一个分割图像列表,在训练的时候会全部用到这5个结果,在推理的时候只取第一个。
三、训练
3.1 准备开发环境
本文训练部分全部采用Python代码,Python版本为3.6.9,操作系统为Ubuntu 18.04,使用两块英伟达显卡GeForce GTX 1080 Ti进行分布式训练。为了方便后续PC端C++集成,cuda版本为10.0,cudnn版本为7.6(这个版本Paddle官方有提供对应的编译好的C++预测库)。如果读者想要运行本文代码,请按照上述配置安装python、cuda和cudnn。
本文训练代码采用百度Paddle框架,版本为最新的动态图版本PaddlePaddle2.0.0-rc1,安装方式可以参照官网执行。模块代码主要基于paddleseg语义分割库,为了使用该语义分割库,需要使用下述命令安装一下:
pip install paddleseg然后再把本文提供的代码下载下来即可开始下面的训练和推理。
3.2 数据集
3.2.1 数据集介绍
本文采用爱分割提供的人像分割数据集来训练和测试。该数据集总共包含34425张图像,每张图像尺寸均已调整为600x800,并且同时提供对应的groundtruth。部分样例如下图所示:
原图:
groundtruth:

从实际观测效果来看,该数据集的alpha图标注并不精确,尽管如此,我们还是可以用它来训练一个较好的人像语义分割模型。需要注意的是该数据集的标注形式并不是以常见的alpha通道图给出,而是直接给出了抠图前景。我们实际的任务是需要将数据集的label图像制作成只有0和1两个值图,因此在处理该数据集时需要先将alpha通道提取出来,然后进行二值分割即可,分割阈值可以设置为50。本文为了方便各位读者,已经将数据集二值分割完毕,效果如下所示:
原图:

label图:

这里需要注意的是,为了能够直观的看到人像前景分割效果,在数据处理时将灰度大于50的值全部设置为255,而小于50的全部设置为0,即整个图像只有0和255两种值,这与paddleseg需要的只有0、1两种标签的数据集不一致。因此还要对数据标签进行转化。
3.2.2 标签掩码图转换
首先在data目录下新建ai_fen_ge文件夹用于存放爱分割数据集,然后在该文件夹下存放img和gt子文件夹,分别存放原始png图像和对应的真值掩码图。下面要做的第一件事就是将gt中的真值掩码图进行转换,转换结果存放在同目录下名为label的子文件夹中。转换脚本如下:
import os
import cv2
import random
img_folder='img'
gt_folder='gt'
label_folder='label'
fileNameLst=os.listdir(img_folder)
random.shuffle(fileNameLst)
img_index=1
for i in range(len(fileNameLst)):
if(os.path.splitext(fileNameLst[i])[1]=='.png'):
# 读取gt图像
label = cv2.imread(os.path.join(gt_folder,fileNameLst[i]),cv2.IMREAD_GRAYSCALE)
label[label<50]=0
label[label>=50]=1
num0=sum(sum(label==0))
num1=sum(sum(label==1))
if (num0+num1) != label.shape[0]*label.shape[1]:
print('当前转化出错')
break
# 图像保存
labelpath=os.path.join(label_folder,fileNameLst[i])
cv2.imwrite(labelpath,label)
print('当前完成第 '+str(img_index)+' 张图片')
img_index=img_index+1转换完成以后再看转化的数据标签,会有一个问题出现。因为标签图中只有0和1两个值,在灰度呈现上因值太小无法直观的观察转换结果,这里我们可以采用paddle之前提供的一个脚本,将这些标签图像再转化成可以直接观看的彩色标签图,而这些彩色标签图也是可以直接被paddleseg正确读取的。
在当前文件夹下再创建1个文件夹名为colorlabel,然后使用脚本gray2pseudo_color.py来进行转换,输入命令如下:
python gray2pseudo_color.py label colorlabel转换结果如下图所示:

通过上图可以比较直观的观察标签结果。
3.2.3生成训练、验证列表文件
paddle动态图和pytorch很类似,在读取文件时为了方便后面分布式训练,可以先将图片路径和对应的标签路径分别写入txt文件中,后面读取时根据这个txt文件来定位图像位置。在生成txt时即可指明训练集和验证集。
因为爱分割数据集样本比较多,共34425张,这里将其中的30000张取出用于训练,余下的4425张用于验证。完整转换脚本如下:
import os
import cv2
import random
img_folder = 'img'
label_folder = 'colorlabel'
trainlst = 'train_list.txt'
vallst = 'val_list.txt'
# 获取文件夹内文件名
filenamelst = os.listdir(img_folder)
random.shuffle (filenamelst)
trainnamelst = filenamelst[0:30000]
valnamelst = filenamelst[30000:]
index = 1
# 写入训练样本文件
f=open(trainlst, 'a', encoding='utf-8')
for i in range(len(trainnamelst)):
# 判断当前文件
imgname = trainnamelst[i]
imgpath = img_folder + '/' + imgname
img = cv2.imread(imgpath, cv2.IMREAD_COLOR)
if img is None:
print("当前图像出错")
print(imgpath)
break
name = imgname[15:]
labelpath = label_folder + '/' + imgname
label = cv2.imread(labelpath, cv2.IMREAD_GRAYSCALE)
if label is None:
print("当前图像出错")
print(labelpath)
break
#写入lst文件
text = imgpath + ' ' + labelpath + '\n'
f.write(text)
print('写完第 '+str(index)+' 张图片')
index=index+1
f.close()
# 写入验证样本文件
f=open(vallst, 'a', encoding='utf-8')
for i in range(len(valnamelst)):
# 判断当前文件
imgname = valnamelst[i]
imgpath = img_folder + '/' + imgname
img = cv2.imread(imgpath, cv2.IMREAD_COLOR)
if img is None:
print("当前图像出错")
print(imgpath)
break
name = imgname[15:]
labelpath = label_folder + '/' + imgname
label = cv2.imread(labelpath, cv2.IMREAD_GRAYSCALE)
if label is None:
print("当前图像出错")
print(labelpath)
break
#写入lst文件
text = imgpath + ' ' + labelpath + '\n'
f.write(text)
print('写完第 '+str(index)+' 张图片')
index=index+1
f.close()
print('全部完成')最终在ai_fen_ge目录下生成了train_list.txt和val_list.txt,其中每个txt的每一行同时指明了图像路径和对应的标签路径(中间用空格隔开)。最终的目录结构如下图所示:

最后说明以下,之所以采用上面的数据集格式是因为paddleseg套件对于每个数据集都是按照这个格式来存储和读取的,以后有类似需求的时候可以按照上面数据集的处理方法简单修改就可以无缝衔接后面的训练步骤了。
3.3 训练
paddleseg套件对每个数据集的加载处理都放在了一个单独的文件中,具体可以查看paddleseg/datasets目录下,如下所示:

所以为了能够正常的训练,我们也需要仿照其中的opti_disc_seg.py文件,创建一个单独的ai_fen_ge.py文件,内容如下:
import os
from .dataset import Dataset
from paddleseg.utils import seg_env
from paddleseg.cvlibs import manager
from paddleseg.transforms import Compose
@manager.DATASETS.add_component
class AiFenGe(Dataset):
"""
爱分割数据集
Args:
transforms (list): Transforms for image.
dataset_root (str): The dataset directory. Default: None
mode (str, optional): Which part of dataset to use. it is one of ('train', 'val', 'test'). Default: 'train'.
edge (bool, optional): Whether to compute edge while training. Default: False
"""
def __init__(self,
dataset_root=None,
transforms=None,
mode='train',
edge=False):
self.dataset_root = dataset_root
self.transforms = Compose(transforms)
mode = mode.lower()
self.mode = mode
self.file_list = list()
self.num_classes = 2
self.ignore_index = 255
self.edge = edge
if mode not in ['train', 'val', 'test']:
raise ValueError(
"`mode` should be 'train', 'val' or 'test', but got {}.".format(
mode))
if self.transforms is None:
raise ValueError("`transforms` is necessary, but it is None.")
if not os.path.exists(self.dataset_root):
raise Exception("当前数据集目录不存在\\n")
if mode == 'train':
file_path = os.path.join(self.dataset_root, 'train_list.txt')
elif mode == 'val':
file_path = os.path.join(self.dataset_root, 'val_list.txt')
else:
file_path = os.path.join(self.dataset_root, 'test_list.txt')
with open(file_path, 'r') as f:
for line in f:
items = line.strip().split()
if len(items) != 2:
if mode == 'train' or mode == 'val':
raise Exception(
"File list format incorrect! It should be"
" image_name label_name\\n")
image_path = os.path.join(self.dataset_root, items[0])
grt_path = None
else:
image_path = os.path.join(self.dataset_root, items[0])
grt_path = os.path.join(self.dataset_root, items[1])
self.file_list.append([image_path, grt_path])
上述文件基本上只需要参照optic_disc_seg.py文件即可,修改对应的类名就好了。paddleseg套件拥有一套比较完善的数据训练、处理框架,按照它的框架修改对应的关键代码就可以实现自己数据集的训练。有兴趣的读者可以自行完整的阅读paddleseg的代码,由于采用了动态图框架,因此可以方便的断点调试代码,理解整体的数据处理流程。
接下来定义一份配置文件,具体的在configs/quick_start目录下面创建1个名为bisenet_aifenge_320x320_3k.yml的配置文件,具体内容如下:
batch_size: 16
iters: 100000
train_dataset:
type: AiFenGe
dataset_root: data/ai_fen_ge
transforms:
- type: Resize
target_size: [320, 320]
- type: RandomHorizontalFlip
- type: Normalize
mode: train
val_dataset:
type: AiFenGe
dataset_root: data/ai_fen_ge
transforms:
- type: Resize
target_size: [320, 320]
- type: Normalize
mode: val
optimizer:
type: sgd
momentum: 0.9
weight_decay: 4.0e-5
learning_rate:
value: 0.01
decay:
type: poly
power: 0.9
end_lr: 0
loss:
types:
- type: CrossEntropyLoss
coef: [1, 1, 1, 1, 1]
model:
type: BiSeNetV2
num_classes: 2
pretrained: Null
上述配置文件有些关键参数需要说明,其中所有的图像大小统一到320x320进行训练和评估,目标类别是2类
最后在paddleseg/datasets目录下,修改__init__.py文件,导入AiFenGe数据处理类:
from .ai_fen_ge import AiFenGe本文使用2块Nvidia 1080Ti显卡进行训练,具体执行命令如下所示:
export CUDA_VISIBLE_DEVICES=0,1
python -m paddle.distributed.launch train.py \
--config configs/quick_start/bisenet_aifenge_320x320_3k.yml \
--do_eval \
--use_vdl \
--save_interval 5000 \
--save_dir output总共耗时约8小时,训练过程如下所示:
由于在训练过程中开启了VDL,因此可以使用VDL工具查看训练曲线等,在终端中输入命令:
visualdl --logdir output/效果如下图所示:

接下来就可以在浏览器中输入http://localhost:8040来查看曲线图:
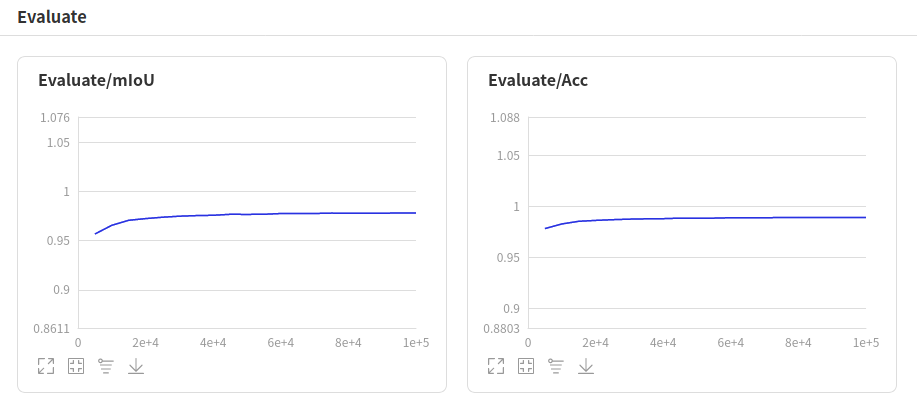
根据上述曲线图,可以看到在接近于60000次迭代的时候已经接近收敛,mIoU涨幅不大了。最终迭代100000次,最好的mIoU=0.9781。训练出来的动态图模型大小为15.2M。
四、推理部署
本节开始阐述算法推理部署环节,通过深度学习训练出来的模型最终只有结合实际产品需要进行推理部署才能真正发挥人工智能的作用。目前,深度学习推理部署的方式大致有5种:
(1) Python脚本推理部署:使用单一python脚本进行推理,在脚本里面开个for循环不断处理图片即可。这种部署方式是最简单的,不需要对模型进行转换,只需要按照训练环境要求进行配置即可开始模型推理。
(2) 基于http的Web服务器推理部署:将模型调用脚本嵌入于web服务器中,所有请求都用http的形式将图像上传到web服务器,服务器处理完每个请求再返回结果。这种方式对用户客户端要求最低,基本不需要改动用户客户端即可实现人工智能应用,所有的环境配置、计算资源全部在web服务器上实现,部署简单,调用方便,训练完成后基本就可以直接进行推理,不需要对模型进行转换操作。但是这种方式也有个很明显的弊端,就是对服务器的计算资源要求较高,并发访问请求比较多时容易造成服务器卡顿甚至奔溃,并且以http网络访问的形式本身有一定的延迟,不适合在线实时任务。
(3) PC客户端推理部署:基于深度学习的PC客户端程序开发一般在工业质检领域用的比较多,给一台工控机配上一块显卡即可进行深度学习推理,利用深度学习进行赋能,可以很大程度上改善传统算法的精度问题。一般情况下为了效率和脱离python环境需要,PC桌面程序开发(C#、MFC或者QT界面框架)会采用C++语言,因此需要对训练出来的模型进行动转静操作,同时要使用C++来加载和推理模型。这种部署模型好处就在于方便程序移植,并且由于算法采用C++进行推理,速度快并且安全性高(Python是明码可见的,C++是要先编译成二进制语言的,因此C++程序更不容易被破译),前提是对C++要比较了解。
(4) 移动端推理部署:现在智能手机非常普及,而且成本很低,很自然的,可以在移动手机上运行一些轻量级的深度学习算法来获得较好的用户体验,例如手机端美颜、基于人脸关键点检测的特效等。一般情况下我们训练出来的深度学习模型都比较重,往往需要对模型进行量化、裁减、剪枝等操作才能获得适合手机端部署的模型,当然,很多深度学习框架配备了自动模型轻量化工具,例如tensorflow lite或者paddle lite等。基于移动端的深度学习部署也是当前一大热点和难点,要有一定的安卓或者iOS开发基础。
(5) 嵌入式推理部署(边缘计算):考虑到实际生产部署的成本问题(毕竟GPU显卡比较贵),以及各种场景的小型化、低功耗需求,基于嵌入式的深度学习边缘部署方案相继被提出,这也是现在最热门的深度学习应用方向:边缘计算。通过边缘计算设备,你就可以在小型机器人上部署高精尖的深度学习模型,可以在工业质检领域用最节省的成本运行高精度的质检模型。当然,由于嵌入式设备资源有限,其开发有一定的难度,在所有部署方案中也是最考验开发者能力的。现在比较流行的边缘设备包括英伟达Jetson系列、百度Edgeboard系列、树莓派等,其中如果想在树莓派上运行深度学习模型可能还需要再配备类似USB的神经计算棒。边缘计算是目前所有部署方案中难度最高的,需要掌握多种框架和语言,需要较好的模型修改能力(有些算子在边缘设备上不支持)。
本节内容以前面训练出来的人像分割模型为例子,详细阐述各个部署方案。使用的是paddle2 rc版本,cuda10.0,cudnn7.6,其它配置具体参见每节部署内容。
4.1 Python脚本推理
4.1.1 单样本测试
paddleseg套件提供了方便的predit.py文件用于执行预测,具体使用下面的命令即可:
python predict.py \
--config configs/quick_start/bisenet_aifenge_320x320_3k.yml \
--model_path output/iter_100000/model.pdparams \
--image_path data/ai_fen_ge/test_img \
--save_dir output/result其中test_img是从网上下载的部分个人自拍照,都是上半身照片,背景不一致。预测结果存放在output/result目录下面,并且为了能够方便的看出分割效果,paddleseg已经将预测掩码图与原图进行了合成,偏绿色部分即为预测区域,偏紫色部分即为背景区域。部分测试效果如下所示:
















从上图中可以看到,整体分割效果还可以,没有出现大面积的误判,仅仅在局部细节处例如发丝部分处理的不好,但是这个效果是可以说的通的,毕竟我们使用的爱分割训练数据集精度不高,并且我们采用的是语义分割模型,并不是彻底的抠图模型。对于实时语义分割模型来说,这个效果本身已经比较好了。后续如果想更进一步,那么可以级联一个MNet模型用于精细抠图,后面我会再开博文针对这个问题继续改进。
根据测试,每张图像平均耗时约40ms,能够满足实时分割的要求。
由于predit.py文件封装的比较厉害,下面我们对其进行简化,使得后面我们能够更加自由的使用Python进行动态图模型预测。具体的,在项目根目录下(即和train.py同一目录)新建一个脚本文件test.py,内容如下:
#导入第三方库
import cv2
import numpy as np
import paddle
import paddle.nn.functional as F
#导入自定义库
from paddleseg.models import BiSeNetV2
#参数设置
im_path='data/ai_fen_ge/test_img/1.jpg'
model_path='output/iter_100000/model.pdparams'
crop_size=(320,320)
mean=(0.5, 0.5, 0.5)
std=(0.5, 0.5, 0.5)
num_class=2
#加载模型
model = BiSeNetV2(num_class)
para_state_dict = paddle.load(model_path)
model.set_dict(para_state_dict)
model.eval()
#开始推理
with paddle.no_grad():
#读取图像
im = cv2.imread(im_path)
ori_shape = im.shape[:2]
#图像预处理
im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
im = cv2.resize(im, crop_size, cv2.INTER_LINEAR)
im = im.astype(np.float32, copy=False) / 255.0
im -= mean
im /= std
#转换成4通道张量格式
im = np.transpose(im, (2, 0, 1))
im = im[np.newaxis, ...]
im = paddle.to_tensor(im)
#模型推理
logits = model(im)
logit = logits[0]
pred = paddle.argmax(logit, axis=1, keepdim=True, dtype='int32')
pred = F.interpolate(pred, ori_shape, mode='nearest')
#二值掩码图像保存
pred = paddle.squeeze(pred)
pred = pred.numpy().astype('uint8')*255
cv2.imwrite('output/result/result.jpg', pred)
#与新背景合成
im = cv2.imread(im_path)
bg=cv2.imread('data/ai_fen_ge/bg.png')
bg=cv2.resize(bg, (ori_shape[1],ori_shape[0]), cv2.INTER_LINEAR)
alpha=cv2.cvtColor(pred,cv2.COLOR_GRAY2BGR)
alpha_f = alpha / 255.
comp = im * alpha_f + bg * (1. - alpha_f)
cv2.imwrite('output/result/comp.jpg', comp.astype(np.uint8))上述代码比较干净,已经将各个封装的关键代码抽取了出来,其中需要注意参数设置部分,需要根据具体的任务配置文件来修改这些参数。上述代码结构比较简单,只对一张图像进行推理,由于是两分类任务,因此推理结果用二值化的掩码图来表示,最后,做了一下拓展,将分割出来的前景人物和新背景图进行合成,最终效果如下图所示:




从左到右依次为:原始图、二值掩码图、新背景图、新合成图
从整体效果上看,分割效果还是相对可以的。下面就可以根据这个简单的python脚本展开一些应用,比如视频实时替换,具体见下一小节。
4.1.2 基于视频的实时背景替换
目前,视频会议在人们的工作和个人生活中变得越来越重要。在视频会议里通过人像分割实时背景替换,可以有效保护视频会议者的隐私,同时,也是一项有趣的体验。本小节我们就来实现一下这个功能。具体执行比较简单,只需要通过opencv实时的捕获USB摄像头,然后将每张图像用前面的人像分割模型进行分割再完成新背景合成即可。
完整代码如下:
#导入第三方库
import cv2
import numpy as np
import paddle
import paddle.nn.functional as F
#导入自定义库
from paddleseg.models import BiSeNetV2
#参数设置
im_path='data/ai_fen_ge/test_img/1.jpg'
model_path='output/iter_100000/model.pdparams'
crop_size=(320,320)
mean=(0.5, 0.5, 0.5)
std=(0.5, 0.5, 0.5)
num_class=2
#加载模型
model = BiSeNetV2(num_class)
para_state_dict = paddle.load(model_path)
model.set_dict(para_state_dict)
model.eval()
#开始捕获摄像头
cap = cv2.VideoCapture(0)
with paddle.no_grad():
while(1):
# 获取图像
ret, orgimg = cap.read()
im=orgimg.copy()
ori_shape = im.shape[:2]
#图像预处理
im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
im = cv2.resize(im, crop_size, cv2.INTER_LINEAR)
im = im.astype(np.float32, copy=False) / 255.0
im -= mean
im /= std
#转换成4通道张量格式
im = np.transpose(im, (2, 0, 1))
im = im[np.newaxis, ...]
im = paddle.to_tensor(im)
#模型推理
logits = model(im)
logit = logits[0]
pred = paddle.argmax(logit, axis=1, keepdim=True, dtype='int32')
pred = F.interpolate(pred, ori_shape, mode='nearest')
#二值掩码图像保存
pred = paddle.squeeze(pred)
pred = pred.numpy().astype('uint8')*255
#与新背景合成
im=orgimg.copy()
bg=cv2.imread('data/ai_fen_ge/video_bg.png')
bg=cv2.resize(bg, (ori_shape[1],ori_shape[0]), cv2.INTER_LINEAR)
alpha=cv2.cvtColor(pred,cv2.COLOR_GRAY2BGR)
alpha_f = alpha / 255.
im = im * alpha_f + bg * (1. - alpha_f)
# 显示
cv2.imshow("capture", im.astype(np.uint8))
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 结束释放资源
cap.release()
cv2.destroyAllWindows() 我的摄像头输出分辨率是480X640,因此找了1张基本同样长宽比的图像作为背景图。
原始背景图像如下所示:
与新背景合成视频如下所示:
视频合成
在背景相对比较简单的场景下,这种实时替换效果还是可以的。另外,从帧率上来看,还是比较快的,因此这也留下了改进空间,如果要开发实际的产品,那么一方面可以降低GPU性能(成本就可以下降),另一方面可以对BiSeNetV2算法进一步减少通道,降低模型运算量。
4.2基于Django的线上Web部署
使用Web方式部署深度学习模型也是比较常见的一种部署方式。一般情况下,我们可以自由的对Web服务器进行环境配置,在上面搭建完整的paddle动态图推理环境并开启http api服务,然后所有的终端都通过http api将需要推理的图像发送至服务器进行推理,推理结果再由web返回给各个终端。因此,这种方式对于终端来说是最方便的,它不要做任何的软硬件改造。
本小节我们并不采用paddle现成的web部署方案paddle serving,主要原因在于如果当预测模型需要对图像进行一些预处理操作的时候,paddle serving需要用户额外安装一个客户端来实现这些预处理操作,这在很多实际应用场景中是不合适、不够用的。另一方面,完全使用paddle serving也不利于我们对整个的部署环境进行把控。真正产品级部署的时候我们还是希望能够全方位的把握当前web运行状态,即使出问题了也能够快速定位和寻找解决方案。
本小节我们采用纯python语言开发的web框架django来实现。这里需要注意,一般网上教程更多采用flask来讲解,其本质是一样的,flask更精炼、更适合微服务部署,而django现成的web轮子多,如果是构建一个完整的web项目的话建议还是用django更好。当然,不管是django还是flask,其核心都是用python开发的,对python具有天然的支持性。
本节内容使用windows 10系统,Web框架使用django 2.2.4。paddle还是使用最新的2.0.0版本。需要注意,前面的内容都是在Ubuntu上训练和实现的,从本小节开始,都在Windows平台上操作。
4.2.1 简单部署
4.2.1.1 环境安装
首先安装python3.7,然后安装英伟达cuda和cudnn,版本为cuda10.0和cudnn7.6.5。这里cuda版本强烈建议使用cuda10.0,这是为了后面能够和嵌入式设备统一(在jetson上只提供了cuda10.0对应的预测库)。
接下来在windows上安装paddle2.0.0,具体安装方式可以参考官网教程。选择好版本后就可以使用它的推荐命令进行安装:
由于需要使用opencv进行图像加载、保存等操作,因此安装opencv:
pip install opencv_python为了在windows系统上使用paddleseg,还需要安装pip install filelock:
pip install filelock最后安装django:
pip install django==2.2.44.2.1.2 创建Django项目
首先定位到PaddleSeg-release-v2.0.0-rc目录下面,然后使用命令创建一个django项目:
django-admin startproject djangoSeg这样在项目根目录下创建了一个名为djangoSeg的项目。接下来切换到djangoSeg下面,然后创建一个应用:
python manage.py startapp app在djangoSeg子目录下的settings.py文件中添加应用,具体修改两处地方:
ALLOWED_HOSTS = ['*',] #放开访问权限INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'app',# 添加引用
]接下来在urls.py文件中定义一个路由:
from django.contrib import admin
from django.urls import path
from app.views import seg
urlpatterns = [
path('admin/', admin.site.urls),
path('seg/', seg, name='seg'), #定义人像分割api
]通过上述路由设置我们就定义好了分割接口的api,如果是在本地运行,那么对应的网址就是:http://127.0.0.1:8000/seg 。
到这里我们先来梳理一下具体的执行流程:
(1)启动django服务器,启动时加载1次深度学习模型,该模型是全局变量,这样后面推理的时候就不需要再加载了,可以有效节省时间;
(2)服务器启动并且加载模型后进入等待状态,直到有请求到达;
(3)客户端(使用python脚本或者网页)将本地的一张图像加载并以二进制流stream的形式发送至http://127.0.0.1:8000/seg进行处理,然后开始等待服务器返回;
(4)服务器收到请求,调用对应的视图处理函数seg进行处理,首先从流中恢复出图像数据然后调用深度学习模型进行人像分割,然后从服务器本地加载一张固定背景图进行合成,合成出新图先jpg压缩再采用base64编码转json返回给客户端;
(5)客户端收到服务器的返回结果,首先base64解码再jpg解压缩获得返回的图像数据,最后展示图像;
首先在manage.py同目录下定义一个load_model.py文件,该文件用于加载paddle模型,代码如下:
#导入paddle库
import paddle
import paddle.nn.functional as F
#导入自定义库
import sys
sys.path.append("..")
from paddleseg.models import BiSeNetV2
#参数设置
model_path='model.pdparams'
crop_size=(320,320)
mean=(0.5, 0.5, 0.5)
std=(0.5, 0.5, 0.5)
num_class=2
#cuda环境设置
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
#加载模型
segmodel = BiSeNetV2(num_class)
para_state_dict = paddle.load(model_path)
segmodel.set_dict(para_state_dict)
segmodel.eval()
paddle.no_grad()然后在settings.py文件最后添加该文件:
import load_model这样在django程序启动的时候就会加载1次模型了。
接下来在app/views文件中进行视图处理函数的编写:
# 导入django库
from django.shortcuts import render
from django.views.decorators.csrf import csrf_exempt
from django.http import JsonResponse
#导入第三方库
import numpy as np
import json
import cv2
import base64
#导入paddle库
import paddle
import paddle.nn.functional as F
#导入全局模型和相关参数
from load_model import crop_size,mean,std,segmodel
def read_image(stream=None):
"""
从数据流中读取图像
"""
data_temp = stream.read()
im = np.asarray(bytearray(data_temp), dtype="uint8")
im = cv2.imdecode(im, cv2.IMREAD_COLOR)
return im
@csrf_exempt
def seg(request):
result = {}
if request.method == "POST":
if request.FILES.get('image') is not None:
im = read_image(stream=request.FILES["image"])
else:
result["img64"] = ""
return JsonResponse(result)
#读取图像
ori_shape = im.shape[:2]
org_img=im.copy()
#图像预处理
im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
im = cv2.resize(im, crop_size, cv2.INTER_LINEAR)
im = im.astype(np.float32, copy=False) / 255.0
im -= mean
im /= std
#转换成4通道张量格式
im = np.transpose(im, (2, 0, 1))
im = im[np.newaxis, ...]
im = paddle.to_tensor(im)
#模型推理
logits = segmodel(im)
logit = logits[0]
pred = paddle.argmax(logit, axis=1, keepdim=True, dtype='int32')
pred = F.interpolate(pred, ori_shape, mode='nearest')
#生成二值掩码图像
pred = paddle.squeeze(pred)
pred = pred.numpy().astype('uint8')*255
#与新背景合成
im = org_img.copy()
bg=cv2.imread('bg.png')
bg=cv2.resize(bg, (ori_shape[1],ori_shape[0]), cv2.INTER_LINEAR)
alpha=cv2.cvtColor(pred,cv2.COLOR_GRAY2BGR)
alpha_f = alpha / 255.
comp = im * alpha_f + bg * (1. - alpha_f)
im=comp.astype(np.uint8)
retval, buffer_img = cv2.imencode('.jpg', im) # 在内存中编码为jpg格式
img64 = base64.b64encode(buffer_img) # base64编码用于网络传输
img64 = str(img64, encoding='utf-8') # bytes转换为str类型
result["img64"] = img64 # json封装
return JsonResponse(result)这里注意,需要将之前训练好的model.pdparams文件放置在项目manage.py同目录下面,另外还需准备一张名为bg.png的新的背景图也放置在这个位置。
最后启动服务即可:
python manage.py runserver启动成功后效果如下所示:

接下里我们开始开发客户端,这里客户端使用python脚本来实现,具体代码如下:
import cv2, requests
import numpy as np
import base64
url = "http://localhost:8000/seg/" #访问接口
# 上传图像并分割
tracker = None
imgPath = "test.jpg" #图像路径
files = {
"image": ("filename2", open(imgPath, "rb"), "image/jpeg"),
}
#获取结果并解码
req = requests.post(url, data=tracker, files=files).json()
im64=req["img64"]
im64 = bytes(im64, encoding="utf-8")
img = np.frombuffer(base64.decodestring(im64),"float32")
img = cv2.imdecode(img, cv2.IMREAD_COLOR)
#结果显示
cv2.imshow("portrait segmentation", img)
cv2.waitKey(0)从上面的客户端脚本可以看到,客户端并不需要paddle等深度学习环境,因此这种web部署方式对客户端是最友好的。执行上述客户端脚本,效果如下所示:


左图是原始图像,右图是服务器返回回来的图像。
采用这种部署方式可以快速的搭建产品原型,用于产品演示和低并发情况下部署。以上内容更偏重django,因此这里我不再详细阐述细节。
4.2.2 高并发部署
4.2.2.1 架构设计
前面我们使用django自带的开发服务器进行部署,这个服务器只需要使用命令python manage.py runserver就可以启动,用来调试程序非常方便。但是这个开发者服务器本身无法满足多并发访问需求,因此,我们还需要把这个项目部署到真正的生产级服务器上,这里我们使用微软的IIS服务器。另一方面,在架构设计上我们没有充分考虑GPU本身的性能和稳定性,如果并发访问比较多的时候,每个视图处理函数都会调用全局深度学习模型变量进行推理,容易造成GPU资源冲突并且容易out of memory。另外,采用前面这种架构虽然理解比较简单,但是很明显,GPU是按照请求来的顺序一个一个进行推理的,即batch_size永远等于1,而我们知道,如果将当前需要处理的一部分图像按照batch进行整合然后集中推理,可以充分发挥性能优势,提高处理速度。因此,我们需要对整体的web架构重新进行设计使得我们能够充分发挥GPU性能并且服务器运行更加稳定。
为此本文设计了下图所示的这个架构:
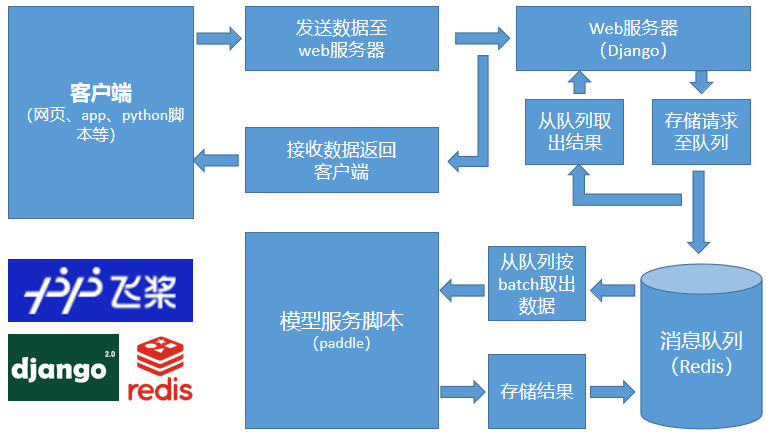
前面客户端发过来的请求首先交给django web服务器,然后django web服务器调用视图处理函数进行处理,在处理时,不直接使用深度学习模型进行推理,而是把图像推送至Redis消息队列,然后等待Redis处理结果。在消息队列后面有一个专门的深度学习模型推理脚本,这个脚本定时的从Redis消息队列里按照最大batch_size取出图像数据进行集中推理,推理结束后将结果写入Redis消息队列。Web服务器实时的查询消息队列,当发现有结果时就取出结果并返回给客户端。
采用上述这种架构可以将web服务器和深度学习推理模块有效解耦,环境配置更加简单,可以充分发挥GPU性能进行深度学习批量推理并且能够保证GPU运行稳定性,同时通过观察Redis消息队列里的当前剩余请求数就可以实时监控当前web系统是否过载,是否需要扩容等问题。
4.2.2.2 生产环境部署
在讲解具体部署前,先了解一下Redis数据库。redis是一个非关系型的缓存数据库,因为是缓存所以Redis的速度会非常快(操作都是在内存中进行),Redis主要是依靠键值对进行存储,类似于java的map、python的字典。Redis支持许多的语言,如java、C、C++、C#、PHP、JavaScript、Perl、python等。
下面讲解具体的Redis安装方法。首先从github上下载适用于windows的Redis安装包,本文下载3.2.100版本,将其中的Redis-x64-3.2.100zip压缩包下载下来,如下图所示:
下载解压后将其放置在指定目录下,然后将该目录添加到系统环境变量中。接下来在命令行窗口中启动Redis:
redis-server.exe启动后如下图所示:
注意上述的端口号是6379。
安装并启动后怎么使用python连接Redis呢?这里我们可以使用现成的python包来实现。首先安装依赖包:
pip install redis注意,这里使用pip安装的redis仅仅是一个python桥接工具而已,有了这个工具我们就可以在python中方便的连接并使用Redis了。我们可以使用下面的代码测试一下:
import redis
if __name__ == "__main__":
r = redis.Redis(host="localhost",port=6379,decode_responses=True)
r.set("name","a")
print(r.get("name"))运行上述脚本,正常情况下会输出a。当然也可以使用命令程序验证:
redis-cli ping正常情况会输出“PONG”。在Windows系统上有很多工具可以用来管理Redis数据库,这些工具可以用可视化的方式查看、修改当前键值对,使用非常便捷,具体的本文就不再深入介绍,读者可以自行查阅相关Redis教程。
下面正式开始进入生产级部署环节。
首先修改load_model.py文件,这里不再需要在django中执行深度学习操作,我们只需要连接redis即可:
import redis
IMAGE_WIDTH = 320
IMAGE_HEIGHT = 320
IMAGE_DTYPE = "float32"
IMAGE_QUEUE = "image_queue"
CLIENT_SLEEP = 0.25
mean=(0.5, 0.5, 0.5)
std=(0.5, 0.5, 0.5)
db = redis.StrictRedis(host="localhost", port=6379, db=0)然后修改views.py文件,导入相关的库和参数:
# 导入django库
from django.shortcuts import render
from django.views.decorators.csrf import csrf_exempt
from django.http import JsonResponse
#导入第三方库
import numpy as np
import json
import cv2
import base64
import uuid
import time
#导入参数
from load_model import db, IMAGE_WIDTH, IMAGE_HEIGHT, IMAGE_DTYPE, mean, std, IMAGE_QUEUE, CLIENT_SLEEP由于我们需要将图像通过redis进行存储(中转),比较好的方式就是将图像先base64转码再存储,具体添加两个处理函数:
def base64_encode_image(a):
"""
将numpy数组进行base64编码
"""
return base64.b64encode(a).decode("utf-8")
def base64_decode_image(a, dtype, shape):
"""
base64转图像
"""
a = bytes(a, encoding="utf-8")
a = np.frombuffer(base64.decodestring(a), dtype=dtype)
a = a.reshape(shape)
return a接下来修改最重要的视图处理函数seg,具体如下:
@csrf_exempt
def seg(request):
result = {"success": False}
if request.method == "POST":
if request.FILES.get('img') is not None:
im = read_image(stream=request.FILES["img"])
else:
result["img"] = ""
result["reason"] = "image format is wrong"
return JsonResponse(result)
#读取图像
ori_shape = im.shape[:2]
org_img = im.copy()
#图像预处理
im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
im = cv2.resize(im, (IMAGE_WIDTH, IMAGE_HEIGHT), cv2.INTER_LINEAR)
im = im.astype(np.float32, copy=False) / 255.0
im -= mean
im /= std
#转换成4通道张量格式
im = np.transpose(im, (2, 0, 1))
im = im[np.newaxis, ...]
im = im.copy(order="C")
#图像存储进redis
k = str(uuid.uuid4())
d = {"id": k, "img": base64_encode_image(im)}
db.rpush(IMAGE_QUEUE, json.dumps(d))
time_out_num = 0
while True:
# 尝试获取结果
output = db.get(k)
if output is not None:
#取出结果
output = json.loads(output.decode("utf-8"))
pred = base64_decode_image(output["img"], IMAGE_DTYPE,(1,IMAGE_HEIGHT, IMAGE_WIDTH))
pred = pred.astype('uint8')
pred = pred[0]
#与新背景合成
im = org_img.copy()
bg = cv2.imread('bg.png')
bg = cv2.resize(bg, (ori_shape[1], ori_shape[0]),cv2.INTER_LINEAR)
alpha = cv2.cvtColor(pred, cv2.COLOR_GRAY2BGR)
alpha = cv2.resize(alpha, (ori_shape[1], ori_shape[0]), cv2.INTER_NEAREST)
alpha_f = alpha / 255.
comp = im * alpha_f + bg * (1. - alpha_f)
im = comp.astype(np.uint8)
cv2.imwrite("gen.jpg",im)
#压缩编码
retval, buffer_img = cv2.imencode('.jpg', im) # 在内存中编码为jpg格式
img64 = base64.b64encode(buffer_img)
img64 = str(img64, encoding='utf-8')
result["img"] = img64 # json封装
result["success"] = True
result["reason"] = ""
db.delete(k)
break
time.sleep(CLIENT_SLEEP)
#设置超时机制
time_out_num = time_out_num + 1
if (time_out_num > 10):
result["success"] = False
result["img"] = ""
result["reason"] = "time out, the web server is busy now"
db.delete(k)
return JsonResponse(result)
return JsonResponse(result)上述代码执行时,首先从数据流中取出图像数据,然后对它进行预处理(得到numpy数组),处理完以后随机生成一个id号,然后对图像数据进行base64转码再和id一起组成json字符串,然后保存到redis数据库中。接下来就是进入while循环一直等待,直到redis中返回了处理结果,再进行背景合成返回结果给客户端。如果长时间等待无响应,那么就返回错误结果给前端并告知超时。
完成上述修改后就可以启动django:
python manage.py runserver启动成功后我们接下来就可以编写深度学习推理脚本,具体的创建一个run_model文件夹(与manage.py同目录下),然后新建run_model.py文件和tool.py文件,其中tool.py文件用于存放base64编码和解码函数。run_model.py文件则是主要的推理文件,具体如下:
#导入第三方库
import os
import numpy as np
import json
import cv2
import base64
import time
import redis
#导入paddle库
import paddle
import paddle.nn.functional as F
#导入自定义库
import sys
sys.path.append("../..")
from paddleseg.models import BiSeNetV2
from tool import base64_encode_image,base64_decode_image
#参数设置
model_path='model.pdparams'
IMAGE_WIDTH = 320
IMAGE_HEIGHT = 320
IMAGE_DTYPE = "float32"
num_class=2
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
IMAGE_QUEUE = "image_queue"
SERVER_SLEEP = 0.25
db = redis.StrictRedis(host="localhost", port=6379, db=0)
BATCH_SIZE = 32
#加载模型
segmodel = BiSeNetV2(num_class)
para_state_dict = paddle.load(model_path)
segmodel.set_dict(para_state_dict)
segmodel.eval()
with paddle.no_grad():
while True:
# 批量获取图像
queue = db.lrange(IMAGE_QUEUE, 0, BATCH_SIZE - 1)
imageIDs = []
batch = None
for q in queue:
# 解析图像
q = json.loads(q.decode("utf-8"))
image = base64_decode_image(q["img"], IMAGE_DTYPE,(1,3, IMAGE_HEIGHT, IMAGE_WIDTH))
if batch is None:
batch = image
else:
batch = np.vstack([batch, image])
# 更新ID
imageIDs.append(q["id"])
if len(imageIDs) > 0:
# 批量推理
print("当前Batch大小: {}".format(batch.shape))
batch = paddle.to_tensor(batch)
logits = segmodel(batch)
logit = logits[0]
preds = paddle.argmax(logit, axis=1, keepdim=True, dtype='int32')
# 生成二值掩码图像
preds = preds.numpy().astype('uint8')*255
preds = preds.astype('float32')
# 将结果写入redis
index = 0
for imageID in imageIDs:
pred = preds[index].copy(order="C")
output = {"img": base64_encode_image(pred)}
db.set(imageID, json.dumps(output))
index = index+1
# 移除图像队列数据
db.ltrim(IMAGE_QUEUE, len(imageIDs), -1)
time.sleep(SERVER_SLEEP)上述脚本首先载入深度学习模型,然后从redis中批量取出图片,这里BATCH_SIZE可以根据实际的服务器GPU性能进行设置。通过这种方式可以使得GPU不会产生out of memory现象。另外,由于推理时采用了batch方式,因此相比一张一张图像推理速度更快。
完成上述编写后启动脚本运行服务:
python run_model.py这样django服务和深度学习服务都已经正常启动了。
最后,我们写一个客户端脚本来测试一下功能:
import cv2, requests
import numpy as np
import base64
url = "http://localhost:8000/seg/" #访问接口
# 上传图像并分割
tracker = None
imgPath = "test.jpg" #图像路径
files = {
"img": ("filename2", open(imgPath, "rb"), "image/jpeg"),
}
#获取结果并解码
req = requests.post(url, data=tracker, files=files).json()
issuccess=req["success"]
if issuccess:
im64=req["img"]
im64 = bytes(im64, encoding="utf-8")
img = np.frombuffer(base64.decodestring(im64),"float32")
img = cv2.imdecode(img, cv2.IMREAD_COLOR)
#结果显示
cv2.imshow("portrait segmentation", img)
cv2.waitKey(0)
else:
print("失败:")
if req["reason"] is not None:
print(req["reason"])上述代码正常成功后会显示替换过背景的人像图片。
接下来为了应对高并发访问要求,我们需要将django项目部署到IIS服务器上去,由于这部分内容完全属于django本身的内容,本文就不再详细阐述,具体可以参考我的博客或者参考我的书籍《Python Web开发从入门到实战》。
4.2.2.3 压力测试
本小节针对前面设计的高并发架构来进行压力测试,只需要修改客户端代码即可,具体如下:
# 导入库
from threading import Thread
import time
import cv2, requests
import numpy as np
import base64
# 参数设置
url = "http://localhost:80/seg/" # 访问接口
imgPath = "test.jpg" # 图像路径
NUM_REQUESTS = 500 # 并发请求数
SLEEP_COUNT = 0.05 # 请求间隔
def call_seg(n):
"""
并行发送线程
"""
myfile = {
"img": ("filename2", open(imgPath, "rb"), "image/jpeg"),
}
#提交图像
tracker = None
req = requests.post(url, data=tracker, files=myfile).json()
#显示并保存结果
if (req["success"]):
print("线程 {} 成功".format(n))
im64 = req["img"]
im64 = bytes(im64, encoding="utf-8")
img = np.frombuffer(base64.decodestring(im64), "float32")
img = cv2.imdecode(img, cv2.IMREAD_COLOR)
imgpath = 'results/' + str(n) + '.jpg'
cv2.imwrite(imgpath, img)
else:
print("线程 {} 失败".format(n))
if __name__ == '__main__':
for i in range(0, NUM_REQUESTS):
t = Thread(target=call_seg, args=(i, ))
t.daemon = True
t.start()
time.sleep(SLEEP_COUNT)
time.sleep(300)主要是通过python线程模拟500个访问请求,具体执行效果如下图所示:

同时可以看到当前GPU情况,可以看到性能是比较稳定的:
整体来看,搭建生产级的深度学习web平台是有一定难度的,比较好的方式就是尽量解耦合、模块化,这样能够避免很多环境配置限制,同时也更利于算法开发人员和Web开发人员协同合作。本文给了一种可行方案,具体落地应用时还需要考虑很多细节和优化问题,例如怎么监控当前负载情况,怎么批量化部署等等。
以上整个web部署方案在我自己的项目中也采用了类似的架构进行了真实的项目落地应用(唯一与本教程不同的是没有采用django而是采用java web作为web框架)。由于水平有限,肯定有不少错误或者不当之处,也希望读者能够指正。
4.3 PC端C++推理
无论是使用python脚本推理还是基于python的web推理,都不可避免的需要依赖python环境。在工业应用领域,对实时性和稳定性要求较高,因此一般会使用C++来进行客户端开发,如果需要界面编程那么也有很多开发者使用MFC、QT、C#等框架来集成C++代码。很自然的,为了能够在工业应用领域使用我们的深度学习模型,我们需要将整个的部署推理进行转换,全部采用C++来实现。这样做虽然比较麻烦,但是好处很多,可以使得我们的推理环境更加的“干净”(不需要再安装一堆的python环境库和paddle环境库,只需要复制一些dll即可),核心代码更加的安全(C++是编译型语言,代码转换为二进制后比较难被破译,而python代码容易被人解析)。因此,接下来在本小节我们着重来实现基于C++的PC客户端部署开发。
4.3.1 动态图转静态图
前面我们都是使用paddle2.0动态图来训练和部署,使用动态图有很多优点,包括易用的接口,Python风格的编程体验,友好的debug交互机制等。在动态图模式下,代码是按照我们编写的顺序依次执行,代码更容易改写和调试。相比动态图,静态图在部署方面更具有性能的优势。静态图程序在编译执行时,先搭建模型的神经网络结构,然后再对神经网络执行计算操作。预先搭建好的神经网络可以脱离Python依赖,在C++端被重新解析执行,而且能进行一些网络结构的优化。Paddle提供了动态图转静态图的功能,使得我们前面依然可以使用动态图进行训练,部署时再转成静态图即可,这种方式就可以兼顾动态图易用性和静态图部署性能两方面优势。
具体的,paddle提供了两种方式用于转换:跟踪(trace)和程序翻译(ProgramTranslator)。官方优先推荐使用ProgramTranslator方式,对一些稍微复杂的python控制流写的动态图模型使用ProgramTranslator也能够成功转化静态图。
具体的,在定义模型的BiSeNetV2的forward函数前添加#@paddle.jit.to_static装饰器即可,如下所示:
class BiSeNetV2(nn.Layer):
def __init__(self,
num_classes,
lambd=0.25,
align_corners=False,
pretrained=None):
super().__init__()
......
#@paddle.jit.to_static #这里添加装饰器
def forward(self, x):
dfm = self.db(x)
......然后修改test.py文件,其它都不需要修改,只需要对模型推理部分添加动转静代码即可:
#模型推理
logits = model(im)
paddle.jit.save(model, "output/seg", input_spec=[im])
logit = logits[0]
pred = paddle.argmax(logit, axis=1, keepdim=True, dtype='int32')
pred = F.interpolate(pred, ori_shape, mode='nearest')
......这样在output目录下就生成了3个文件:seg.pdmodel、seg.pdiparams和seg.pdiparams.info,其中seg.pdmodel文件表示模型的结构文件,seg.pdiparams表示所有参数的融合文件,这两个文件就是最终生成的静态图部署文件。
4.3.2 基于Paddle Inference的C++推理
Paddle Inference是一个高性能预测引擎,该引擎通过对计算图的分析,完成对计算图的一系列的优化(如OP的融合、内存/显存的优化、 MKLDNN,TensorRT 等底层加速库的支持等),能够大大提升预测性能。本小节我们就采用paddle inference对前面转换的静态图模型进行C++推理。
4.3.2.1 安装Paddle Inference
安装分成两种方式,一种是使用官网提供的编译好的预测库,还有一种就是下载源码然后自己编译。我们这里采用的是paddle2,cuda10.0,windows10操作系统,官网有现成的编译好的预测库,我们直接拿来使用就可以。官网地址:使用指南-使用文档-PaddlePaddle深度学习平台
版本信息如下:
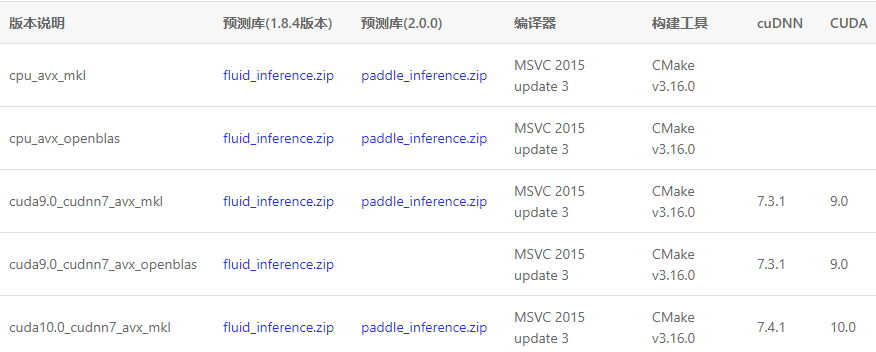
这里选择最后一行paddle_inference.zip进行下载即可,下载好后将其解压至特定目录(目录中不要含中文或特殊符号),本文将其放置在d:/toolplace文件夹下面。接下来在windows中安装好VS2015和CMake,其安装步骤本文就不再详细介绍。
另外,本文需要使用opencv加载图像,因此需要安装好opencv,下载地址:Releases - OpenCV。这里选择比较新的OpenCV4.5.1对应的windows版本下载。
运行下载下来的exe程序,将opencv安装到指定目录(同样,目录中不要出现中文和特殊字符),本文将其放置在d:/toolplace文件夹下面。
4.3.2.2 创建Win32 C++项目
本小节将使用VS2015来创建一个win32 C++控制台工程,名称为seg_demo,在这个工程里面实现人像语义分割推理。如下图所示:
然后把预编译头选项去掉:
创建完成后我们重新设置生成项目为Release,并且是64位(必须是构建64位程序),如下图所示:

然后将项目编译运行一下确保基本环境没有问题。
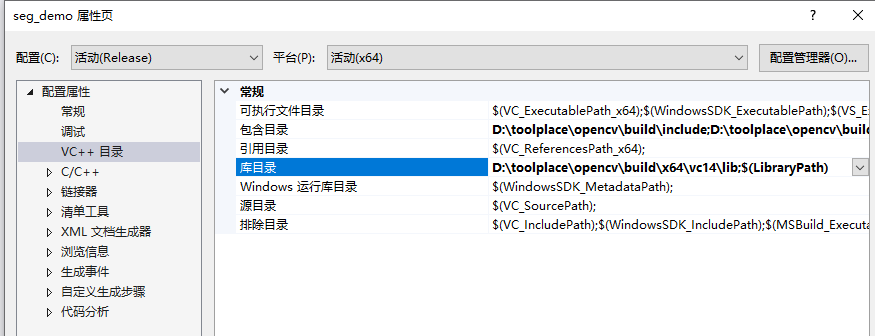
接下来进行项目配置。首先配置一下opencv使得能够正常的在程序中加载图像。单击菜单栏“项目”-“属性”,然后单击左侧“VC++目录”,在右边包含目录中添加如下路径:
D:\toolplace\opencv\build\include
D:\toolplace\opencv\build\include\opencv2在库目录中添加:
D:\toolplace\opencv\build\x64\vc14\lib如下图所示:
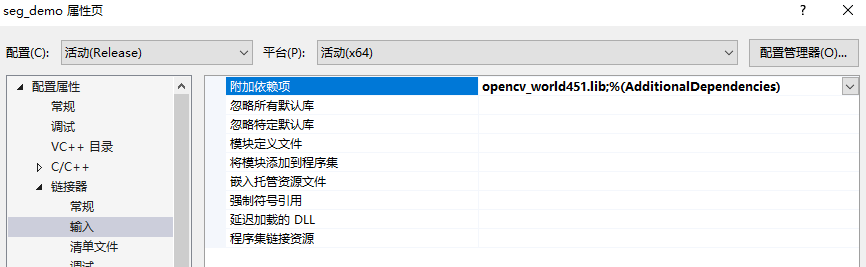
然后单击左侧“链接器”—“输入”,在右侧附加依赖项中添加opencv对应的lib文件:
opencv_world451.lib如下图所示:
最后将D:\toolplace\opencv\build\x64\vc14\bin目录下的opencv_world451.dll文件拷贝到seg_demo工程的根目录下面。然后我们找张测试图片,命名为test.jpg也放置在seg_demo工程的根目录下面。
下面打开seg_demo.cpp主文件,编写代码测试下:
//导入系统库
#include "stdafx.h"
#include <iostream>
//导入opencv库
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
using namespace cv;
int main()
{
Mat img = imread("test.jpg");
namedWindow("图片");
imshow("图片", img);
waitKey(6000);
return 0;
}按ctrl+F5运行,如果没有问题会显示test.jpg图片。到这里就配置好opencv了。
上面我们已经存放好了paddle_inference和opencv对应的包,并且都放置在了d盘的toolplace文件夹下面,这些文件夹可以不用换地方,以后其它工程也可以用来链接它们。除了这两个包以外还有一个,即运行GPU对应的cuda包,我们在C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\lib\x64目录下(此处注意版本的一致性,我们下载的paddle_inference是cuda10.0的,所以这里引用的cuda目录也要对应着10.0),然后将其中的所有的lib文件复制出来,复制到d:/toolplace下的cuda目录,这个cuda目录就是专门用于存放cuda的lib文件的。到这里,项目需要的所有文件都已经准备好了,接下来就需要在项目中链接并使用它们。
接下来在项目seg_demo中配置环境。单击菜单栏“项目”-“seg_demo属性”,打开属性页面,然后在左侧单击“VC++目录”,在右侧“包含目录”中添加如下路径:
D:\toolplace\opencv\build\include
D:\toolplace\opencv\build\include\opencv2
D:\toolplace\paddle_inference_install_dir
D:\toolplace\paddle_inference_install_dir\third_party\install\cryptopp\include
D:\toolplace\paddle_inference_install_dir\third_party\install\gflags\include
D:\toolplace\paddle_inference_install_dir\third_party\install\glog\include
D:\toolplace\paddle_inference_install_dir\third_party\install\mkldnn\include
D:\toolplace\paddle_inference_install_dir\third_party\install\mklml\include
D:\toolplace\paddle_inference_install_dir\third_party\install\protobuf\include
D:\toolplace\paddle_inference_install_dir\third_party\install\xxhash\include
D:\toolplace\paddle_inference_install_dir\paddle\include具体修改方式对照着自己的包存放路径来设置。然后在库目录里面添加如下库:
D:\toolplace\opencv\build\x64\vc14\lib
D:\toolplace\paddle_inference_install_dir\third_party\install\cryptopp\lib
D:\toolplace\paddle_inference_install_dir\third_party\install\gflags\lib
D:\toolplace\paddle_inference_install_dir\third_party\install\glog\lib
D:\toolplace\paddle_inference_install_dir\third_party\install\mkldnn\lib
D:\toolplace\paddle_inference_install_dir\third_party\install\mklml\lib
D:\toolplace\paddle_inference_install_dir\third_party\install\protobuf\lib
D:\toolplace\paddle_inference_install_dir\third_party\install\xxhash\lib
D:\toolplace\paddle_inference_install_dir\paddle\lib
D:\toolplace\cuda最后,单击左侧“链接器”—“输入”,在附加依赖项中输入如下lib文件:
opencv_world451.lib
cryptopp-static.lib
gflags_static.lib
glog.lib
mkldnn.lib
libiomp5md.lib
mklml.lib
libprotobuf.lib
xxhash.lib
paddle_fluid.lib
cudart.lib
cublas.lib
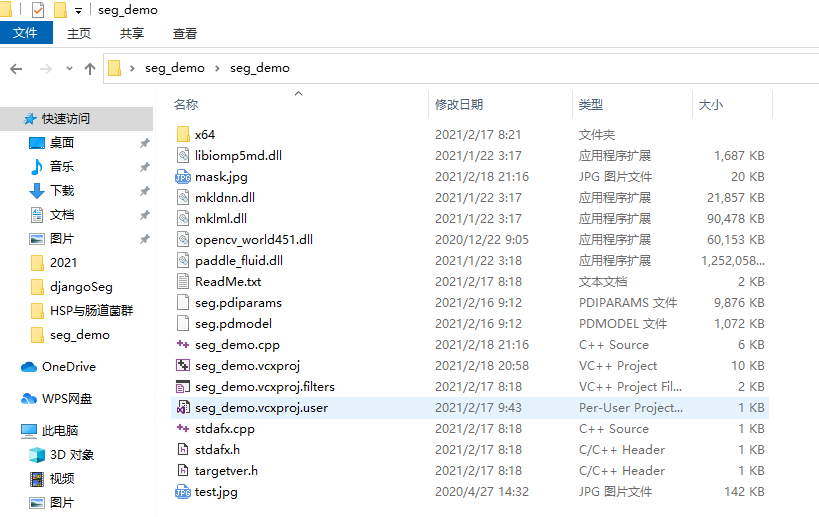
cudnn.lib为了能够在工程中运行深度学习模型,我们将前面动转静得到的seg.pdiparams和seg.pdmodel放置在seg_demo项目根目录下,然后将前面各个配置文件夹下面的dll文件也拷贝到当前项目根目录下面,最后根目录文件如下所示,其中test.jpg是用来测试的图像:
打开seg_demo.cpp文件,在这个文件里面我们将实现单张人像的推理。具体代码如下:
/*******************************************************************
* Copyright(c) 2021-2025 TMRI
* All rights reserved.
*
* 文件名称:seg_demo.cpp
* 简要描述:基于C++的人像分割demo
*
* 创建日期:2021-02-17
* 作者:钱彬
* 说明:使用paddle2.0.0动态图版本 cuda10.0 cudnn7.6 opencv4.5.1
******************************************************************/
//导入系统库
#include "stdafx.h"
#include <iostream>
//导入opencv库
#include <opencv2/opencv.hpp>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
//导入paddle库
#include <glog/logging.h>
#include <memory>
#include <string>
#include <vector>
#include <thread>
#include <chrono>
#include <algorithm>
#include <paddle_inference_api.h>
using namespace cv;
//定义全局变量
std::unique_ptr<paddle::PaddlePredictor> g_predictor;
std::vector<float> g_buffer;
std::vector<int> g_org_width;
std::vector<int> g_org_height;
std::vector<std::string> g_imgs_batch;
std::vector<paddle::PaddleTensor> g_outputs;
std::vector<uchar> g_mask;
std::vector<uchar> g_scoremap;
int crop_width = 320;
int crop_height = 320;
std::vector<float> g_fmean;
std::vector<float> g_fstd;
void init() {
paddle::AnalysisConfig config;
config.EnableUseGpu(100, 0);
config.SetModel("seg.pdmodel", "seg.pdiparams");
config.SwitchUseFeedFetchOps(false);
config.SwitchSpecifyInputNames(true);
config.EnableMemoryOptim();
g_predictor = paddle::CreatePaddlePredictor(config);
g_fmean.push_back(0.5);
g_fmean.push_back(0.5);
g_fmean.push_back(0.5);
g_fstd.push_back(0.5);
g_fstd.push_back(0.5);
g_fstd.push_back(0.5);
int res_size = crop_width*crop_height;
g_mask.resize(res_size);
g_scoremap.resize(res_size);
}
void normalize(cv::Mat& im, float* data, std::vector<float>& fmean,
std::vector<float>& fstd) {
int rh = im.rows;
int rw = im.cols;
int rc = im.channels();
double normf = static_cast<double>(1.0) / 255.0;
#pragma omp parallel for
for (int h = 0; h < rh; ++h) {
const uchar* ptr = im.ptr<uchar>(h);
int im_index = 0;
for (int w = 0; w < rw; ++w) {
for (int c = 0; c < rc; ++c) {
int top_index = (c * rh + h) * rw + w;
float pixel = static_cast<float>(ptr[im_index++]);
pixel = (pixel * normf - fmean[c]) / fstd[c];
data[top_index] = pixel;
}
}
}
}
void argmax(float* out, std::vector<int>& shape,
std::vector<uchar>& mask, std::vector<uchar>& scoremap) {
int out_img_len = shape[1] * shape[2];
int blob_out_len = out_img_len * shape[0];
float max_value = -1;
int label = 0;
#pragma omp parallel private(label)
for (int i = 0; i < out_img_len; ++i) {
max_value = -1;
label = 0;
#pragma omp for reduction(max : max_value)
for (int j = 0; j < shape[0]; ++j) {
int index = i + j * out_img_len;
if (index >= blob_out_len) {
continue;
}
float value = out[index];
if (value > max_value) {
max_value = value;
label = j;
}
}
if (label == 0) max_value = 0;
if (max_value * 255 > 255)max_value = 1;
mask[i] = uchar(label);
scoremap[i] = uchar(max_value * 255);
}
}
void predict(Mat &org_img,Mat &mask)
{
//拷贝图像
int orgWidth = org_img.cols;
int orgHeight = org_img.rows;
Mat img = cv::Mat(orgHeight, orgWidth, CV_8UC3);
memcpy(img.data, org_img.data, orgWidth*orgHeight*3);
//预处理
cvtColor(img, img, cv::COLOR_BGR2RGB);
resize(img, img, cv::Size(crop_width, crop_height), 0, 0, cv::INTER_LINEAR);
int real_buffer_size = 3 * crop_width* crop_height;
auto& input_buffer = g_buffer;
input_buffer.resize(real_buffer_size);
normalize(img, input_buffer.data(), g_fmean, g_fstd);
//转tensor
auto input_names = g_predictor->GetInputNames();
auto im_tensor = g_predictor->GetInputTensor(input_names[0]);
im_tensor->Reshape({ 1, 3, crop_height, crop_width });
im_tensor->copy_from_cpu(input_buffer.data());
//执行预测
g_predictor->ZeroCopyRun();
//取出预测结果
auto output_names = g_predictor->GetOutputNames();
auto output_t = g_predictor->GetOutputTensor(output_names[0]);
std::vector<int> output_shape = output_t->shape();
int out_num = 1;
std::cout << "size of outputs[" << 0 << "]: (";
for (int j = 0; j < output_shape.size(); ++j) {
out_num *= output_shape[j];
std::cout << output_shape[j] << ",";
}
std::cout << ")" << std::endl;
std::vector<float> out_data;
out_data.resize(out_num);
output_t->copy_to_cpu(out_data.data());
float* out_addr = out_data.data();
// 获得掩码图
g_mask.clear();
g_scoremap.clear();
std::vector<int> out_shape{ 2, crop_height, crop_width };
argmax(out_addr, out_shape, g_mask, g_scoremap);
cv::Mat scoremap_png = cv::Mat(crop_height, crop_width, CV_8UC1);
memcpy(scoremap_png.data, g_scoremap.data(), crop_height*crop_width * 1);
resize(scoremap_png, scoremap_png, cv::Size(orgWidth, orgHeight), 0, 0, cv::INTER_NEAREST);
memcpy(mask.data, scoremap_png.data, orgWidth*orgHeight * 1);
//结束清理
scoremap_png.release();
}
int main()
{
//初始化环境
init();
//加载图像和预处理
Mat img = imread("test.jpg");
Mat mask = Mat(img.rows, img.cols, CV_8UC1);
//开始推理
predict(img, mask);
//保存掩码结果
imwrite("mask.jpg", mask);
std::cout << "处理完成" << std::endl;
return 0;
}
此处借鉴了paddle静态图版本的C++推理代码,并且将代码进行了精简,使其更加容易看懂和修改。程序主要功能就是加载图像,然后对图像进行预测,最后得到预测掩码图mask.jpg。有了预测掩码图就可以实现后续人像背景替换之类的运用,由于代码比较简单,本文就不再赘述了。效果如下所示:


本节实现了Win32的程序调用,其它框架包括C#、QT、MFC等都可以采用类似的方法,先制作基于C++的dll,然后再集成进来实现PC端深度学习推理。
五、总结
本文将所有代码和标签数据集放在了百度网盘里,需要的读者可以自行下载、训练和测试。由于爱分割人像数据集比较大(19G左右),因此分成了gt.rar和img.rar,分别存储真值标签和原始图像,下载后将其解压至工程PaddleSeg-release-v2.0.0-rc/data/ai_fen_ge文件夹下面即可。
完整代码下载地址:百度网盘-链接不存在 提取码:o543
爱分割图像数据集img下载地址:百度网盘-链接不存在 提取码:o74q
爱分割标签gt下载地址:百度网盘-链接不存在 提取码:yzq0
win32 C++程序下载地址:百度网盘-链接不存在 提取码:m9wk
当然本文还有很多没有做完的地方,例如我们模型采用的是语义分割模型,因此在人物边缘处会有背景的残影(尤其是发丝边缘),这个需要结合抠图领域的方法进行二次处理(例如KNN抠图、Closed form抠图等),也可以使用端到端的抠图模型重新修改模型进行训练,这个任务在后面我会继续改进并分享教程和代码。另外,本文还有移动端和嵌入式端部署方案没有完成,但是没办法春节假期实在太短来不及研究和撰写了,后面有机会一并补齐。
本篇博文如果有错误或者可以改进的地方也请读者指正,大家一起探讨一起进步。
六、参考文献
[1]. Paddle语义分割官网
[2]. Changqian Yu, Changxin Gao, Jingbo Wang, et al. BiSeNet V2: Bilateral Network with Guided Aggregation for Real-time Semantic Segmentation.


















 2217
2217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











