







时间序列预测——ARIMA(差分自回归移动平均模型)
ARIMA(p,d,q)中,AR是"自回归",p为自回归项数;I为差分,d为使之成为平稳序列所做的差分次数(阶数);MA为"滑动平均",q为滑动平均项数,。ACF自相关系数能决定q的取值,PACF偏自相关系数能够决定q的取值。ARIMA原理:将非平稳时间序列转化为平稳时间序列然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型
基本解释:
自回归模型(AR)
- 描述当前值与历史值之间的关系,用变量自身的历史时间数据对自身进行预测
- 自回归模型必须满足平稳性的要求
- 必须具有自相关性,自相关系数小于0.5则不适用
- p阶自回归过程的公式定义:
![]()
![]() ,y t-i 为前几天的值
,y t-i 为前几天的值
PACF,偏自相关函数(决定p值),剔除了中间k-1个随机变量x(t-1)、x(t-2)、……、x(t-k+1)的干扰之后x(t-k)对x(t)影响的相关程度。
移动平均模型(MA)
- 移动平均模型关注的是自回归模型中的误差项的累加,移动平均法能有效地消除预测中的随机波动
- q阶自回归过程的公式定义:
![]()
ACF,自相关函数(决定q值)反映了同一序列在不同时序的取值之间的相关性。x(t)同时还会受到中间k-1个随机变量x(t-1)、x(t-2)、……、x(t-k+1)的影响而这k-1个随机变量又都和x(t-k)具有相关关系,所 以自相关系数p(k)里实际掺杂了其他变量对x(t)与x(t-k)的影响
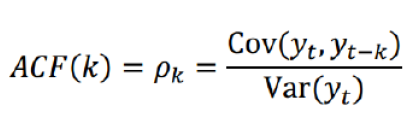
ARIMA(p,d,q)阶数确定:

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









