










文章目录
论文链接
源代码
摘要
最先进的目标检测网络依赖于区域生成算法来假设目标位置。SPPnet[1]和Fast R-CNN[2]等技术的进步减少了这些检测网络的运行时间,使区域生成计算成为瓶颈。
在这项工作中,我们引入了一个区域生成网络(RPN),它与检测网络共享全图像卷积特征,从而实现几乎无成本的区域生成
Region Proposal Network(RPN)是一个全卷积网络,它同时预测物体边界和物体在每个位置的得分。RPN经过端到端训练,生成高质量的候选框区域,用于Fast R-CNN的检测。通过共享它们的卷积特征,我们进一步将RPN和Fast R-CNN合并成一个单一的网络——使用最近流行的神经网络术语“注意”机制,RPN组件告诉统一的网络去哪里寻找
对于非常深的VGG-16模型[3],我们的检测系统在GPU上的帧率为5fps(包括所有步骤),同时在PASCAL VOC 2007年,2012年和MS COCO数据集上实现了最先进的目标检测精度,每张图像只有300个建议,在ILSVRC和COCO 2015比赛中,Faster R-CNN和RPN是多个赛道第一名获奖作品的基础
引言
区域生成方法(例如[4])和基于区域的卷积神经网络(R- cnn)[5]的成功推动了目标检测的最新进展
现在,proposals是最先进的检测系统的测试时间计算瓶颈、
过去计算proposals的算法
与高效的检测网络[2]相比,选择性搜索要慢一个数量级,在一个CPU实现中每张图像需要2秒。
EdgeBoxes[6]目前提供了提案质量和速度之间的最佳折衷,每张图像0.2秒
然而,区域生成步骤仍然消耗与检测网络相同的运行时间
研究中使用的区域生成方法是在CPU上实现的,加速proposal计算的一个显而易见的方法是在GPU上重新实现它。这可能是一种有效的工程解决方案,但重新实现忽略了下游检测网络,因此错过了共享计算的重要机会。
我们提出的
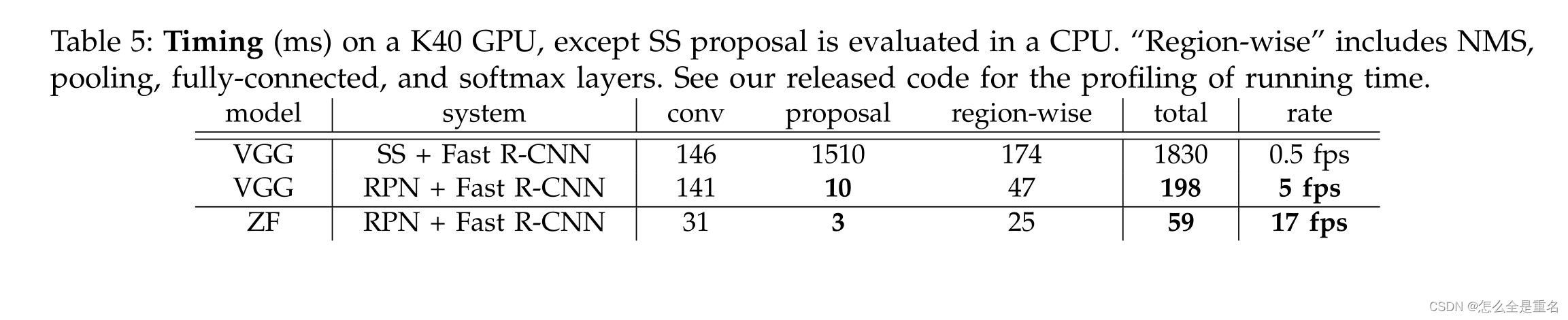
在给定检测网络计算的情况下,proposal计算几乎是零成本的。为此,我们引入了新的区域生成网络(RPNs),它与最先进的目标检测网络[1]SPPnet,[2]Fast RCNN共享卷积层。通过在测试时共享卷积,计算候选框的边际成本很小(例如,每张图像10ms)

不同的方案来处理多个尺度和尺寸
(a)构建图像金字塔和特征图,并在所有尺度上运行分类器
(b)在特征图上运行多个尺度/大小的滤波器金字塔
©我们在回归函数中使用参考框金字塔
相关工作
Object Proposals
目前广泛使用的目标生成方法包括基于超像素分组的对象提议方法(如:Selective Search[4]、CPMC[22]、MCG[23])和基于滑动窗口的对象提议方法(如:objectness in windows[24]、EdgeBoxes[6])。目标提议方法作为独立于检测器的外部模块(如:Selective Search[4]目标检测器、R-CNN[5]、Fast R-CNN[2])
Deep Networks for Object Detection
卷积[9],[1],[29],[7],[2]的共享计算在高效、准确的视觉识别方面受到越来越多的关注。OverFeat论文[9]从图像金字塔中计算卷积特征,用于分类、定位和检测。为了实现高效的基于区域的目标检测[1],[30]和语义分割[29],在共享卷积特征映射上开发了自适应大小池(SPP)[1]。快速R-CNN[2]使端到端检测器训练共享卷积特征,并显示出令人信服的准确性和速度
Faster R-CNN
我们的目标检测系统,称为Faster R-CNN,由两个模块组成
第一个模块是提出区域的深度全卷积网络,第二个模块是使用提出区域的Fast R-CNN检测器
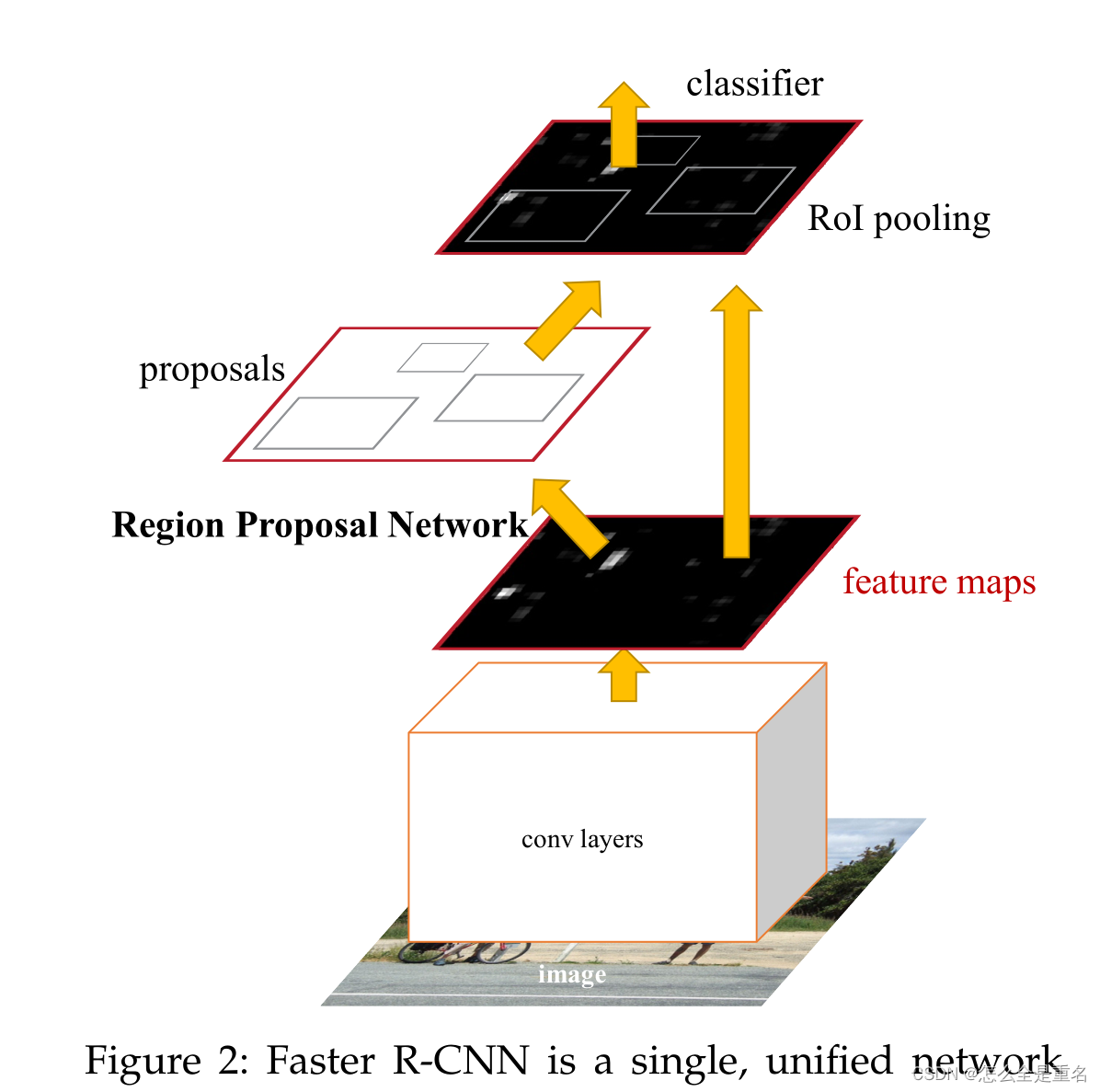
Faster R-CNN是一个单一的、统一的目标检测网络。RPN模块作为这个统一网络的“注意力”
Region Proposal Networks
区域生成网络(RPN)以任意大小的图像作为输入,并输出一组矩形对象候选框,每个候选框都有一个对象得分
为了生成候选区域,我们在最后一个共享卷积层输出的卷积特征映射上滑动一个小网络。这个小网络以输入卷积特征映射的一个n × n空间窗口作为输入,每个滑动窗口被映射到一个低维特征,这个特征被输入到两个同级的完全连接层中——一个盒回归层(reg)和一个盒分类层(cls)

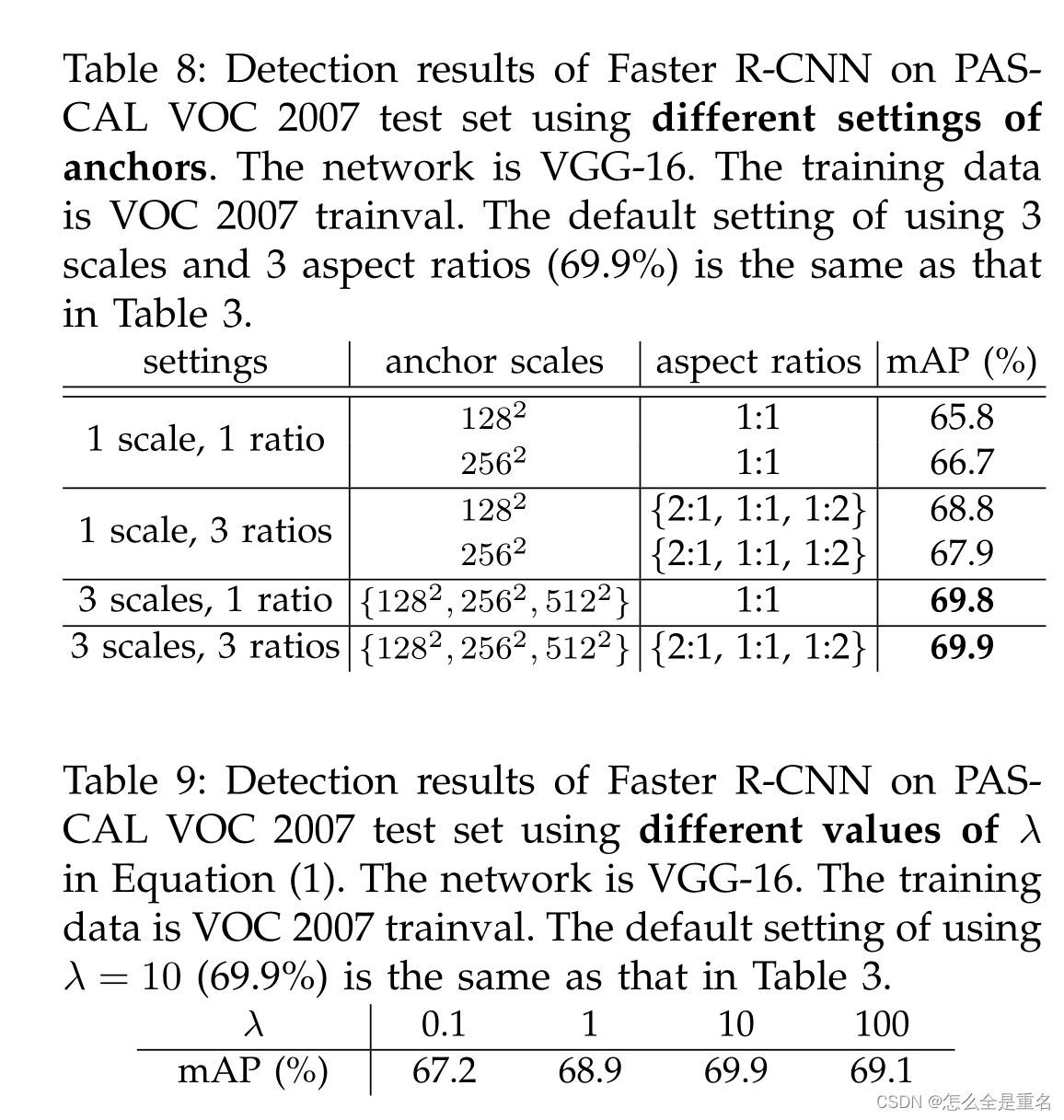
Anchors
在每个滑动窗口位置,我们同时预测多个候选区域,其中每个位置的最大可能生成数表示为k。因此,reg层有4k个输出,编码k个盒子的坐标,cls层输出2k个分数,估计每个候选框有对象或没有对象的概率。k个候选区是相对于k个参考框参数化的,我们称之为anchors
锚点位于所讨论的滑动窗口的中心,并与比例和纵横比相关联(图3,左)。默认情况下,我们使用3个尺度和3个纵横比,在每个滑动位置产生k =9个锚点。对于大小为W × H(通常为~ 2,400)的卷积特征映射,总共有WHk锚点
Translation-Invariant Anchors
我们的方法的一个重要性质是,它是平移不变的,无论是在锚点和计算相对于锚点的生成的函数方面
平移不变性也减少了模型的大小
Multi-Scale Anchors as Regression References
我们设计的anchor提出了一种解决多尺度(和纵横比)的新方案
多尺度预测有两种流行的方法
第一种方法是基于图像/特征金字塔(figure(1)a)
第二种方法是在特征图上使用多个尺度(和/或宽高比)的滑动窗口(figure(1)b)
我们的方法
我们的基于anchor的方法是建立在anchor的金字塔上的,这是更经济有效的,我们的方法参考多尺度和纵横比的锚框对边界框进行分类和回归,它只依赖于单一比例的图像和特征图,并使用单一尺寸的过滤器(特征图上的滑动窗口)
多尺度锚点的设计是在不增加寻址尺度成本的情况下实现特征共享的关键
Loss Function
我们对两种锚点分配了一个正标签:(i)与一个真值框有最高的交集超过联合(IoU)重叠的锚点/锚点,(ii)与任何真值框的IoU重叠大于0.7的锚点。请注意,一个ground-truth box可以为多个锚分配正面标签。通常第二个条件足以确定阳性样品;但我们仍然采用第一种条件,因为在极少数情况下,第二种条件可能找不到阳性样本
图像的损失函数定义为:
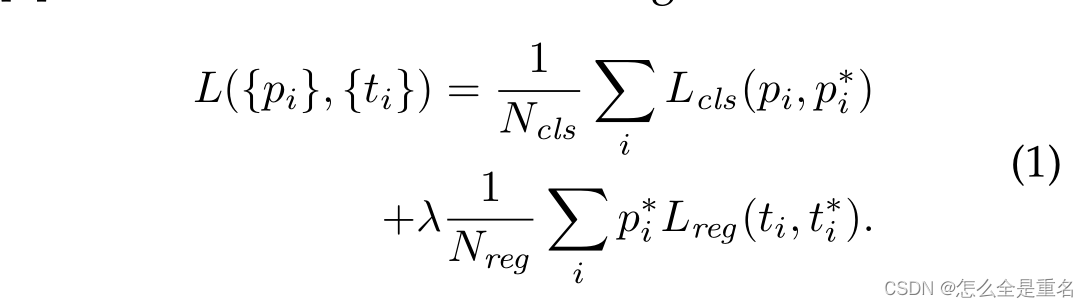
i是小批量中锚点的索引,pi是锚点i为对象的预测概率。如果锚点是正的,则真实标签pi为1,如果锚点是负的,则为0
ti是表示预测边界框的4个参数化坐标的向量,ti是与positive anchor相关联的真实框的向量
分类损失Lcls是两个类(对象与非对象)上的对数损失。对于回归损失,我们使用L reg (t i,t∗i) = R(t i−t∗i),其中R是[2]中定义的鲁棒损失函数
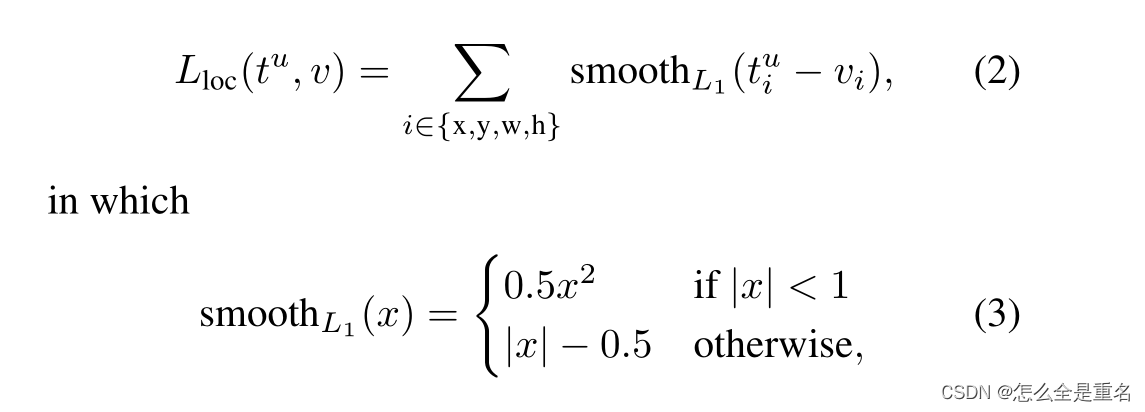
术语p∗i Lreg意味着回归损失仅对正锚点(p∗i = 1)激活,(p∗i = 0)禁用,cls和reg层的输出分别由{pi}和{ti}组成
这两项由Ncls和Nreg归一化,并由平衡参数λ加权。在我们当前的实现中(与发布的代码一样),Eqn.(1)中的cls项通过小批量大小(即N cls = 256)进行规范化,而reg项通过锚点位置的数量(即N reg ~ 2,400)进行规范化,默认情况下,我们设置λ = 10,因此cls和reg项的权重大致相等
对于边界盒回归,我们采用以下4个坐标的参数化:
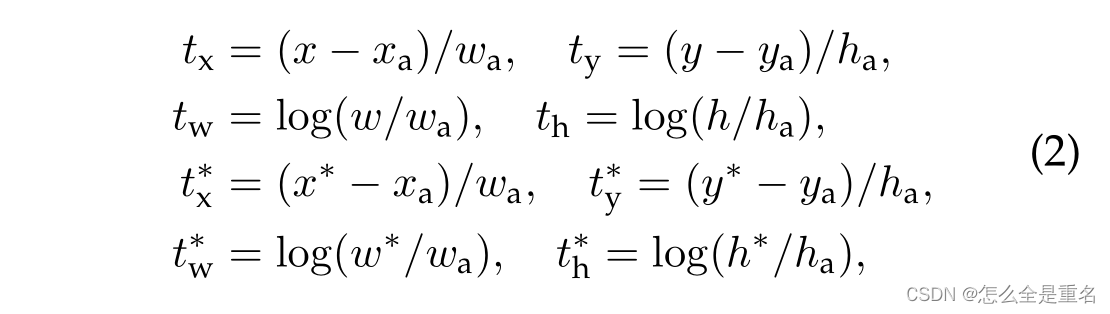
x, y, w和h表示盒子的中心坐标及其宽度和高度
变量x、xa和x*分别表示预测框、锚框和真值框(y、w、h也一样)
然而,我们的方法通过不同于先前基于RoI(兴趣区域)方法[1],[2]的方式实现了边界盒回归。在[1],[2]中,对任意大小roi池中的特征进行边界盒回归,所有区域大小共享回归权值
在我们的公式中,用于回归的特征在特征映射上具有相同的空间大小(3 × 3)。为了考虑不同的大小,我们学习了一组k个边界盒回归量。每个回归量负责一个尺度和一个纵横比,k个回归量不共享权重。因此,由于锚的设计,即使特征具有固定的尺寸/比例,仍然可以预测各种尺寸的box
Training RPNs
RPN可以通过反向传播和随机梯度下降(SGD)[35]进行端到端训练。我们从[2](Fast R-CNN)开始采用“以图像为中心”的采样策略来训练这个网络,每个小批都来自一个包含许多正面和负面例子锚点的单一图像
对所有锚点的损失函数进行优化是可能的,但这将偏向于负样本,因为它们占主导地位。相反,我们在一张图像中随机采样256个锚点来计算一个小批量的损失函数,其中采样的正锚点和负锚点的比例高达1:1。如果图像中阳性样本少于128个,我们就用阴性样本填充小批
我们通过从标准差为0.01的零均值高斯分布中绘制权重来随机初始化所有新层。所有其他层(即共享卷积层)都是通过对ImageNet分类[36]的模型进行预训练来初始化的,这是标准实践[5]。我们对ZF网络的所有层进行了调优,并对VGG网络进行了调优,以节省内存。在PASCAL VOC数据集上,我们对60k个小批次使用0.001的学习率,对接下来的20k个小批次使用0.0001的学习率。我们使用0.9的动量和0.0005[37]的重量衰减。我们的实现使用Caffe[38]
Sharing Features for RPN and Fast R-CNN
我们讨论了三种训练具有共享特征的网络的方法
(i) Alternating training:在这个解决方案中,我们首先训练RPN,并使用候选框来训练Fast R-CNN,然后使用Fast R-CNN调整的网络初始化RPN,并迭代此过程。这是本文所有实验中使用的解决方案
(ii) Approximate joint training:在这个解决方案中,RPN和Fast R-CNN网络在训练过程中被合并为一个网络,如图2所示。在每次SGD迭代中,正向传递生成候选区域,这些候选框在训练Fast R-CNN检测器时被视为固定的、预先计算的区域。反向传播像往常一样进行,其中对于共享层,来自RPN损耗和快速R-CNN损耗的反向传播信号被组合在一起。这个解决方案很容易实现。但该解决方案忽略了导数w.r.t.,候选框的坐标也是网络响应,因此是近似的,在我们的实验中,我们实证地发现这个求解器产生了接近的结果,但与交替训练相比,它减少了大约25-50%的训练时间
(iii) Non-approximate joint training:在非近似联合训练解中,我们需要一个RoI池化层,该层相对于方框坐标是可微的。这是一个不简单的问题,可以通过[15]中开发的“RoI warping”层来解决
4步交替训练
本文采用一种实用的四步训练算法,通过交替优化来学习共享特征
在第一步中,我们按照第3.1.3节的描述训练RPN,该网络使用imagenet预训练模型初始化,并对区域生成任务进行端到端微调
在第二步中,我们使用第一步RPN生成的建议,通过Fast R-CNN训练一个单独的检测网络,该检测网络也由imagenet预训练模型初始化,在这一点上,两个网络不共享卷积层
在第三步中,我们使用检测器网络初始化RPN训练,但是我们固定了共享的卷积层,并且只微调了RPN独有的层
现在这两个网络共享卷积层
最后,在保持共享卷积层固定的情况下,我们对Fast R-CNN的独特层进行微调。因此,两个网络共享相同的卷积层,形成一个统一的网络。类似的交替训练可以运行更多的迭代,但我们观察到的改进微不足道
实验
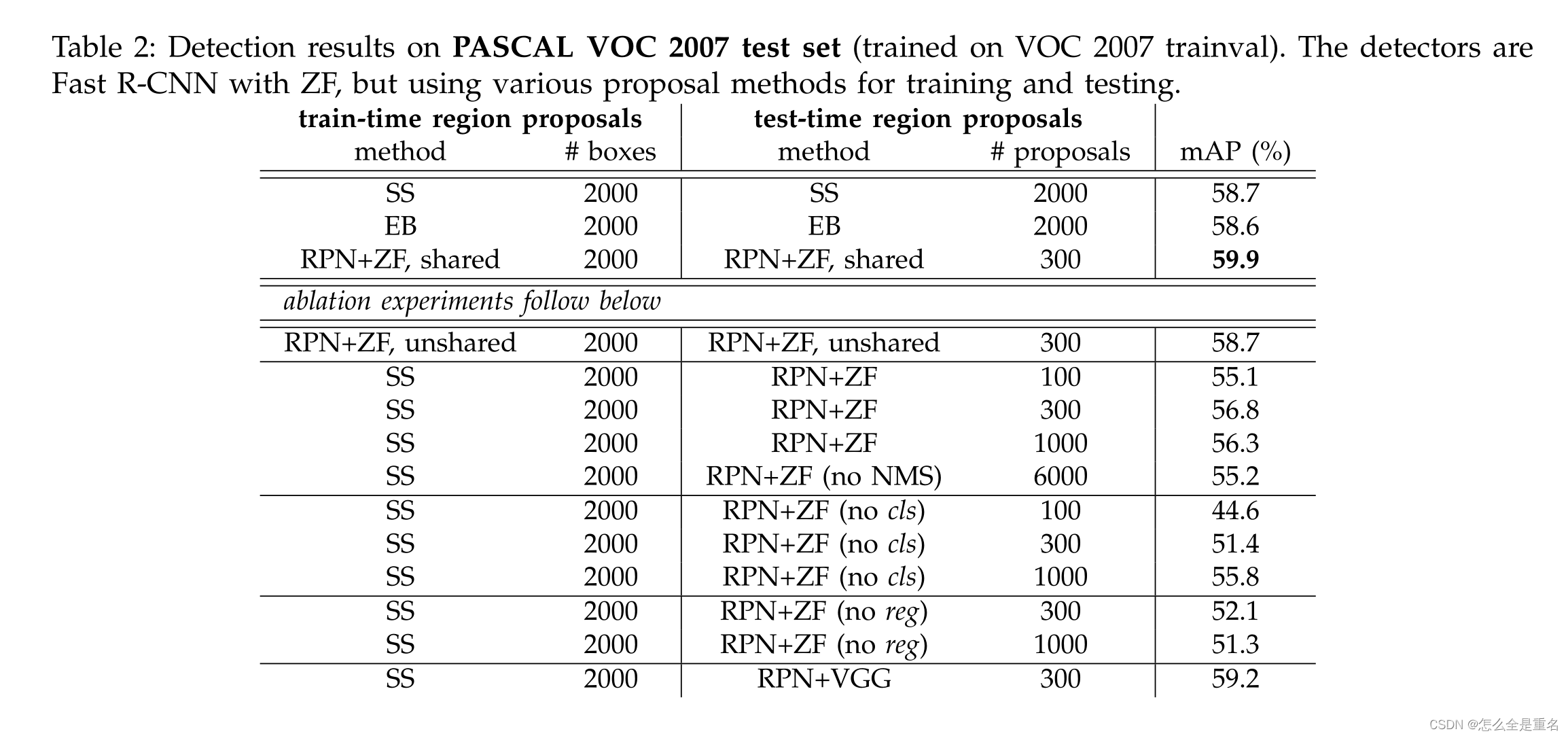
在PASCAL VOC 2007测试集上的检测结果(在VOC 2007训练集上训练)。检测器是快速R-CNN与ZF,但使用各种篇proposal的方法进行训练和测试
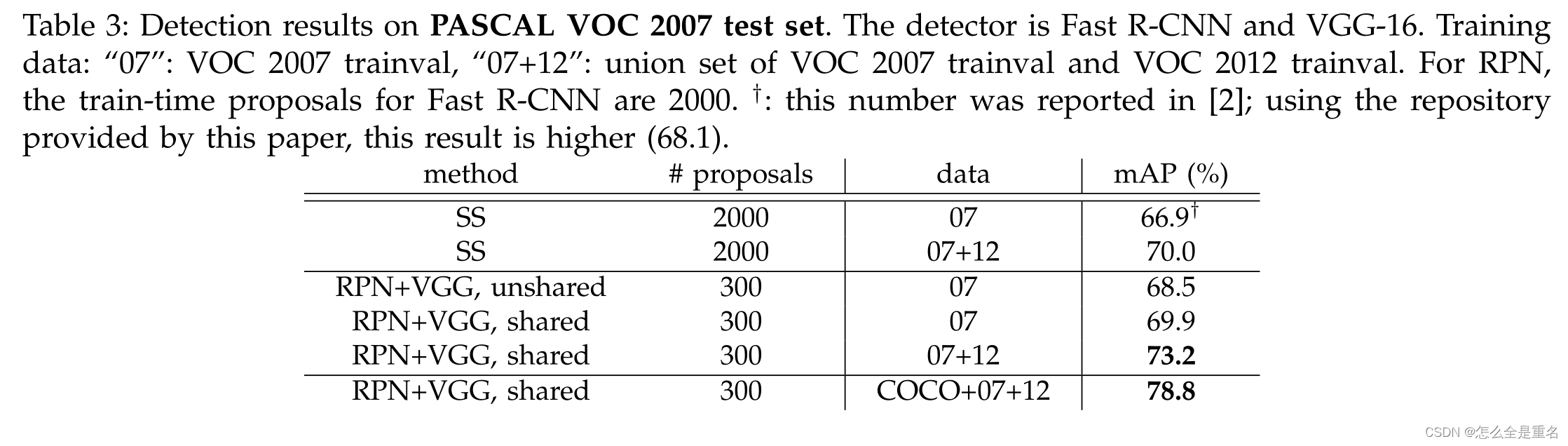
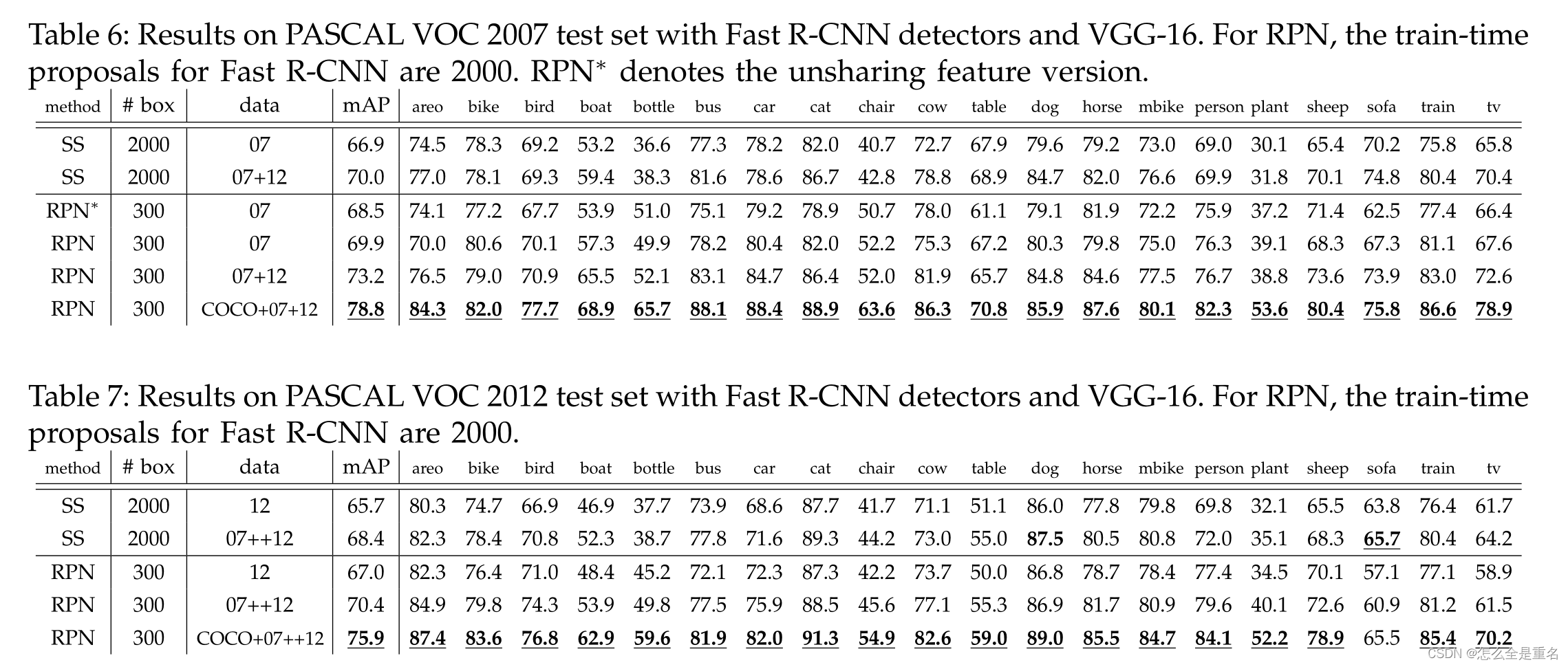
PASCAL VOC 2007测试集的检测结果。探测器是Fast R-CNN和VGG-16
PASCAL VOC 2012测试集的检测结果,探测器是Fast R-CNN和VGG-16



结论
我们提出了RPN,用于高效、准确地生成区域候选框。通过与下游检测网络共享卷积特征,区域生成步骤几乎是无成本的。我们的方法使统一的、基于深度学习的目标检测系统能够以接近实时的帧速率运行
学习到的RPN还提高了区域候选框的质量,从而提高了整体目标检测的准确性
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









