







 本文介绍了一种新颖的BAGS模块,用于解决深度学习模型中长尾大型词汇物体检测的类别不平衡问题。实验结果显示,BAGS在LVIS和COCO-LT数据集上显著提升低样本类别性能,创下了新纪录。
本文介绍了一种新颖的BAGS模块,用于解决深度学习模型中长尾大型词汇物体检测的类别不平衡问题。实验结果显示,BAGS在LVIS和COCO-LT数据集上显著提升低样本类别性能,创下了新纪录。

原文
代码
Abstract
本文探讨了在深度学习模型中解决长尾大型词汇物体检测的问题。作者发现现有的检测方法无法处理极度倾斜的数据集中的少数类别的问题,导致分类器不平衡。直接将长尾分类模型应用到检测框架中并不能解决问题,因为检测和分类之间存在本质差异。
为了解决这个问题,作者提出了一个新颖的平衡组softmax(BAGS)模块,通过分组训练来平衡检测框架中的分类器。该模块可以对头部和尾部类别进行隐式调节,并确保它们都得到充分训练,而无需额外采样来自尾部类别的实例。实验结果表明,BAGS显著提高了各种骨干网络和框架在对象检测和实例分割方面的性能,在非常新的长尾大型词汇物体识别基准LVIS上建立了新的最佳记录。

Method
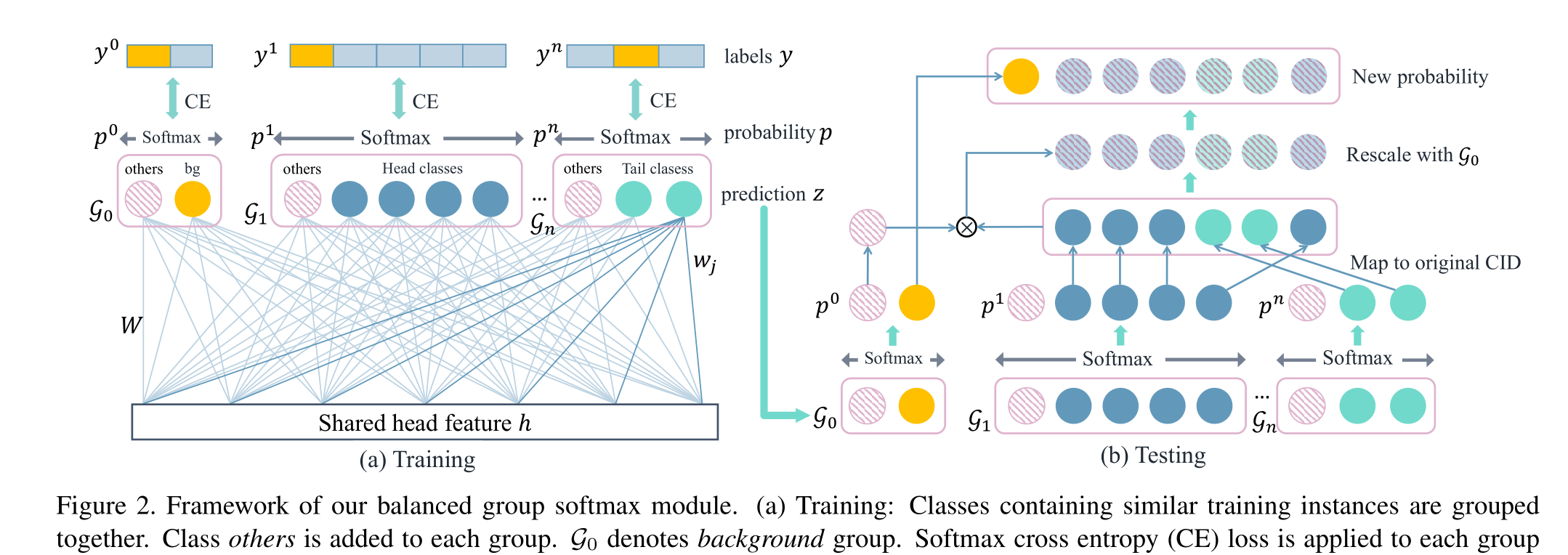
该论文提出了一种名为Balanced Group Softmax的新模块,用于解决在长尾数据集上训练检测模型时由于类别不平衡导致的性能下降问题。该模块通过将类别分为不同的组,并分别使用softmax或sigmoid交叉熵损失函数进行训练,从而平衡了每个类别的权重。此外,该模块还引入了一个“others”类别来缓解测试阶段可能出现的错误预测问题。综上,该模块解决了在长尾数据集中训练检测模型时出现的类别不平衡问题
相较于传统的改进
传统的两阶段检测框架中,分类器通常是基于全连接层和softmax激活函数设计的。然而,在长尾数据集中,类别之间的数量差异会导致某些类别的权重被抑制,从而使检测器无法正确识别这些类别。为了解决这个问题,Balanced Group Softmax模块将类别分为多个组,并在每个组内使用softmax或sigmoid交叉熵损失函数进行训练。这样可以确保每个组内的类别具有相似的数量,从而避免了类别之间的不均衡竞争。
此外,该模块还引入了一个“others”类别,用于处理测试阶段可能出现的错误预测问题。在每个组内,“others”类别代表其他组中的类别,包括背景类别和其他前景类别。通过对“others”类别的概率进行调整,可以减少错误预测的概率。
Experiment
作者在LVIS和COCO-LT数据集上进行了长尾分类和检测任务中的实验,并与现有的方法进行了比较。实验包括以下几个方面:
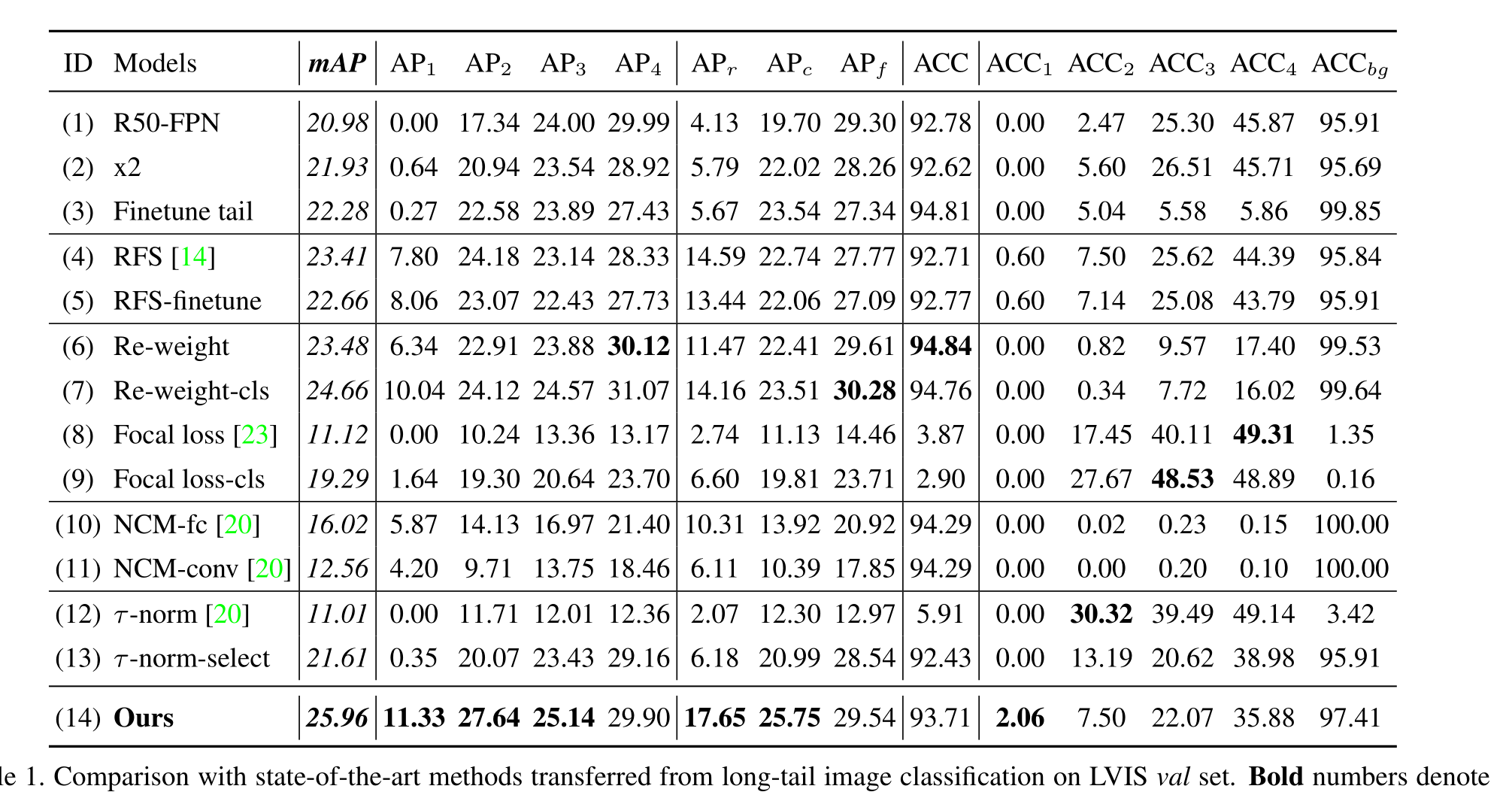
对于LVIS数据集上的长尾分类任务,作者尝试了多种现有的长尾分类方法,并将其应用于Faster R-CNN框架中。结果表明,这些方法对于低样本类别的识别效果有限,而作者提出的BAGS模块可以在不增加训练时间的情况下显著提高模型对低样本类别的识别能力。
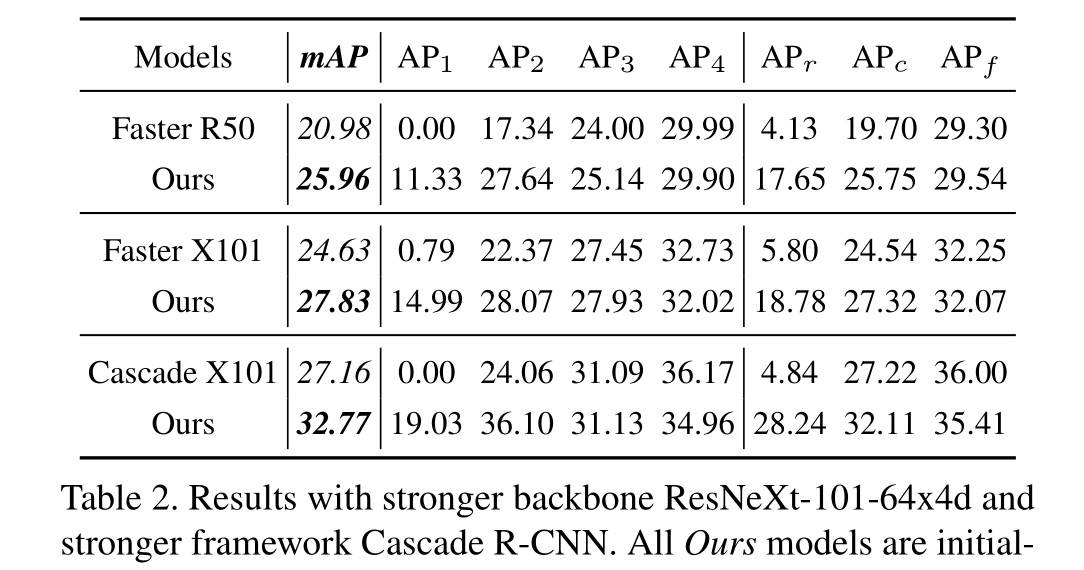
在LVIS数据集上的长尾检测任务中,作者将BAGS模块应用于Faster R-CNN和Mask R-CNN框架中,并与其他现有方法进行了比较。结果表明,BAGS模块可以显著提高模型对低样本类别的检测能力,并且在实例分割任务中也取得了很好的效果。
在COCO-LT数据集上的实验进一步验证了BAGS模块的有效性,并证明了其具有较好的泛化能力。
创新点
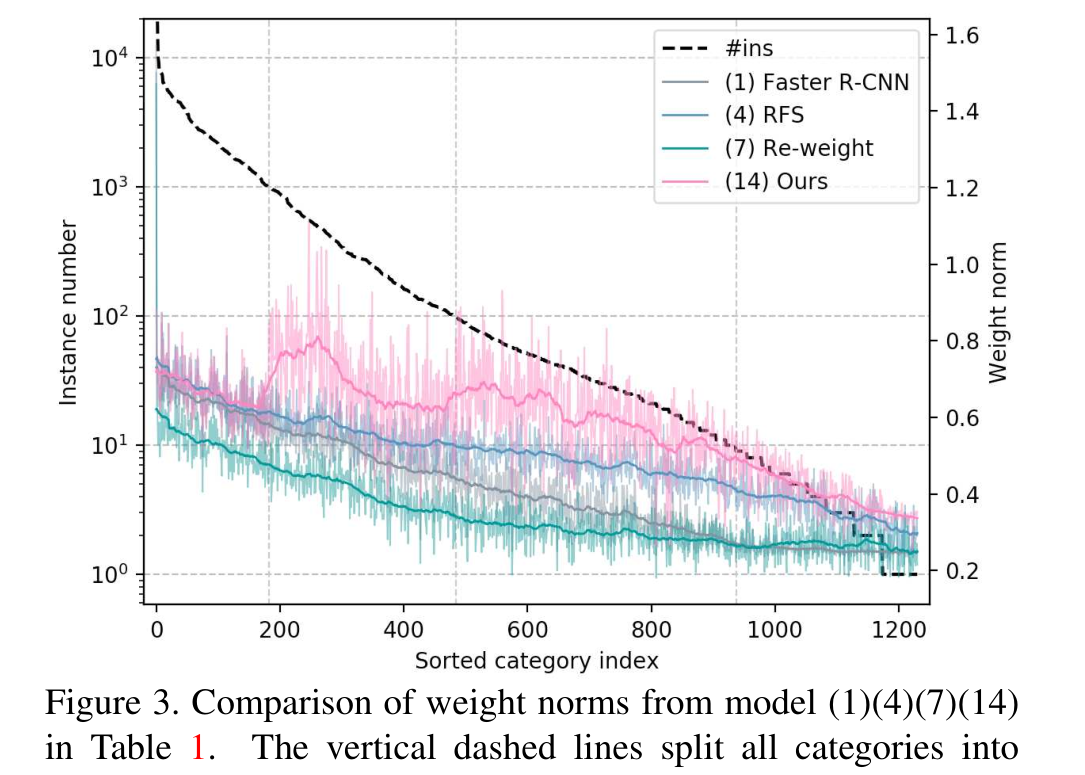
提出了一个新颖的方法——平衡组softmax(BAGS),以解决长尾检测中分类器不平衡的问题。该方法将具有相似训练实例数量的对象类别分为同一组,并分别计算组内softmax交叉熵损失。
此外,为了解决假阳性问题,该方法还将背景和其他类别单独分组。这种创新性的方法使得模型能够更好地处理长尾数据,并取得了很好的效果















 891
891

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









