







TextRNN & FastText & TextCNN-03-模型总览,后
训练要点
RNN训练
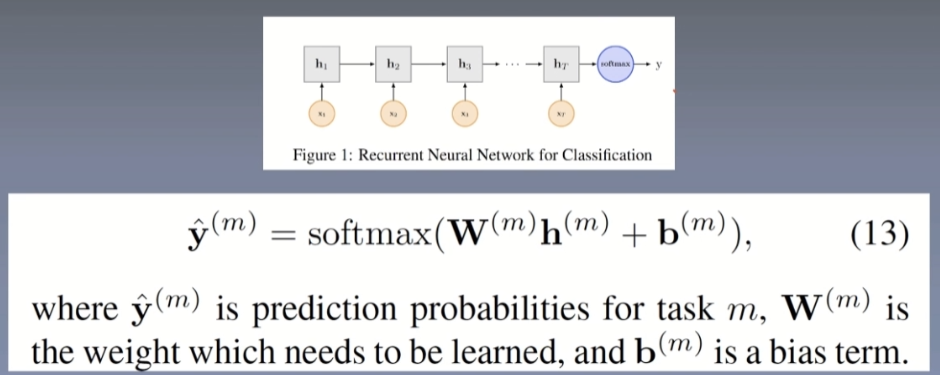
得出来的y(m)(预测标签)是每一个分类的概率,比如是一个五分类,化成5个格子,每一个格子是概率,5个格子加起来是1
损失

有多任务怎么计算loss,通过一个线性的一个变换来将所有的这些loss累加到一起。
大M就是代表我们有多少任务,比如我们有4个数据集,M就等于4
λm是权重,4个任务的权重不一样
数据的选择

训练方法:
1.随机选择一项任务;
2.从该任务中随机选择一个训练样本;
3.根据基于梯度的优化
(paper 中使用 Adagradupdate rule)来更新参数;
4.重复 1-3 步。
微调

预训练

对于模型三来说,共享层可以用所有的任务数据(4个数据集)进行预训练。模型三就可以获得四个数据集的所有信息。
用无监督的方法去预训练一些信息。
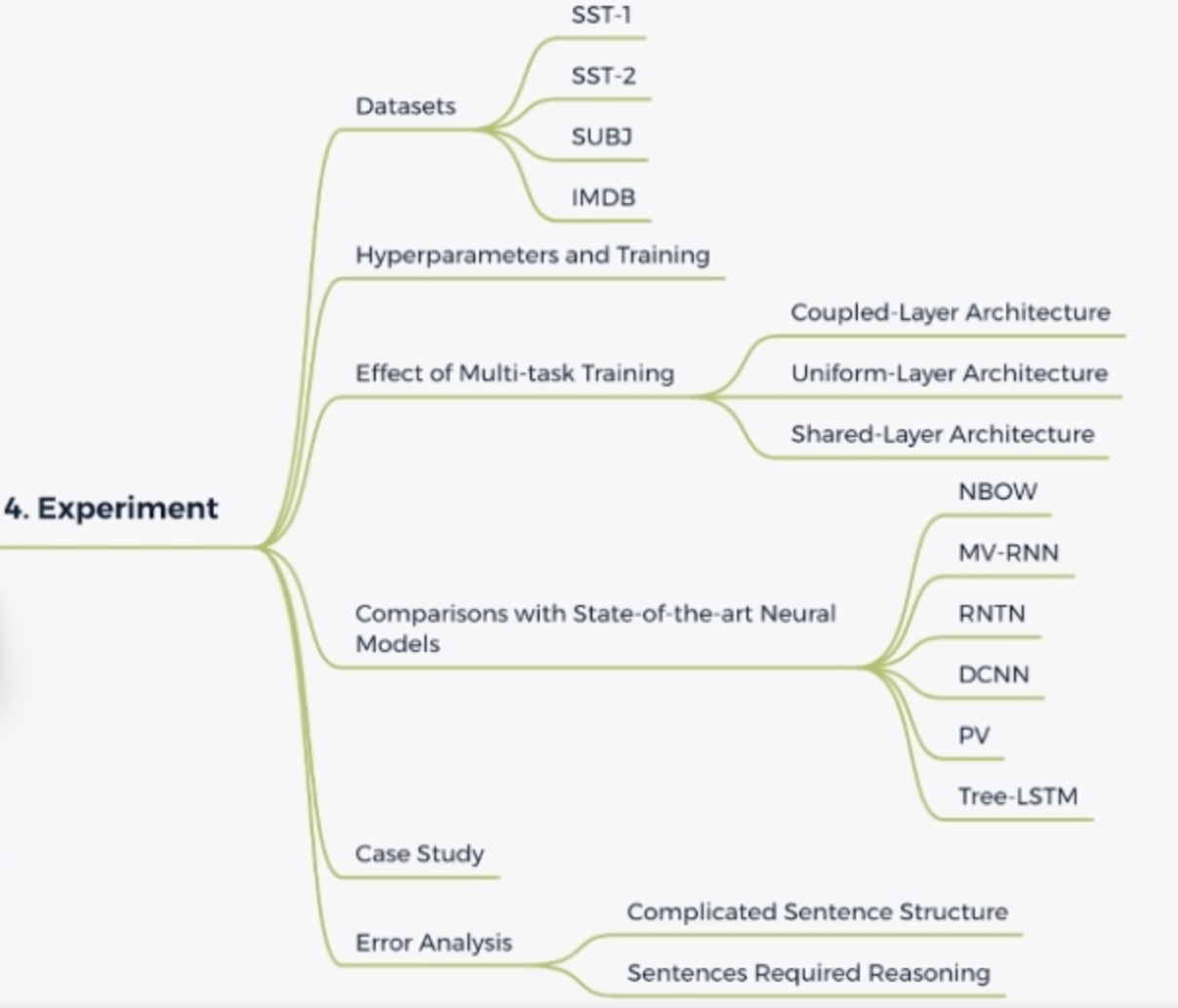
实验设置和结果分析
实验结果和分析知识树
数据集
4个数据集
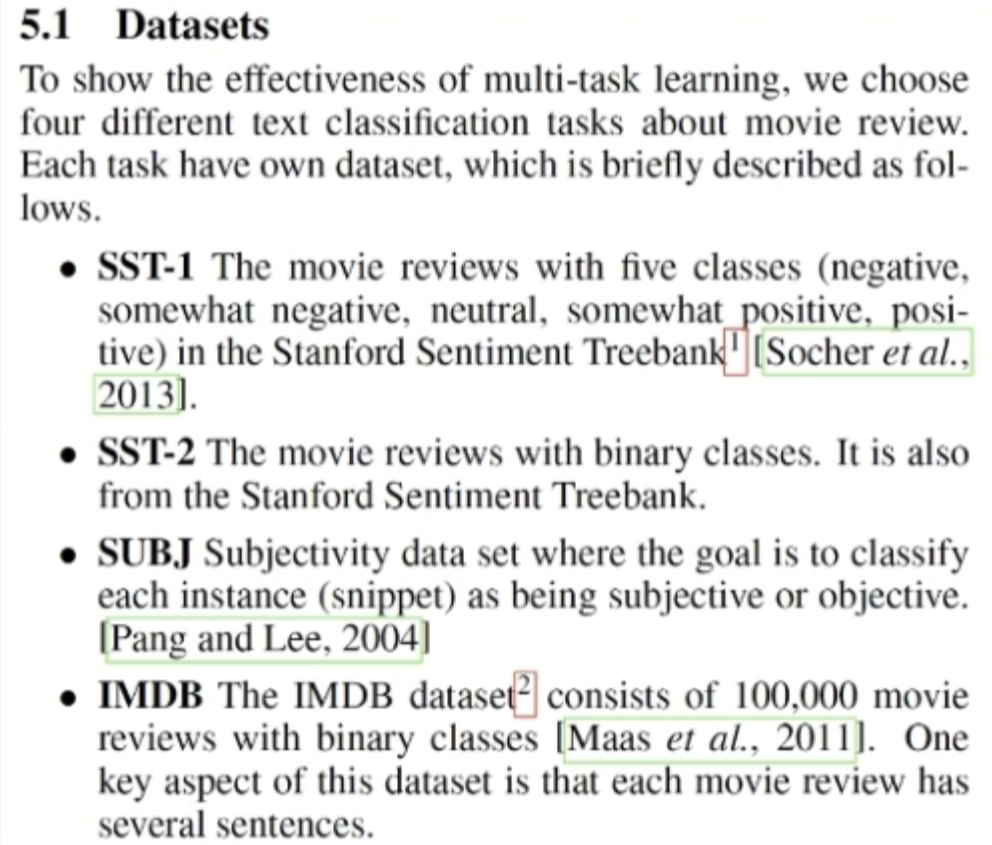
SST-1:5个情绪类别的电影影评,来自斯坦福情感数据库
SST-2:2分类电影影评,来自斯坦福数据库
SUBJ:主观性数据集,任务目的是将句子分为主观和客观
IMDB:2分类的电影影评,大多数评价为长句子
数据的对比

超参与训练

使用 word2vec在维基语料获得词向量,字典规模约 500,000。词嵌入在训练过程中被微调以提高性能;其他参数在[-0.1,0.1]的范围随机采样,超参数将选择在验证集上性能最好的一组。对于没有验证集的数据集使用 10 折交叉验证。
特定任务和共享层的嵌入大小为 64。对于模型一,每个单词有两个嵌入,大小都为 64。
LSTM 的隐藏层大小为 50。初始学习率为0.1。参数的正则化权值为 10^-5.















 280
280











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









