







梗概
主题:VO in Dynamic
思路
简答介绍SLAM框架,引入VO问题
直接从Learned VO开始,介绍VO问题的相关研究,总结当前研究存在的问题
讨论Dynamic VO中的相关做法,总结问题,提出想法
拓展VO 和navigation的关系
引入
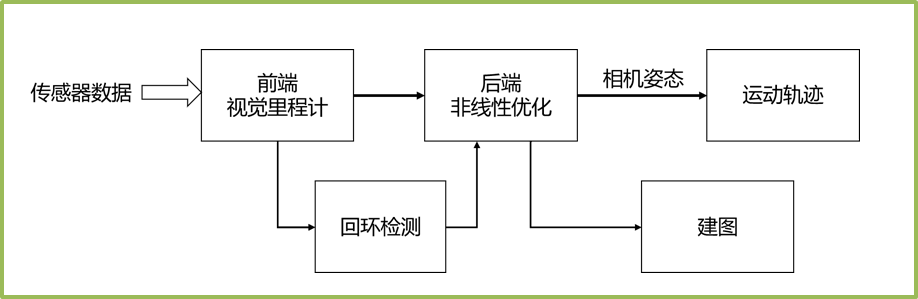
SLAM的全称是Simultanous Location And Mapping,同步定位与建图,其任务的目的在于基于传感器的数据实现运动轨迹估计和建图任务。其中以相机作为传感器的SLAM系统成为VSLAM系统,其系统的经典架构如图所示。
在VSLAM系统,前端的视觉里程计根据传感器的信息估算相邻图像间相机的运动,以及局部地图的构建,其只有简单的位姿估计功能,不具备定位、导航、交互等复杂功能,只能存储局部状态。后端(Back End)接受VO测量的相机位姿及回环检测的信息,并对他们进行优化,得到一个全局一直的轨迹和地图,简单来说就是用来减小累积误差。后端优化当前主要采用非线性优化(BA和图优化)。回环用来判断机器人是否达到过先前的位置,如果检测到回环则发送给后端处理,是减小累积误差的关键。
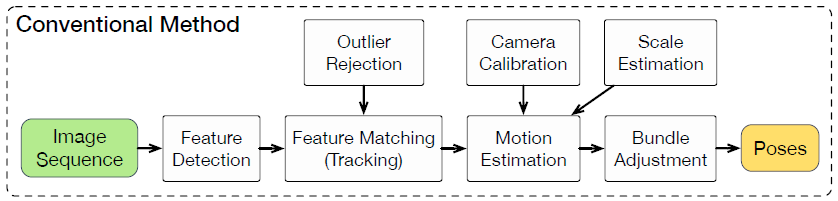
视觉里程计模块是整个SLAM系统的基础,大多数VO算法都是在标准流程下开发的,包括特征提取、特征匹配、运动估计、局部优化等。
虽然其中一些算法已经表现出优越的性能,但它们通常需要仔细设计和专门微调才能正常工作在不同的环境中。恢复单目 VO 的绝对尺度还需要一些先验知识。
Learned VO
DeepVO (ICRA2017)
论文:DeepVO Towards End-to-End Visual Odometry with Deep Recurrent Convolutional Neural Networks(ICRA2017)
动机
大多数现有VO方法在不同环境下需要专门设计和特殊的微调,需要一定的先验知识才能恢复单目VO的绝对尺度
Contribution
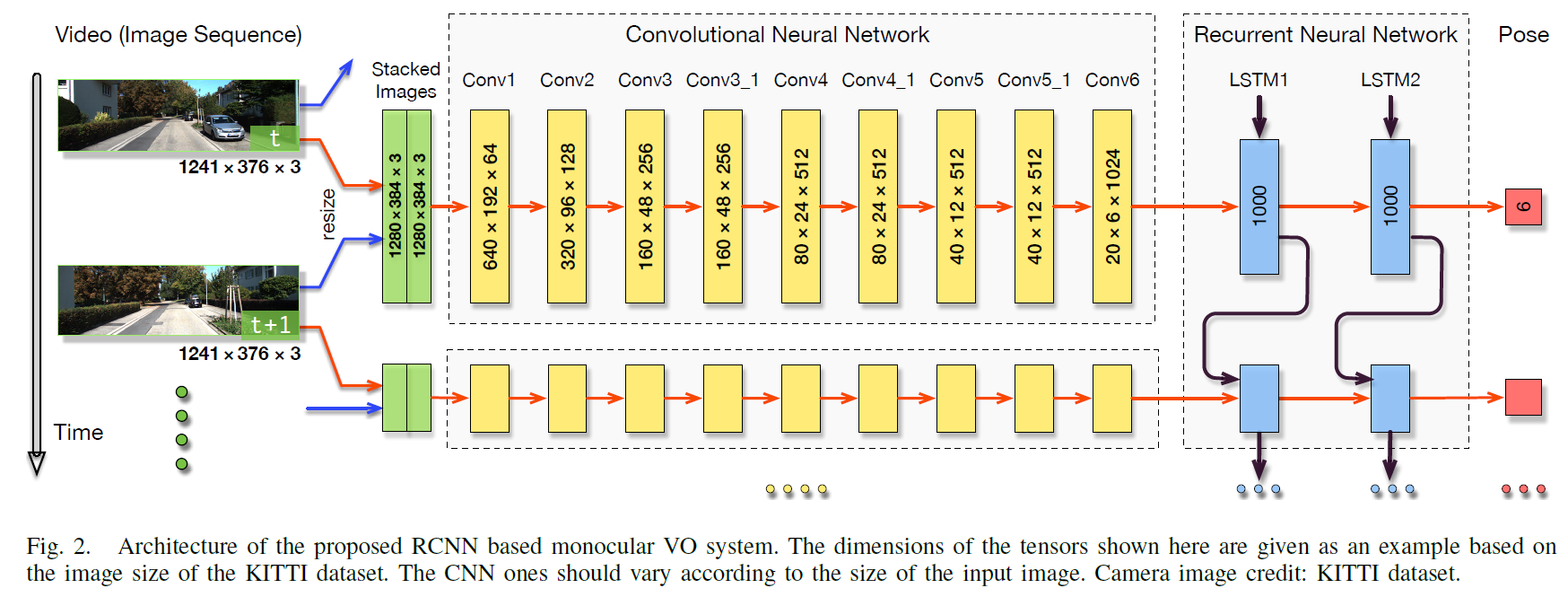
1)证明单目VO问题可以通过基于深度学习的端到端方式解决,即直接从原始 RGB 图像估计姿势。恢复绝对尺度既不需要先验知识也不需要参数。
2)提出了一种 RCNN 架构,通过使用 CNN 学习的几何特征表示,能够将基于 Deep Learning 的 VO 算法推广到全新的环境。
Loss
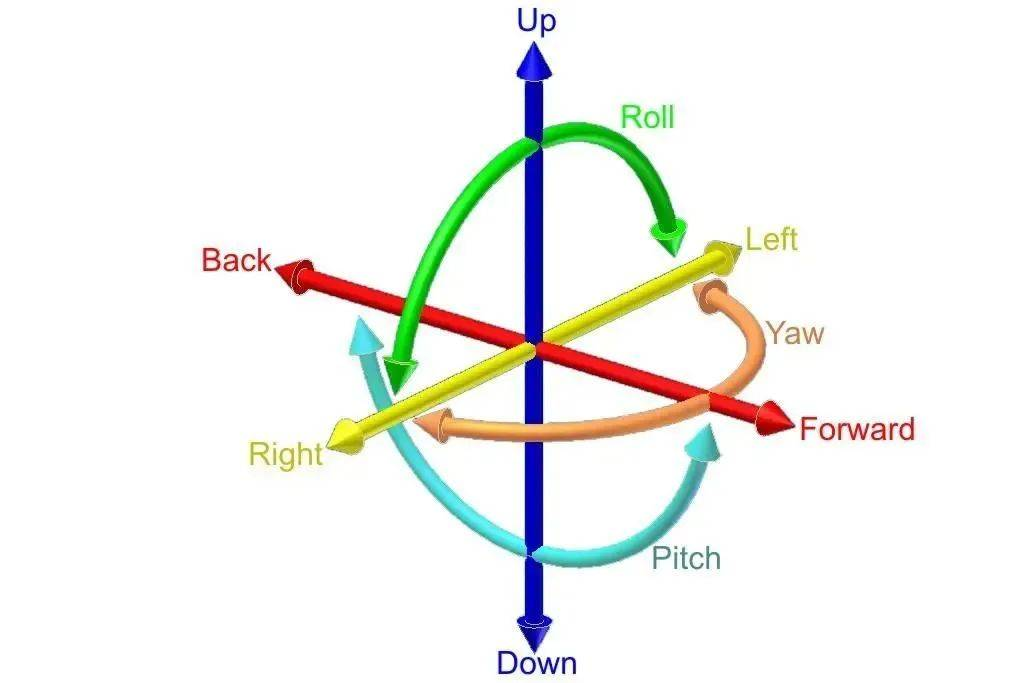
描述相机姿态采用的是6Dof的形式
[
θ
x
,
θ
y
,
θ
z
,
x
,
y
,
z
]
[\theta _x,\theta _y, \theta _z, x,y,z]
[θx,θy,θz,x,y,z],一般SLAM系统中采用的是
[
R
∣
T
]
[R|T]
[R∣T]转换矩阵。
最小化函数,直接使用MSE(均方误差)
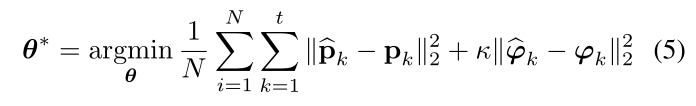
experiment
数据集
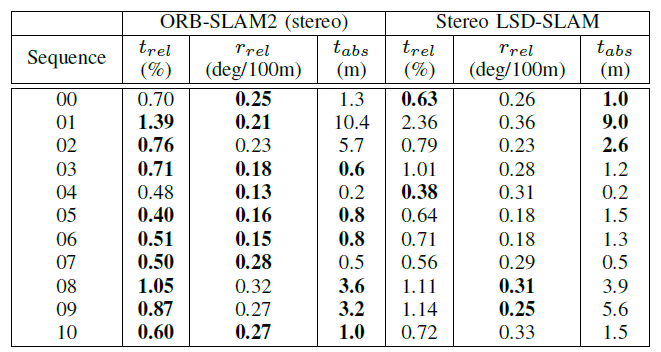
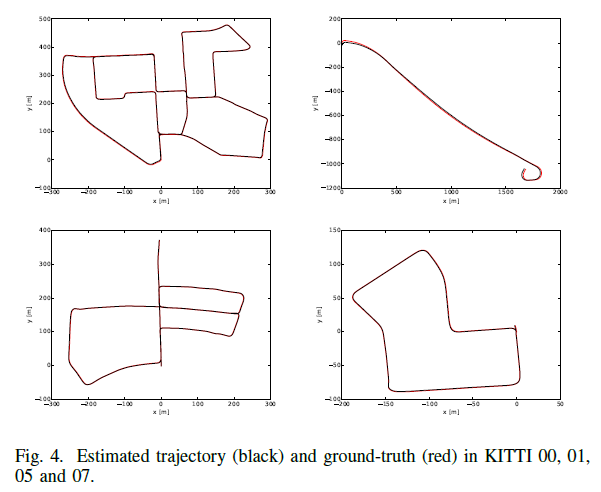
KITTI 数据集上进行的测试
对于VO任务而言,一共有22条路径,只有(00-10)有真值

比较的方法
VISO2 是ROS中提供的一个视觉里程计工具包,方法是经典的SLAM方法
结果
00、02、08、09用于训练,03、04、05、06、07、10用于测试
将轨迹分割成不同的长度,以生成大量的训练数据,总共产生 7410 个样本。


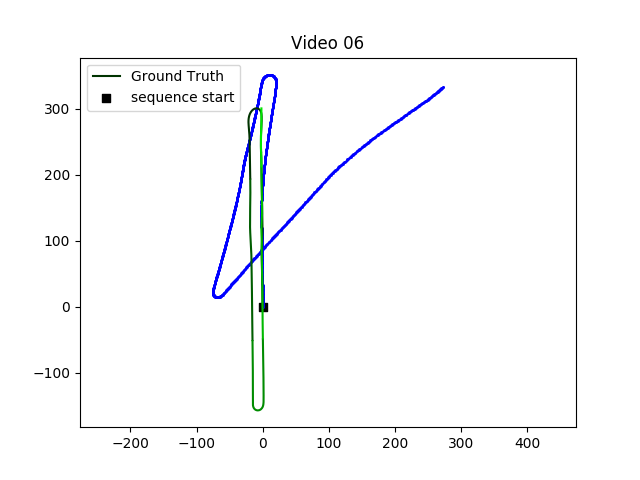
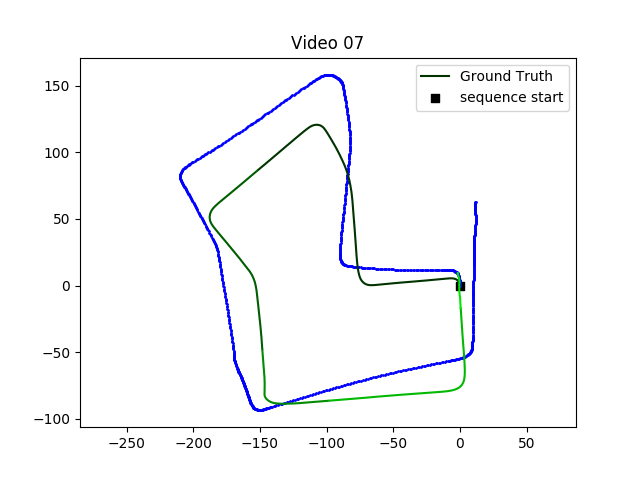
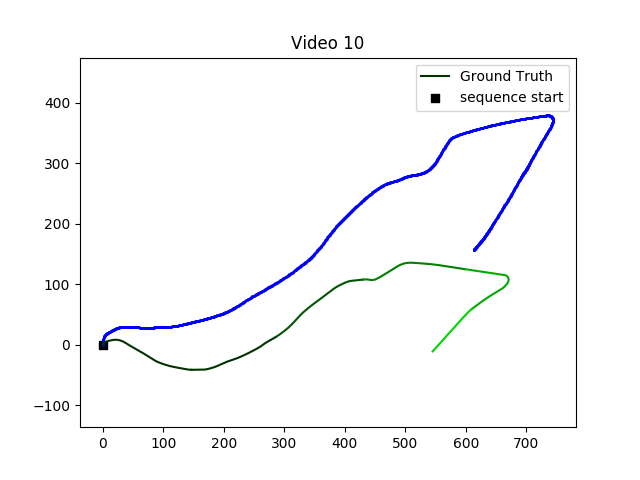
精度比不上经典方法
结论
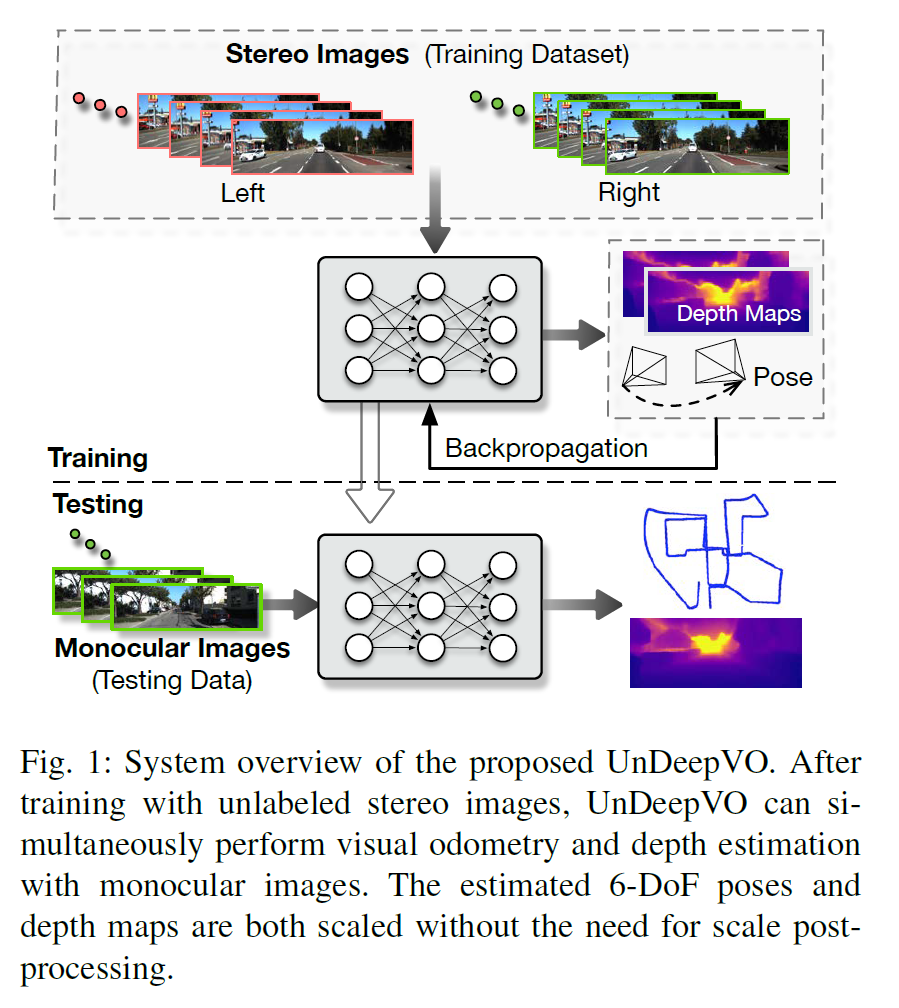
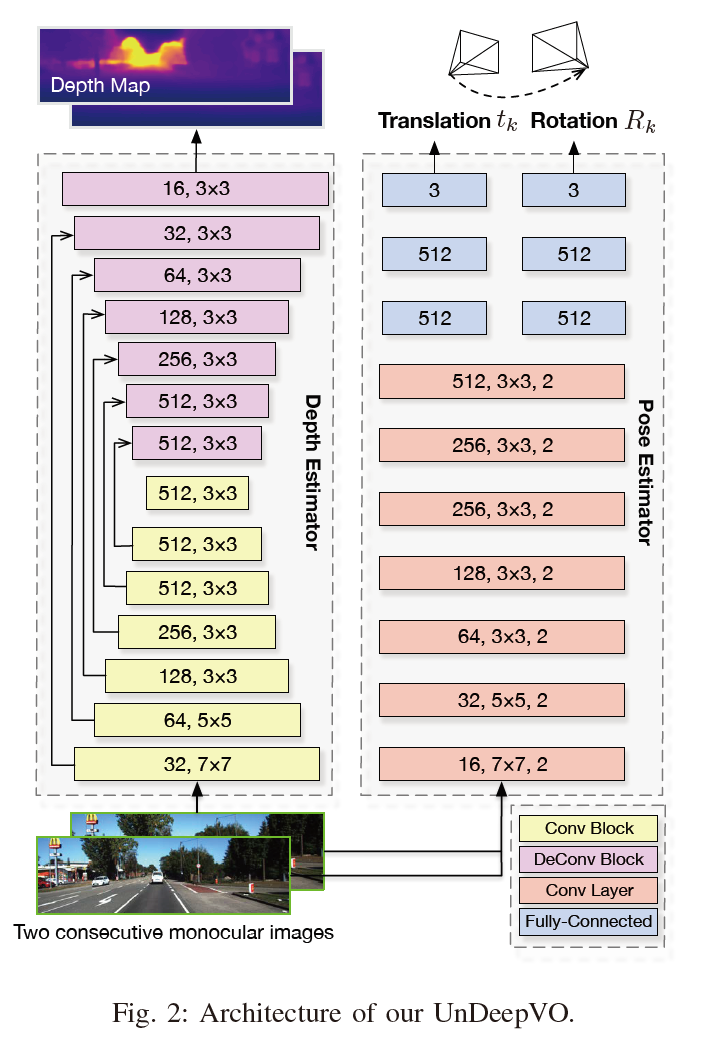
UnDeepVO (ICRA2018)
论文:UnDeepVO: Monocular Visual Odometry through Unsupervised Deep Learning(ICRA2018)
动机

Contribution
1.展示了一个具有恢复的绝对尺度的单目VO系统,并通过利用空间和时间几何约束以无监督的方式实现了这一点。
2.由于在训练过程中使用了立体图像对,不仅生成了估计的姿态,而且还生成了具有绝对比例的估计的密集深度图
Loss
Spatial Image Losses
双目视差深度估计原理
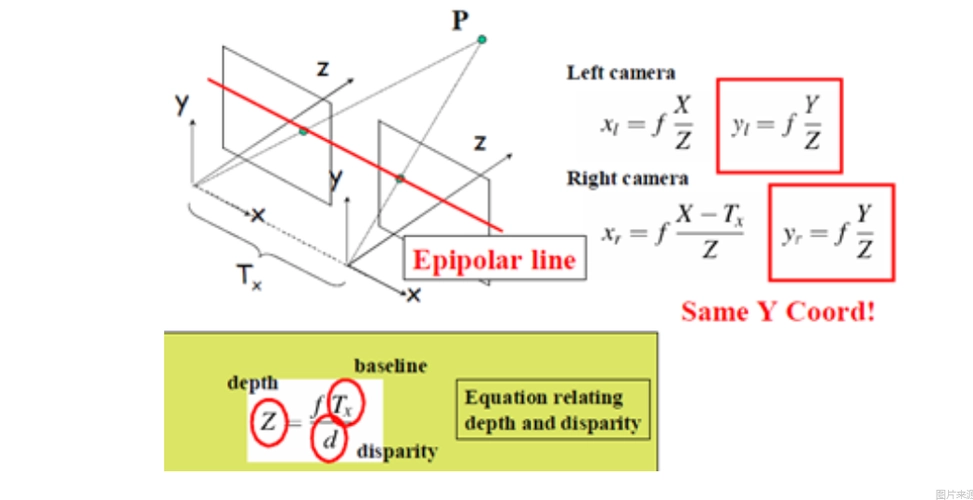
Photometric Consistency Loss:(光度一致性损失)
I
l
‘
I^{`}_l
Il‘是用STN(Spatial transformer networks)网络进行变换的

Disparity Consistency Loss

Pose Consistency Loss:

Temporal Image Losses
Photometric Consistency Loss:

3D Geometric Registration Loss:

最后的损失为所有的损失之和
experiment
比较:SfMLearner、VISO2、ORBSLAM
SfMLearner(Structure from Motion Learner)是一种用于自监督学习的计算机视觉方法,其主要目标是从单个图像中学习场景的三维结构信息,同时估计相机的位姿,从而实现从图像到深度图和相机运动的自动估计。
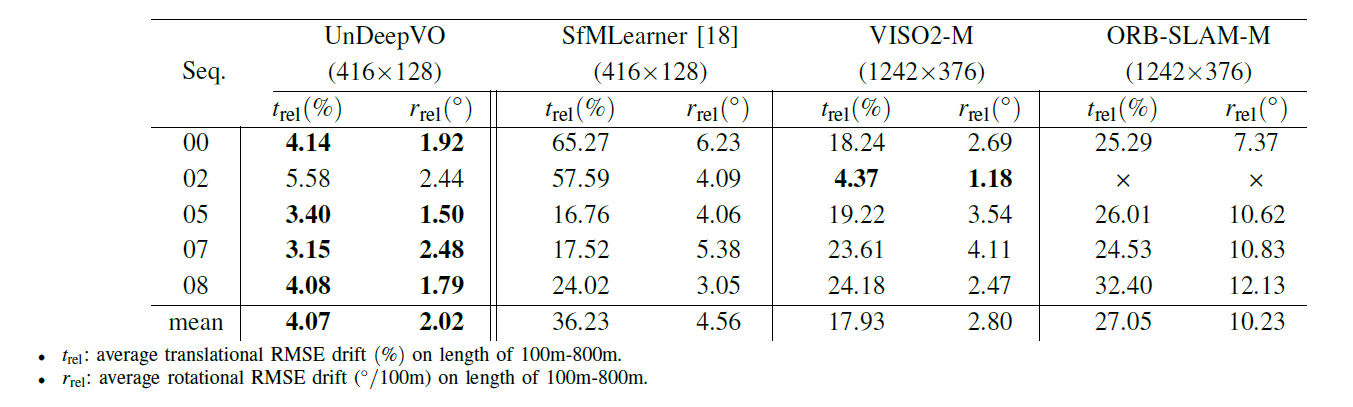
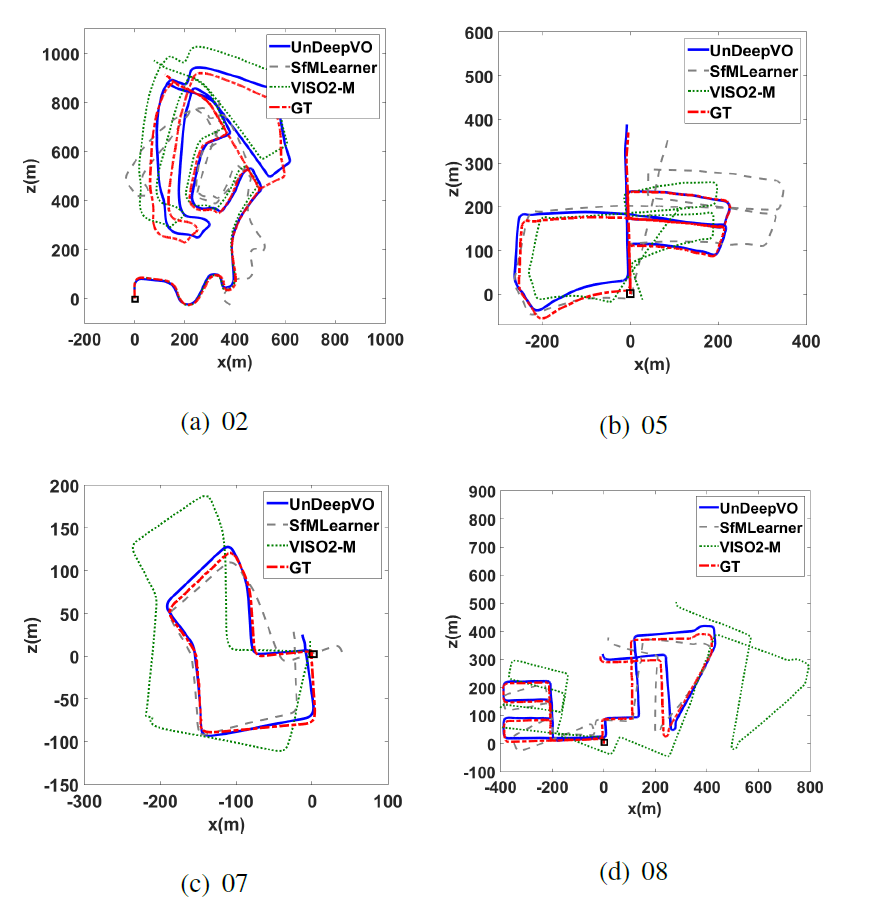
结论
1.证明通过利用空间和时间几何约束以无监督的方式可以实现一个具有恢复的绝对尺度的单目VO系统。
2.在训练过程中使用了立体图像对,不仅生成了估计的姿态,还可以生成了具有绝对比例的估计的密集深度图
RNN for VOD (CVPR 2019)
论文:Recurrent Neural Network for (Un-)supervised Learning of Monocular Video Visual Odometry and Depth(CVPR2019)
Contribution
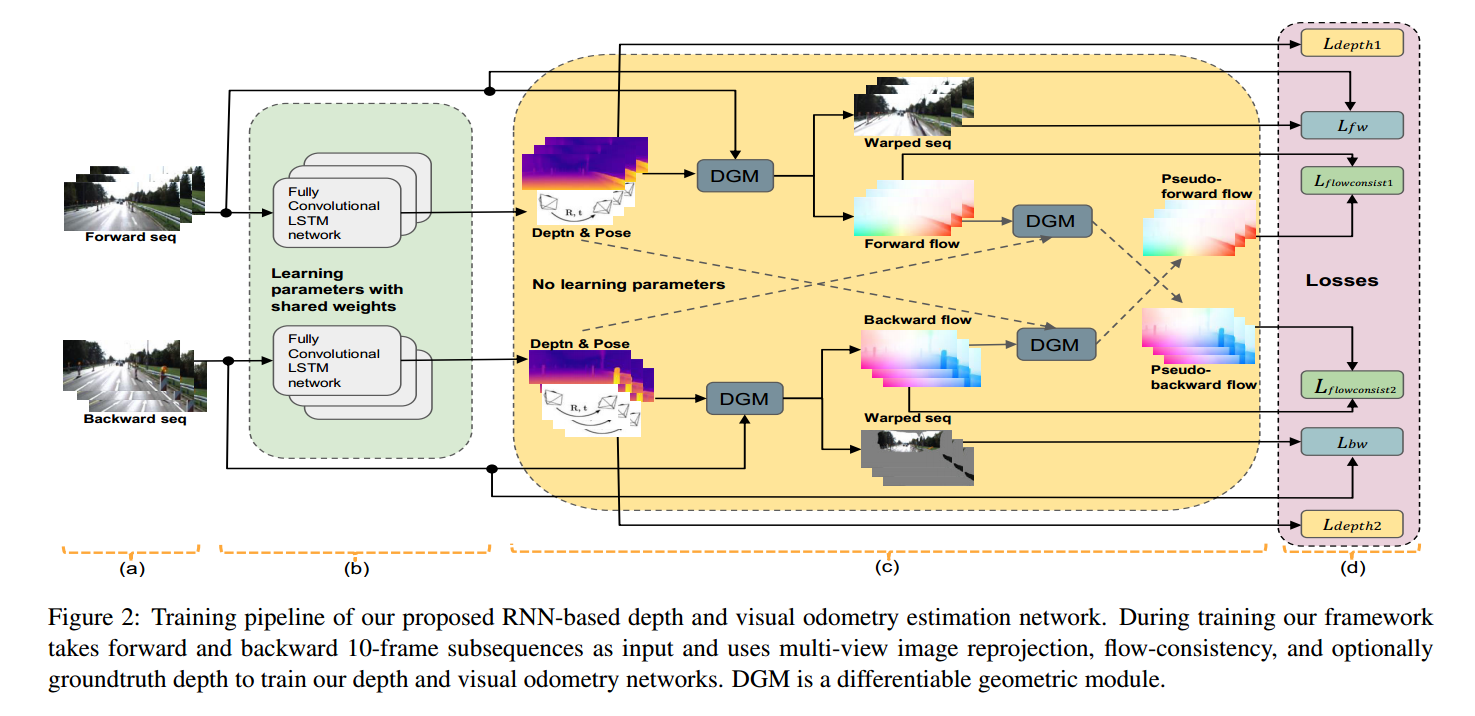
- 提出了一个使用多个连续视图的单目深度和里程计估计的 RNN 架构。
- 重要的是,这些 LSTM 单元允许使用深度和相机运动估计进行创新,从而受益于多视图过程的更丰富的约束。特别是,他们使用多视图图像重投影和前后流一致性约束来生成更准确和一致的模型。
- 这种设计允许两种新颖的功能:
a)它可以以监督和无监督的方式进行训练;
b) 它可以连续运行任意长度的序列,提供一致的场景比例。
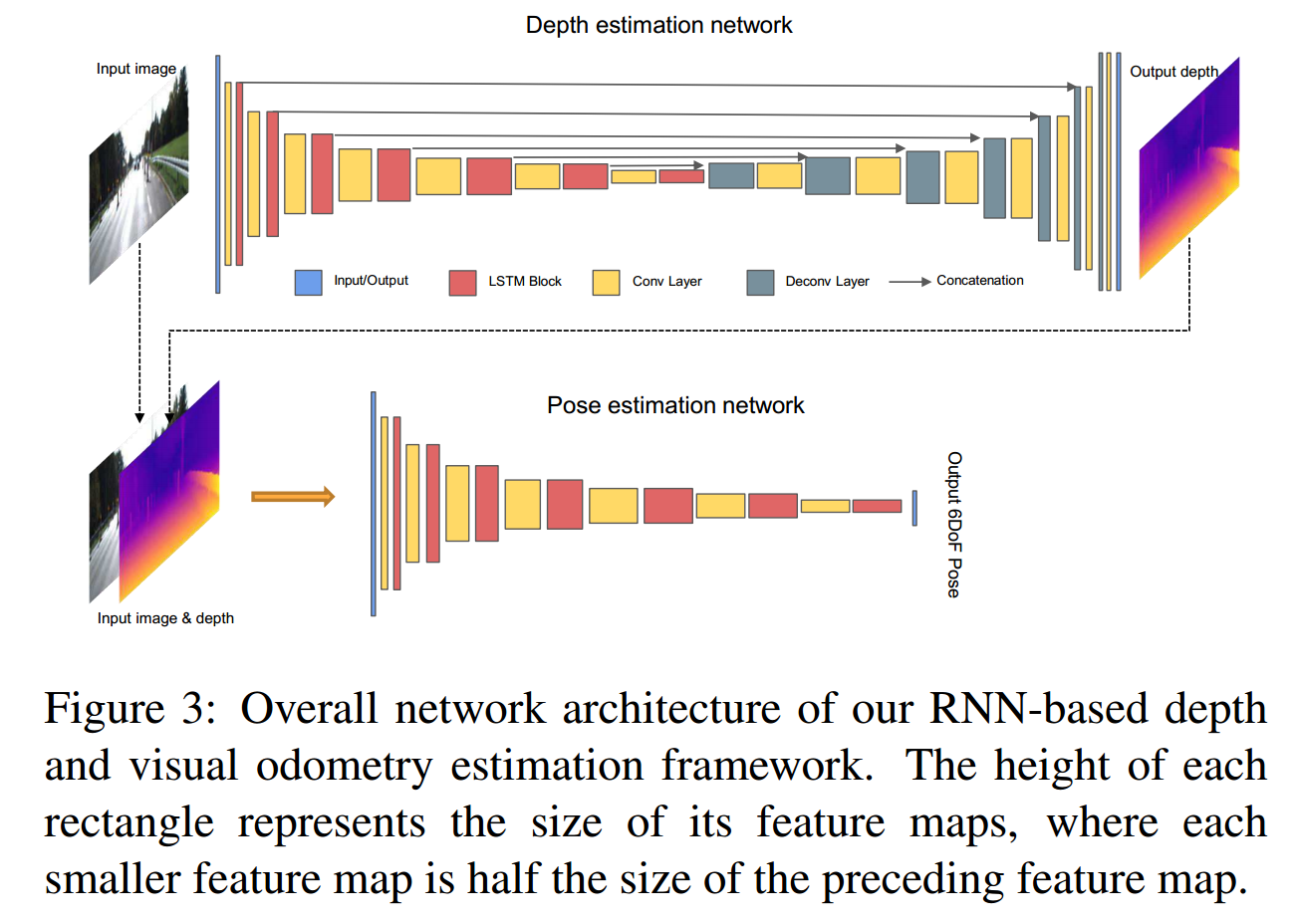
depth estimation network使用的是一个类似于DispNet的U型网络结构,我们的主要创新是将循环单元交织到编码器中,这使得网络在深度估计中不仅可以利用空间信息,还可以利用时间信息。然后将编码器计算的时空特征输入解码器以进行准确的深度图重建。

visual odeometry network 使用的是VGG16,我们的视觉里程计网络与当前大多数基于深度学习的视觉里程计方法之间的主要区别是:1)在每个时间步,我们的视觉里程计网络仅将当前图像作为输入,而不是一堆帧;有关先前帧的知识位于隐藏层中。 2)我们的视觉里程计网络还将当前的深度估计作为输入,这确保了深度和相机姿态之间一致的场景比例(对于比例不明确的无监督深度估计很重要)。 3)我们的视觉里程计网络可以在完整的视频序列上运行,同时保持单个场景比例。
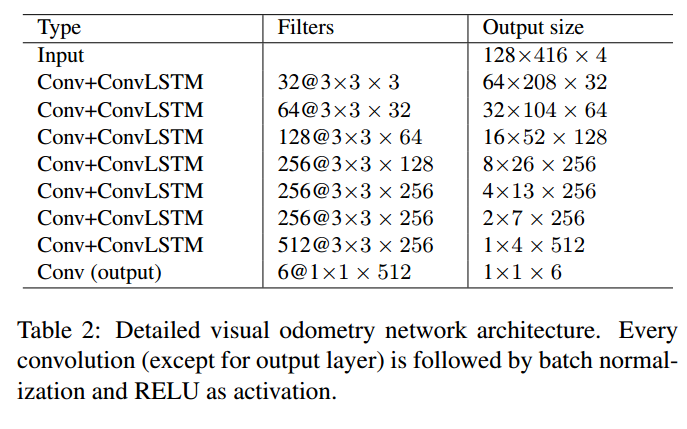
Loss
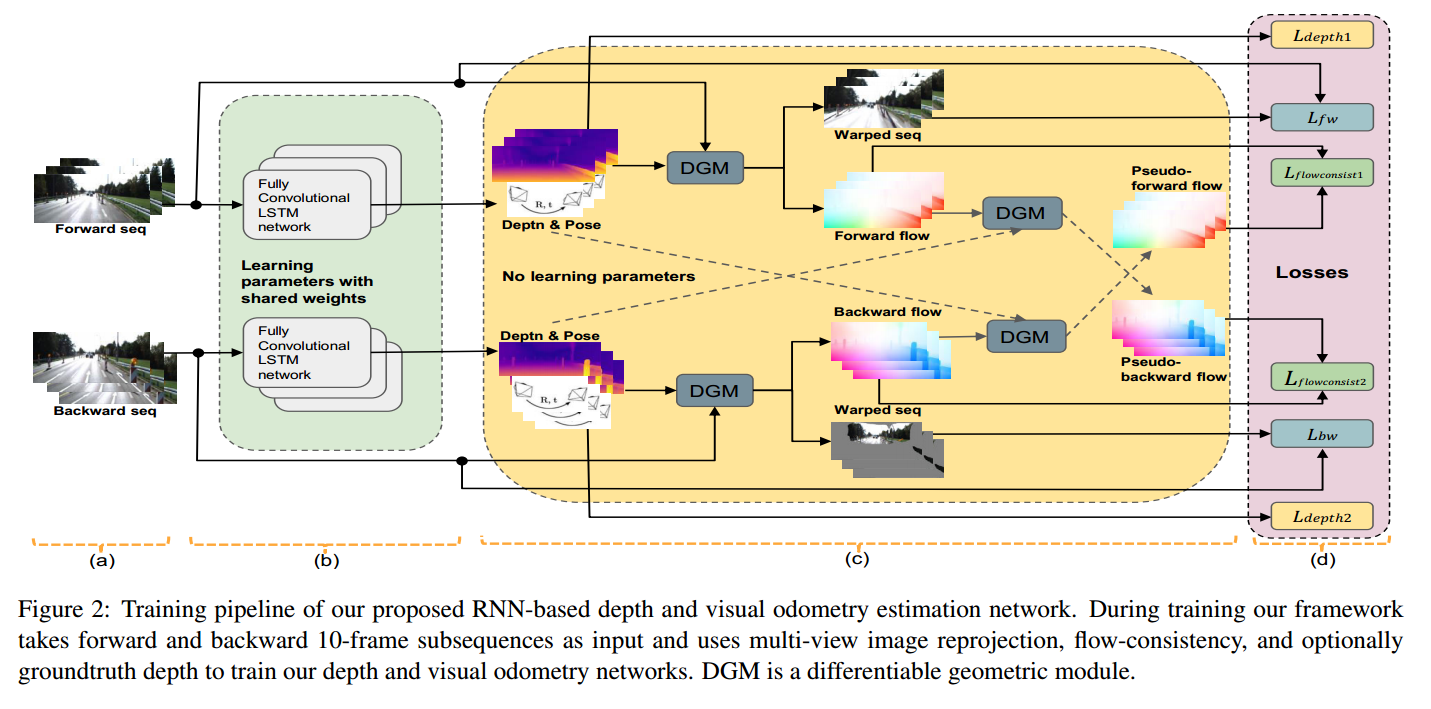
DGM的解释:Unsupervised Learning of Depth and Ego-Motion from Video(CVPR2017)

Unsupervised Learning of Depth and Ego-Motion from Video:

Forward-backward Flow Consistency Loss

Smoothness Loss

Absolute depth loss

可替代平滑loss
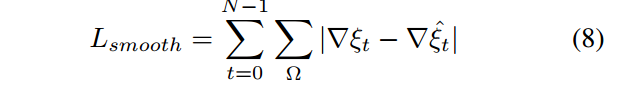
training
experiment
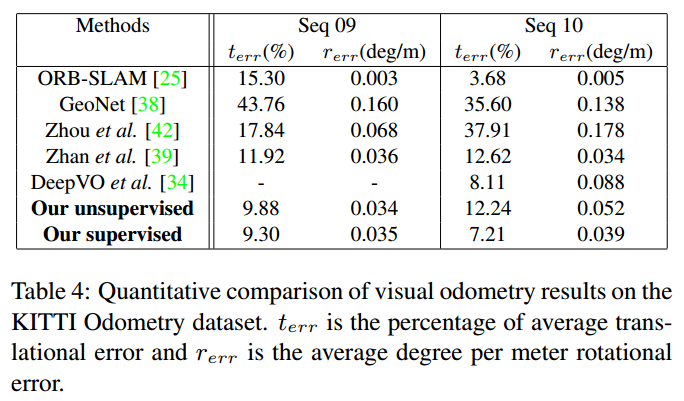
评价
在深度估计上的贡献多一点
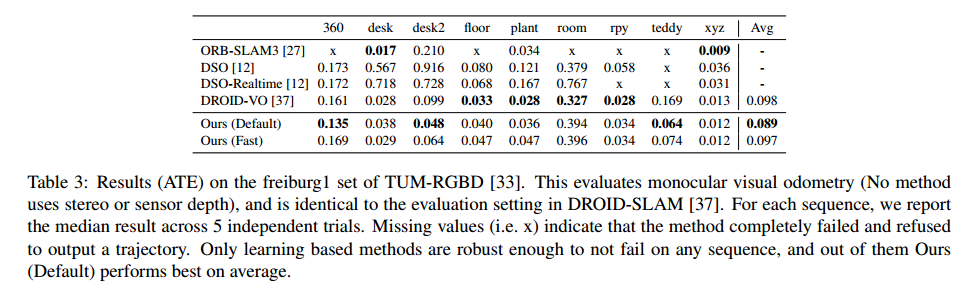
DROID-VO (NeurIPS 2021)
论文: DROID-SLAM: Deep Visual SLAM for Monocular,Stereo, and RGB-D Cameras (NeurIPS 2021)
真正把精度提到很高的
从他们的上一篇经典作品RAFT的扩展工作
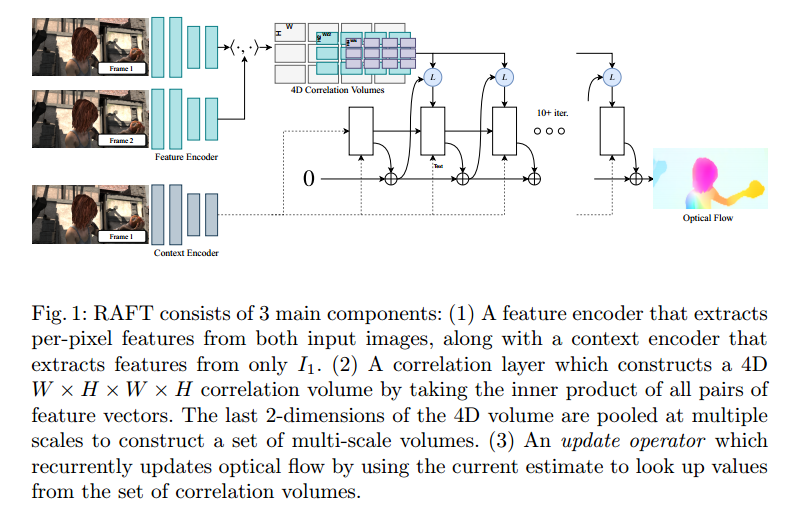
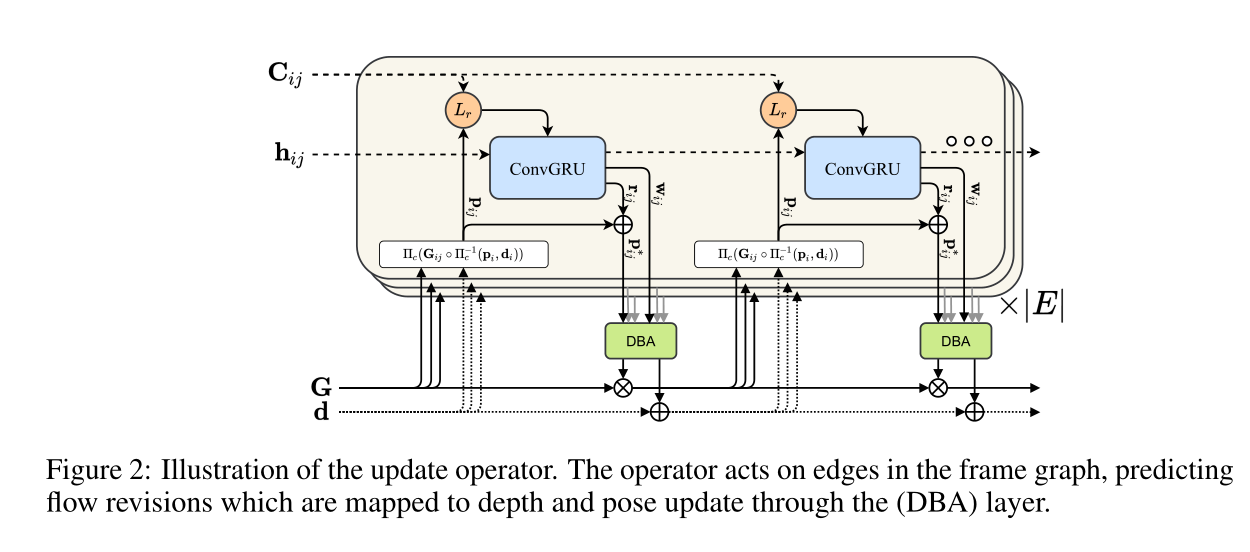
预测的是稠密光流中的更新
把隐藏层通过两层卷积映射为反向光流场
r
i
j
r_{ij}
rij(对光流场的修正)和关联置信图
w
i
j
w_{ij}
wij
最后通过DBA输出的是姿态更新和深度更新,通过SE(3)的指数映射更新相机姿态
contribution
DROID-SLAM核心:“Differentiable Recurrent Optimization-Inspired Design” (DROID)
整体结构采用的RAFT 的结构
Loss
监督的形式pose loss + flow loss
experiment
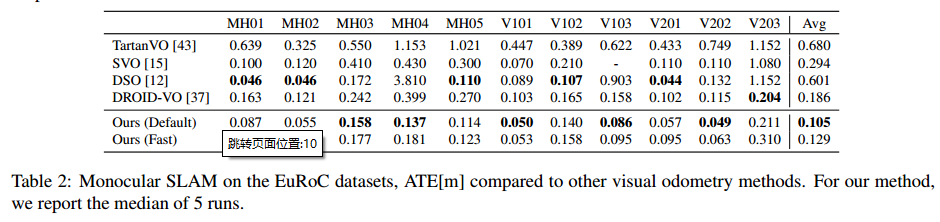
以单目形式在TartanAir数据集上进行实验
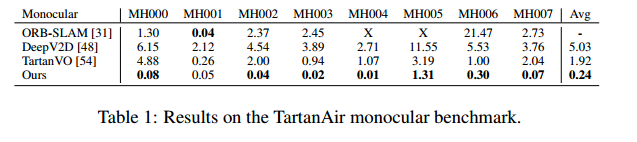
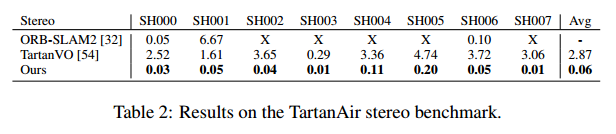
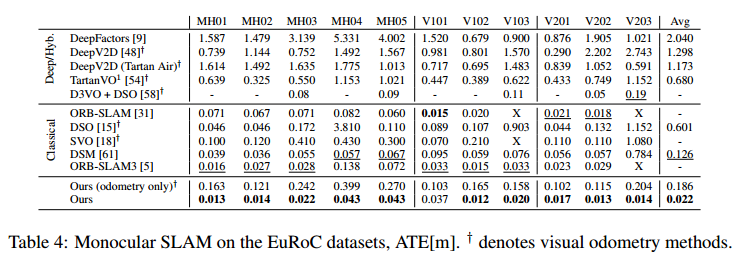
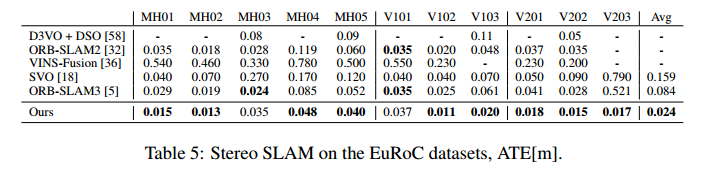
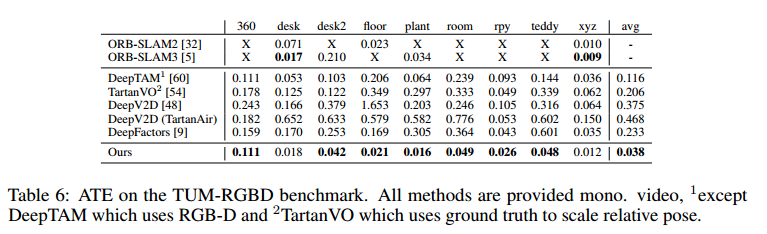
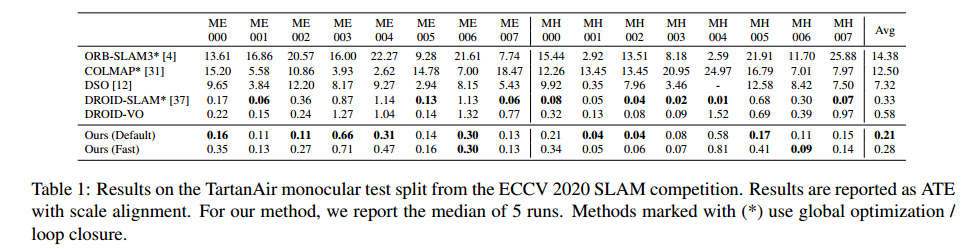
TartanVO (CoRL 2021)
为了使我们的 VO 模型能够跨数据集泛化,我们提出了一个大规模损失函数,并将相机内在参数合并到模型中。
Contribution
- 我们设计了一个尺度损失函数来处理单目 VO 的尺度模糊性。
- 我们在 VO 模型中创建一个内在层 (IL),以实现跨不同相机的泛化。
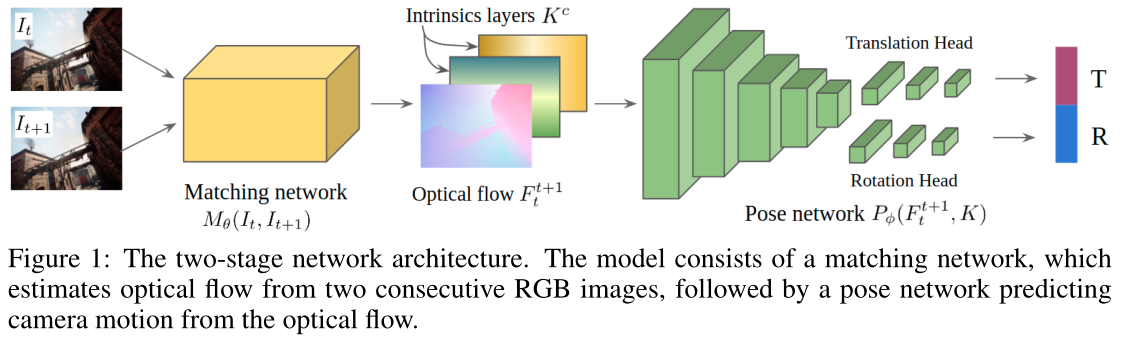
通过Randomly cropping and resizing 输入图像的大小来模拟各种内在函数

Loss
我们在任务中利用单目图像序列
{
I
t
}
\{I_t\}
{It}、光流标签
{
F
t
t
+
1
}
\{F ^{t+1}_t \}
{Ftt+1} 和地面实况相机运动
{
δ
t
t
+
1
}
\{δ^{t+1}_t\}
{δtt+1}。我们的目标是共同最小化光流损耗
L
f
L_f
Lf 和相机运动损耗
L
p
L_p
Lp。端到端损耗定义为:

experiment
只在TanAir数据集上进行训练,然后在KITTI数据集和EuROc数据集上无finetune进行测试

DiffPoseNet (CVPR2022)
论文:DiffPoseNet: Direct Differentiable Camera Pose Estimation (CVPR2022)
contribution
- 我们引入了一个网络 NFlowNet,用于法向流估计,用于强制执行鲁棒且直接的约束。特别是,法线流用于基于正景深约束来估计相对相机姿态。我们通过将优化问题表述为可微分景深层来实现这一目标,该层允许对相机姿势进行端到端学习。
experiment
DPVO (arXiv2023)
论文:Deep Patch Visual Odometry(arXiv2023)
contribution
最近的 VO 方法通过使用深度网络来预测视频帧之间的密集流,显着提高了最先进的准确性。然而,使用密集流会产生大量的计算成本,使得这些先前的方法对于许多用例来说不切实际。
DPVO 表明通过利用基于稀疏补丁的匹配相对于密集流的优势,可以获得最佳的准确性和效率。
DPVO 引入了一种新颖的循环更新算子,用于基于补丁的对应以及可微分束调整。在标准基准测试中,DPVO 的性能优于所有先前的工作,包括基于学习的最先进的 VO 系统 (DROID),该系统使用三分之一的内存,同时运行速度平均提高了 3 倍。
experiment
Dynamic VO
GeoNet (CVPR 2018)
论文:GeoNet: Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose(CVPR 2018)
CC (CVPR 2019)
论文:Competitive Collaboration: Joint Unsupervised Learning of Depth, Camera Motion, Optical Flow and Motion Segmentation (CVPR 2019)
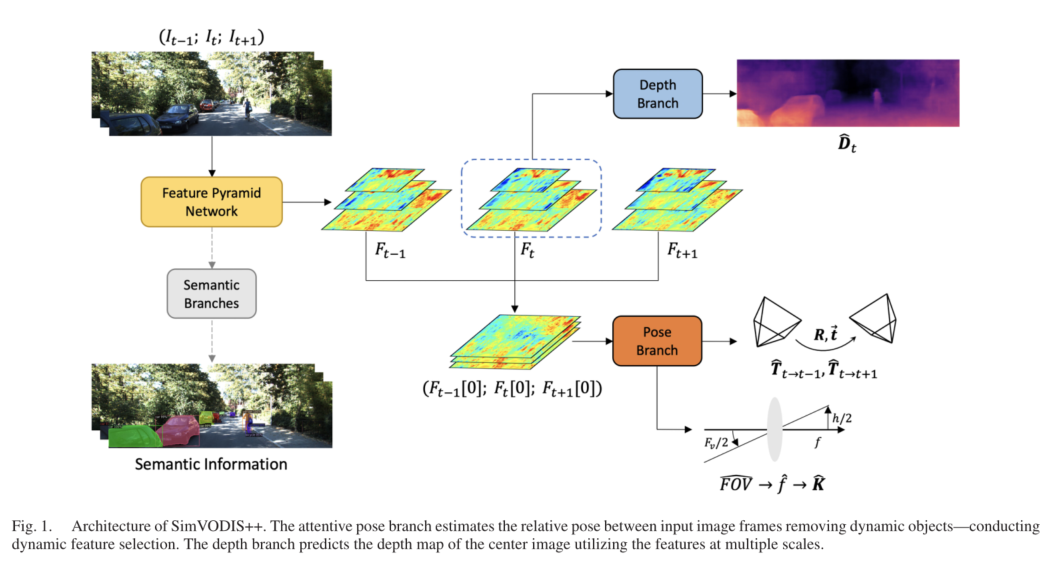
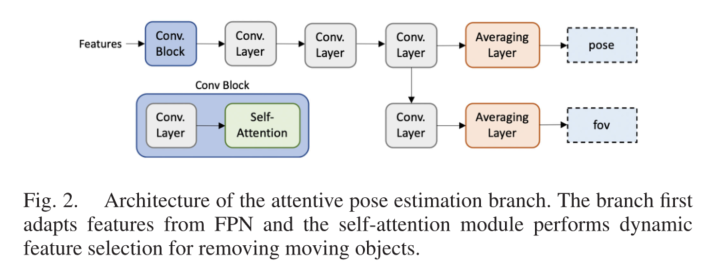
SimVODIS++ (RAL 2022)
论文:SimVODIS++: Neural Semantic Visual Odometry in Dynamic Environments (RAL 2022)
contribution
我们使用了一个自注意模块,使SimVODIS++学会以自监督的方式排除动态对象并选择显著区域。SimVODIS++还学习在该过程中排除无特征区域。
CBAM模块
MaskVO (SII 2022)
MaskVO: Self-Supervised Visual Odometry with a Learnable Dynamic Mask (SII 2022)
DytanVO (ICRA 2023)
论文:DytanVO: Joint Refinement of Visual Odometry and Motion Segmentation in Dynamic Environments (ICRA 2023)
contribution
• 引入了一种新颖的基于学习的VO,以利用相机自我运动、光流和运动分割之间的相互依赖性。
• 我们引入了一个迭代框架,其中自我运动估计和运动分割可以在实时应用的时间限制内快速收敛。
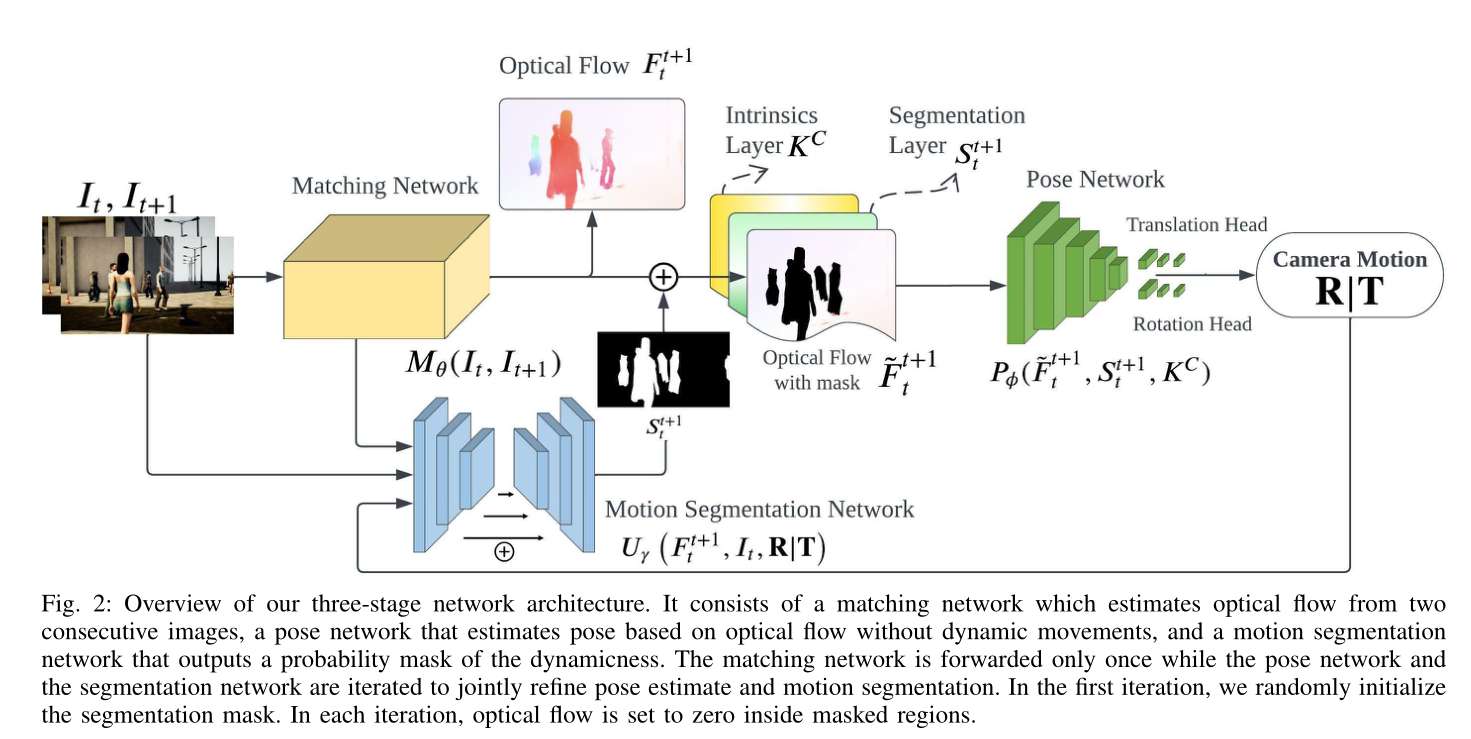
Loss
在单目设置下,我们只能恢复最大尺度的相机运动。我们按照[5],在计算到地面实况的距离之前对平移向量进行归一化。给定地面真实运动
R
∣
T
R|T
R∣T:

我们的框架也可以以端到端的方式进行训练,在这种情况下,目标变成光流损失
L
M
L_M
LM 、相机运动损失
L
P
L_P
LP 和运动分割损失
L
U
L_U
LU 的聚合损失,其中
L
M
L_M
LM 是之间的 L1 范数预测流和地面真实流,而
L
U
L_U
LU 是预测概率和分割标签之间的二元交叉熵损失。

experiment
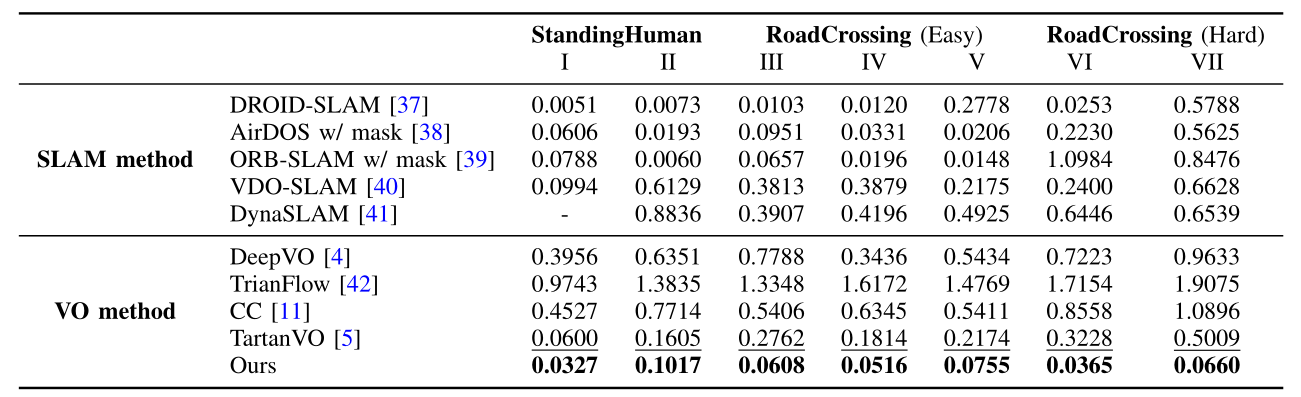
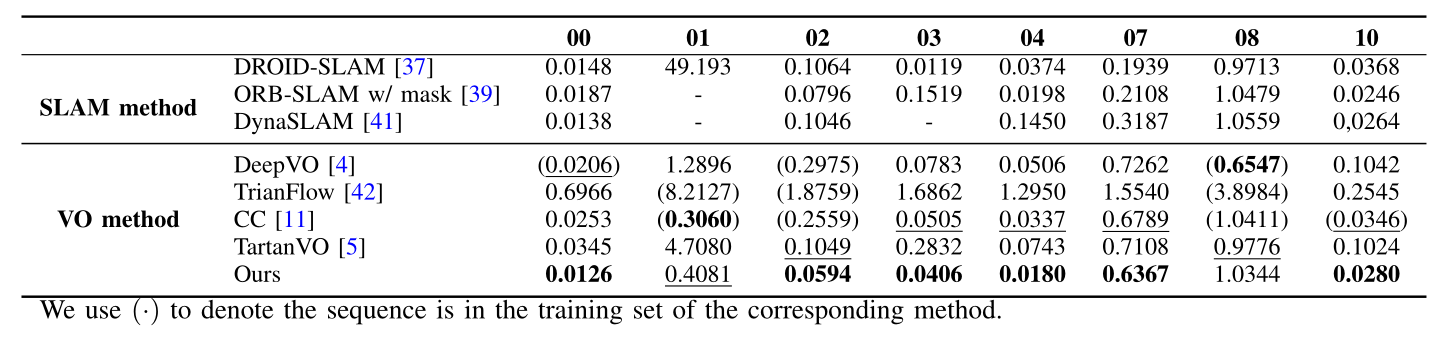
PVO(CVPR2023)
论文:PVO: Panoptic Visual Odometry (CVPR 2023)
https://zju3dv.github.io/pvo/
Contribution
1·提出了一种新的全景视觉里程计(PVO)框架,该框架可以统一VO和VPS任务,对场景进行全面建模。
2·引入全景更新模块并将其并入全景增强型VO模块中以改进姿态估计。 ·在VOEnhanced VPS模块中提出了一种在线融合机制,这有助于改善视频全景分割。
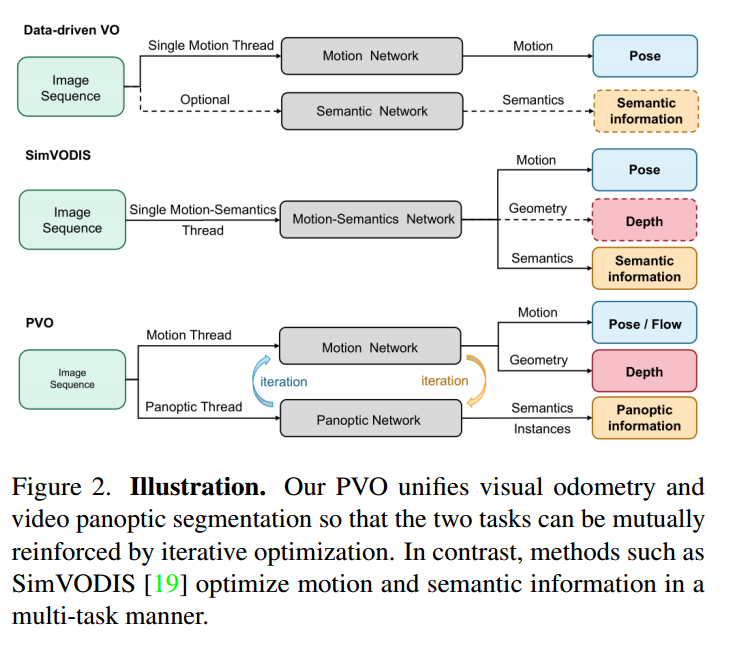
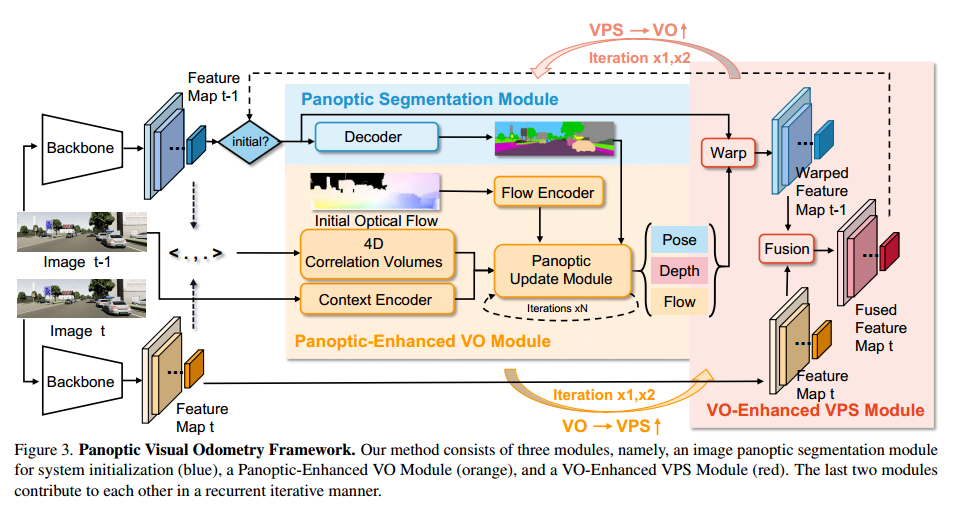
图3描绘了PVO模型的框架。它由三个主要模块组成:图像全景分割模块、全景增强型VO模块和VO增强型VPS模块。 VO模块旨在估计相机姿态、深度和光流,而VPS模块输出对应的视频全景分割。最后两个模块以循环交互的方式相互促进。
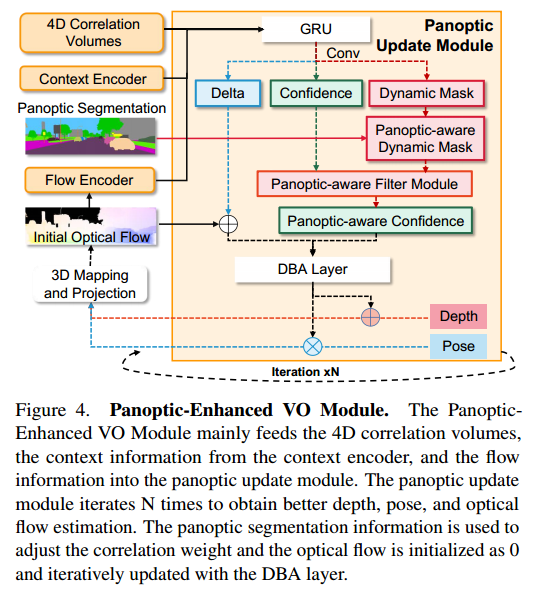
Panoptic-Enhanced VO Module
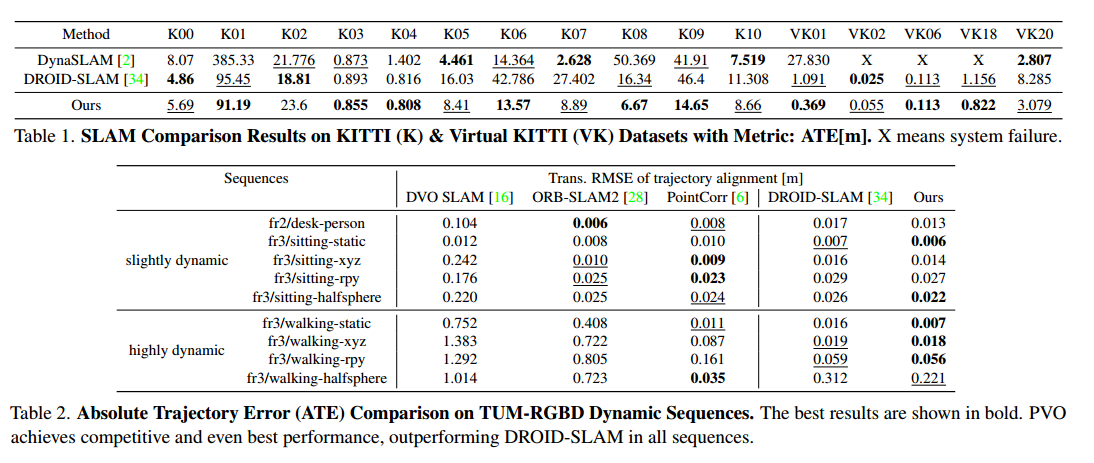
experiment



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











