







参考:
中科大2023春季【高级人工智能】试题回顾
中国科学技术大学《高级人工智能》课程 重要知识点提纲
高级人工智能复习提纲
1.搜索
1.1 搜索问题的概念
搜索问题的五个要素:状态空间、后继函数、初始状态、目标测试和路径耗散。
用状态图描述搜索问题:
每个节点表示一个状态,弧及两端点表示后继函数。状态图可能包括多个不连通的分量,状态图上标有初态和终态。
搜索问题无解:状态图中初始节点和终态节点在不连通的两个分量中。
1.1.1 搜索问题举例
华容道:
- 状态空间:期盼任意一种布局
- 后继函数:合法移动棋子得到另一种布局
- 初态:任意初始布局 终态:曹操跑出来
- 路径耗散: 每移动一个棋子,路径耗散为1
- 目标测试:解–从初态到终态的移动序列;最优解–路径耗散最少的序列
数码游戏/8皇后问题/数独建模类似
1.1.2 五要素
状态
对事物可能的抽象表示,构建好的状态空间可以减少空间的大小从而降低搜索难度。
好的状态空间:
- 尽量覆盖所有合法状态,并尽可能让所有状态是可达,可行合法的
- 状态数目越少越好
- 方便设计后继函数和搜索算法
例子:
对于8皇后,设置状态为任何0~8个皇后在棋盘上的布局表示一个状态,总状态数为 P 64 8 P^8_{64} P648。
如果设置为0~8个皇后在棋盘左侧且不互相攻击代表一个状态,则状态数目骤减为2057个。
后继函数
后继函数即为状态图的边,通常后继函数会返回若干个后继状态的集合。
路径耗散
标记在状态图的边上,表示执行后继函数的代价。一般都是正的(有时也被认为是一种reward)。
例如对数码问题,每移动依次,代价为1;n皇后问题,每放置/撤回一个皇后,代价为1,从一个状态转移到下一个状态花费代价为 ≤ 2 n \le 2n ≤2n。
初态和终态
初态和终态都可以是:
- 某个精确的特定状态
- 满足某些条件的某个状态
- 满足厚些条件的状态集合
问题的解
可能有唯一解,无解或多个解,有多个解时路径耗散最小的成为最优解。
1.1.3 路径规划问题形式化
- 网格化
- 扫描线法
- 障碍物边界法
1.1.4 搜索
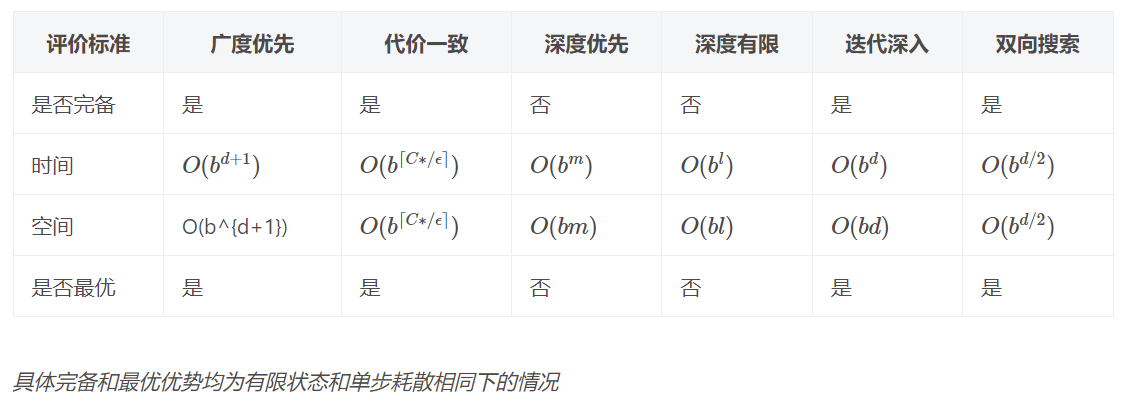
基准算法:对状态图的宽度优先遍历。
其他算法:
相同点:与基准算法 基本框架一致、所有可达和不可达的状态子图一致;
不同点:从状态图中选择和处理的状态子集不一样、状态子集构成的状态子图不一样、后继函数不一样。
搜索树:将状态图中算法的搜索过程涉及到的状态和搜索顺序抽取出来就得到了对应的搜索树。
状态图中的状态可能被重复访问,体现在状态图上的同一节点会变为搜索树上的不同节点。
节点扩展:节点扩展是生成搜索树的关键操作。直观理解就是把一个节点用它的后继节点(集合替换)。
扩展包括:评估节点的后继函数(考虑路径耗散),然后对后继函数返回的所有后继状态,在搜索树上分别产生一个子节点与之对应。注意节点扩展 ≠ \ne =节点产生,对节点扩展也可能不产生新的节点。修改节点集合的优先性质就是在改变搜索的扩展策略。
评估算法:考虑三个性质 完备性、最优性和复杂性。
完备性:有解时,能保证返回一个解;无解时,能保证返回failue
最优性:能否找到最优解
复杂性:搜索树的大小;时间复杂度;空间复杂度
’
一个搜索树的大小由初态、后继函数和搜索策略决定,影响因素是分支因子、最浅目标状态的深度和路径的最大长度。
时间复杂度:访问过的节点数目; 空间复杂度:同时保存在内存中节点数目的最大值。
边界:搜索树的边界(FRINGE)是指那些已访问过但未扩展状态的节点集合。搜索树上的叶节点不一定是搜索树的边界节点。
搜索策略:FRINGE中节点的优先次序
1.2 盲搜索(bsearch)
从搜索树的边界FRINGE这个角度看:
无信息搜索、盲搜索的特点是边界是无序的;有信息搜索、启发式搜索的特点是将更有希望的节点放在边界的最前面。
基准算法属于盲搜索算法,它单纯将新的节点插入FRINGE的末尾.
基准算法的两个重要参数是:
- 分子因子 b b b(后继函数返回的最大状态数目)
- 从初态到目标状态的最小深度 d d d;搜索树上离根最近的目标节点的深度
基准算法是
- 完备的;
- 在每条边路径耗散相同的情况下是最优的;
- 访问节点数是 O ( b d ) O(b^d) O(bd)。
当问题无解时,如果状态空间无限大或者任意状态可以任意次重复访问,则基准算法不会停止。
1.2.1 盲搜索的改进
双向搜索算法
分别从初态和终态启动两个搜索算法。维护两个边界集合,当集合相交时算法结束。
双向搜索的两个搜索算法可以不一样。
双向搜索的评价:
- 完备的;
- 路径耗散相同时保证最优性;
- 时空复杂度(假设两个方向的分子因子相同)是 O ( b d / 2 ) O(b^{d/2}) O(bd/2)。
此算法没有带来根本性的变化,且在某些状态下不便于定义终态的“前驱函数”(例如象棋的目标状态)。但是提供了一种搜索算法改进的框架,并获得极大的优化,同时完备性和最优性和基准算法一致。
深度优先算法
节点扩展时,新节点总是插入到边界集合的队头。
深度优先的评价:
- 若搜索树有限则完备;
- 不一定最优;
- 时间复杂度(最坏情况,假设 m m m是叶节点的最大深度)是 O ( b m ) O(b^{m}) O(bm),空间复杂度 O ( b m ) O(bm) O(bm)。
回溯法
节点扩展时,只插入一个新节点到边界集合的队头,同时最多保存 O ( m ) O(m) O(m)个节点。
评价:
- 若搜索树有限则完备;
- 不一定最优;
- 时间复杂度(最坏情形,假设 m m m是叶节点的最大深度) O ( b m ) ,空间复杂度 O(b^m),空间复杂度 O(bm),空间复杂度O(m)$。
深度受限的深度优先搜索
设置扩展节点的深度阈值 k k k,当节点深度大于阈值时不再扩展。
返回结果:解;无解failure;深度阈值k内无解
评价:
- 若搜索树有限则完备;
- 不一定最优,
- 时间复杂度 O ( b k ) O(b^k) O(bk),空间复杂度 O ( b k ) O(bk) O(bk)。
迭代深入搜索(IDS)
使用不同的受限深度参数 k = 0 , 1 , 2... k=0,1,2... k=0,1,2... 重复执行深度受限搜索。
结合BFS和DFS的长处,但要重复搜索节点。
评价:
- 当 k = d k=d k=d时,完备;
- 单步路径耗散相同时最优,否则不一定;
- 访问节点数(最坏情况) O ( b d ) O(b^d) O(bd),空间复杂度 O ( b d ) O(bd) O(bd)。
代价一致搜索
每次在边界中选择让目前获得的路径耗散最小的节点扩展,当单步路径耗散相同时等价于基准算法。
要求单步耗散有下界 x i ≥ ε > 0 x_i \ge \varepsilon > 0 xi≥ε>0
评价:
- 当搜索树有限且单步耗散有下界时完备;
- 最优;
- 时空复杂度为 O ( b [ C ∗ / ε ] ) O(b^{[C^*/ \varepsilon]}) O(b[C∗/ε]),一般比基准算法大
总结
1.2.2 避免状态重复访问
重复访问状态产生的原因是可逆的行动。
-
设置一个标识数组记录已经访问过的节点,若扩展终点得到的后继状态在标识数组中则直接丢弃。
这一方法需要的内存比较大,而且如果要保证最优性需要使用宽度优先搜索算法, -
用Open/Closed表,closed表存储所有访问过的状态,未拓展的状态用Open来表示,若当前待扩展的转台在CLosed中,将其丢弃,否则扩展。
1.2.3 树搜索和图搜索
我们将采用Open/Closed表的算法框架称为图搜索:
例如在代价一致搜索中:
closed表保存每个状态的最优路径耗散(从初态出发),若s在closed表中,则检查s的代价(从初始状态到s的路径耗散),并和当前路径+s的总路径耗散进行比较,取较小的路径耗散,更新状态s的路径耗散;若s不在closed表中,则放入closed中,并开始扩展。
树搜索中不同节点可能代表的是相同的状态,分别代表从初态出发到达同一状态的不同路径;而图搜索中不同的节点代表不同的状态,相同状态都合并到同一节点上。
若状态空间无限,或者有限但允许状态被任意复杂重复访问,则搜索一般是不完备的;若状态空间有限且访问时重复状态被抛弃则搜索是完备的但一般不是最优的。
1.3 启发式搜索(heuristic)
和基准算法不同:启发式算法在拓展并插入新状态节点进入FRINGE时,会增加一个在FRINGE中给待拓展状态空间按一定优先级排序的过程
启发式搜索通过设计一个评估函数 f f f ,将搜索树的节点 N N N映射到一个非负实数 f ( N ) f(N) f(N),表示从初始状态到达某个节点的路径耗散(越小越好)。
最佳优先搜索:每次从FRINGE中选择最佳节点进行拓展,这里的最佳是局部贪婪,并不一定是全局最佳。
设计函数 f f f的两种方法:
- 设计 f ( N ) = g ( N ) + h ( N ) f(N)=g(N)+h(N) f(N)=g(N)+h(N)对应 A ∗ \text{A}^* A∗算法
- f ( N ) = h ( N ) f(N)=h(N) f(N)=h(N)对应贪婪算法。
N N N:待评价的节点, g ( N ) g(N) g(N)从初始节点到 N N N的路径耗散, h ( N ) h(N) h(N)从 N N N到目标节点的路径耗散,这就是所谓的启发式函数
1.3.1 启发式函数的设计要求
基本要求: h ( N ) ≥ 0 , h ( G o a l ) = 0 h(N) \ge 0, h(Goal)=0 h(N)≥0,h(Goal)=0;离目标越近 h ( N ) h(N) h(N)越小。
可采纳性: 0 ≤ h ( N ) ≤ h ∗ ( N ) 0 \le h(N) \le h^*(N) 0≤h(N)≤h∗(N),其中 h ∗ ( N ) h^*(N) h∗(N) 是到目标的实际最优路径。这代表启发式函数必须乐观的估计将来的耗散。通常可以用一个松弛问题设计可采纳的启发式函数。
一致性/单调性 h ( N ) ≤ c ( N , N ′ ) + h ( N ′ ) h(N) \le c(N,N') + h(N') h(N)≤c(N,N′)+h(N′),其中 N ′ N' N′是 N N N的后继, c ( N , N ′ ) c(N,N') c(N,N′)为两点之间的单步耗散。注意一致的启发式函数都是可以采纳的。这带来 h ( N ) ≤ h ∗ ( N ) ≤ c ( N , N ′ ) + h ( N ′ ) h(N) \le h^*(N) \le c(N,N') + h(N') h(N)≤h∗(N)≤c(N,N′)+h(N′)。
举例1:
机器人导航问题,在一个网格中有的格子是路径有的是障碍物,从初态格子导航到终态格子。
f ( N ) = h ( N ) = M a n h a t t a n d i s t a n c e f(N)=h(N)=Manhattan distance f(N)=h(N)=Manhattandistance 启发式函数为从当前点到终点的曼哈顿距离。
举例2:
数码问题(一个九宫格中每个格子分别填有1~8)或是空格,数字可以移动到邻接的空格中去,给定初始数字分布和目标数字分布求移动方式。
三种启发式函数设计:
- 错误放置的格子数(可采纳,一致的)
- 所有的数字到其正确位置的曼哈顿距离之和(可采纳一致的)
- 逆序数之和
举例3:
路径规划问题
启发式函数可以为:
- 欧式距离(可采纳的,一致的)
- 曼哈顿距离(若不允许沿网格对角线移动,则是可采纳的一致的;否则是不可采纳的不一致)
1.3.2 A*
f ( N ) = g ( N ) + h ( N ) f(N)=g(N)+h(N) f(N)=g(N)+h(N)对应 A ∗ \text{A}^* A∗算法
g ( N ) g(N) g(N)是初始节点到N的路径耗散, h ( N ) h(N) h(N)是从N到目标节点的路径耗散,可采纳的启发式函数
问题有解时:具有完备性、最优性,且对一致的 h h h,A*算法拓展一个状态节点时到该状态的路径一定是最优的。(证明见PPT29)
无解情况:
1.状态空间无限/ 允许重复访问,A*算法的搜索不会停止
2.求解实际问题时通常给一个停止时间,到达时间时自动停止
再议图搜索和树搜索:
图搜索允许状态重复访问–>保证获得最优解–>无解时可能永远停不下来
树搜索避免状态重复访问–>状态有限时完备–>不保证最优
A*算法状态重复访问改进:当且仅当该节点的新路径的耗散 g ( N ) g(N) g(N)比以前访问该状态的路径耗散更大时,丢弃重复访问的这个状态节点。
A算法中一致的启发式函数:
特殊的一致启发函数 h = 0 h=0 h=0,等价单步路径耗散相同,A 退化为宽度优先搜索,代价一致搜索。
设计启发函数时,对于两个可采纳的启发式函数 h 1 , h 2 h_1,h_2 h1,h2,若对任意节点, h 1 ≤ h 2 h_1 \le h_2 h1≤h2则称 h 2 h_2 h2比 h 1 h_1 h1准确。更准确的启发式函数拓展的节点会更少一些,而不精确的启发式函数会访问更多的节点。
1.3.3 IDA*
设置 f f f的阈值,超过阈值的节点不再扩展;迭代执行以降低 A ∗ A* A∗对内存的需求。
步骤:
1.初始化f的阈值t为 f ( N 0 ) f(N0) f(N0)
2.Loop:
- 执行深度优先搜索,扩展 f ( N ) ≤ t f(N) \le t f(N)≤t的节点
- 重新设置t为未拓展节点中 f f f的最小值
优点:
- 完备+最优
- 内存要求比A*少
- 避免了未拓展节点集合的排序开销
不足:
- 无法充分利用内存,两次迭代之键只保留阈值t
- 无法避免重复访问不在路径上的点
改进:IDA*–> SMA*
将内存用光直至不能保存节点了,丢掉保存的一个高耗散,最旧的节点,再插入新的节点。
1.4 优化问题
优化问题是指 min f ( x ) s . t . h ( x ) ≤ 0 \text{min} f(x) \ s.t. \ h(x) \le 0 minf(x) s.t. h(x)≤0,其中 f ( x ) f(x) f(x)是目标函数, h ( x ) h(x) h(x)是约束条件。
可以分为数值优化和组合优化两类问题。
将优化问题建模为搜素问题,其解法分为两种:
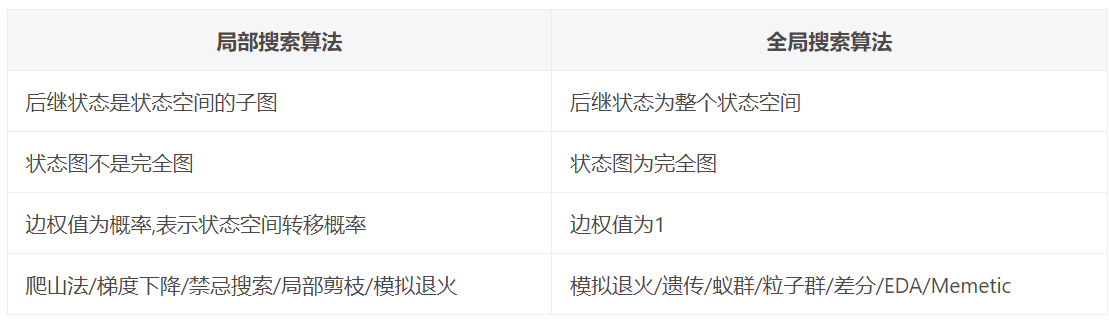
1.4.1 梯度下降法
对终止准则 T T T、步长序列 λ \lambda λ 和初态 X 0 X_0 X0,迭代更新
X t + 1 = X t − λ t ∇ X g ( X s ) , where ∇ X g = ( ∂ g ∂ x 1 , ∂ g ∂ x 2 , ⋯ , ∂ g ∂ x n ) X_{t+1}=X_{t}-\lambda_{t} \nabla_{X} g\left(X_{s}\right), \text { where } \nabla_{X} g=\left(\frac{\partial g}{\partial x_{1}}, \frac{\partial g}{\partial x_{2}}, \cdots, \frac{\partial g}{\partial x_{n}}\right) Xt+1=Xt−λt∇Xg(Xs), where ∇Xg=(∂x1∂g,∂x2∂g,⋯,∂xn∂g)
g ( x ) g(x) g(x)是n元实函数
- 第一步,设置超参数学习率(步长)
- 第二步,初始化初态
- 第三部,循环迭代
缺点:不能保证获得全局最优,且停止条件和学习率需要人工经验。
改进:不知道步长就多试几个步长来尝试;随机梯度下降,每一步都更新参数,而不是处理完整个训练集后更新
直线搜索
在一个预定的测试步长几何{…,-2c,-c,2c,…}中每轮选择其中使函数下降最快的那一个 λ ∗ = a r g λ m i n g ( X − λ ∇ x g ) \lambda *=arg_{\lambda}min_g(X-\lambda \nabla_x g) λ∗=argλming(X−λ∇
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1884
1884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











