







目录
📍 df.rename(index=None,columns=None,axis=None,inplace=False)
📍 value_counts(sort,ascending,normalize,bins,dropna)
🧾 1、数据集(部分数据)
- day数据集

| 字段名称 | 含义说明 |
| instant |
行数编码 |
| dteday | 日期变量 |
| season | 季节变量,编码1-4分别表示1-3月、4-6月、6-9月,10-12月 |
| yr | 年份变量,编码0代表2011年,1代表2012年 |
| mnth | 月份编码,范围为1-12,代表1-12月 |
| holiday | 是否为节假日,0代表不是,1代表是 |
| weekday | 一周的第几天,范围为0-6 |
| workingday | 是否为工作日,0代表不是,1代表是 |
| weathersit | 天气类型,1代表晴朗少云,2代表多云雾,3代表小雨/小雪/雷电 |
| temp | 以摄氏度表示的标准化温度,值被除以41(最大值) |
| atemp | 以摄氏度表示的标准化感觉温度,值被除以50(最大值) |
| hum | 标准化湿度,值被除以100(最大值) |
| windspeed | 标准化风速,值被除以67(最大值) |
| casual | 未注册用户单车使用量 |
| registered | 注册用户单车使用量 |
| cnt | 所有用户单车使用量,包括未注册用户和注册用户 |
- tree数据集

✏️ 2、导入数据集与必要模块
1️⃣ 2.1 导入库以及字体包
# 导入pandas模块和numpy模块
import pandas as pd
import numpy as np
# 3.# 导入matplotlib.pyolot模块
import matplotlib.pyplot as plt
from plotnine import *
%matplotlib inline
# 3.设置绘图时的中文字体
from matplotlib.font_manager import FontProperties
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus']=False
# 4.字体包的存放路劲、设置字体的大小为15
myfont = FontProperties(fname = 'C:/XXX/xxx/Desktop/实验五——共享单车可视化/FangSong_GB2312.ttf', size = 15) 2️⃣ 2.2 读取数据集
# 1.读取数据
data_old = pd.read_csv('C:/XXX/xxx/Desktop/实验五——共享单车可视化/day.csv')
# 2.查看数据的前5行
data_old.head()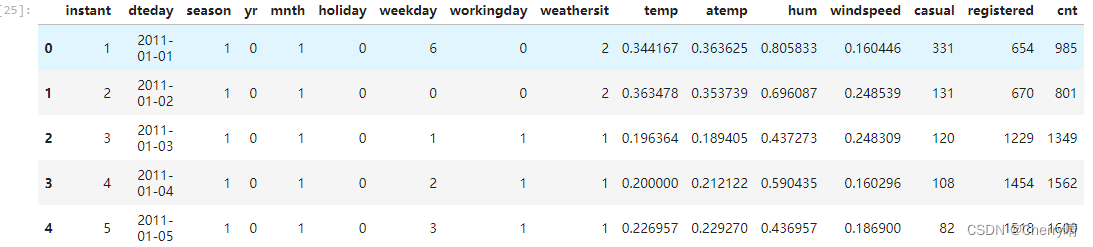
3️⃣ 2.3 查看数据集基本信息
# 1.查看数据集基本信息
data_old.info()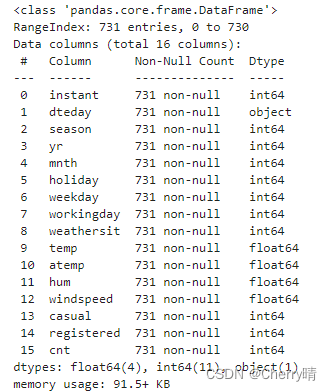
- 从结果中可以看出,数据集中共包含731条数据,没有缺失数据 。
⌨️ 3、数据预处理
1️⃣ 3.1删除无关字段
-
有些字段与数据分析无关,例如:字段instant表示行数编码,可以直接删除。
-
有些字段的含义较为接近,保留其一即可,例如:字段atemp和temp都表示温度,留下一个就可以。
# 1.使用drop方法来删除字段
data = data_old.drop(['instant', 'atemp', 'casual', 'registered'], axis=1) 2️⃣ 3.2对各字段进行中文标识
# 1.字段名称
chs_name = {'dteday': '日期', # {'新列名':'旧列名'}
'season': '季节',
'yr': '年份',
'mnth': '月份',
'holiday': '节假日',
'weekday': '星期',
'workingday': '工作日',
'weathersit': '天气类型',
'temp': '温度',
'hum': '湿度',
'windspeed': '风速',
'cnt': '使用量'}
# 2.使用rename方法对列明进行修改,是直接在元数据进行修改
data.rename(columns=chs_name, inplace=True)
# 3.标识后的结果
data.head()
3️⃣ 3.3 用条形图展示字段类型个数
📍 df.rename(index=None,columns=None,axis=None,inplace=False)
| 字段 | 数据类型 | 含义 |
| index | list 或 dict 或 series | 用于重命名行索引的标签或映射的字典,如{ 0 : “第一行”} |
| columns | list 或 dict 或 series | 用于重命名列名的标签或映射的字典,如{ A : “第一列”} |
| axis | int 或 str | 要重命名的轴 |
| inplace | bool | 是否在原地修改 DataFrame,如果为True,则直接在原 DataFrame 上进行修改,不返回新的 DataFrame,如果为False(默认值),则返回一个新的 DataFrame,原 DataFrame 保持不变 |
📍 value_counts(sort,ascending,normalize,bins,dropna)
| 字段 | 数据类型 | 含义 |
| sort | bool | 默认为True,如果为True,则对结果进行降序排序(从最常见的值到最不常见的值),如果为False,则不会进行排序 |
| ascending | bool | 默认值为 False,如果为False,则结果按降序排序(最常见的值在最前面),如果为True,则结果按升序排序(最不常见的值在最前面) |
| normalize | bool | 默认值为False,如果为True,则返回每个值出现的频率(即每个值出现的次数除以总数),如果为False,则返回每个值出现的次数 |
| bins | int 或 array | 可以用来对数据进行分箱,并将结果作为类别计数返回,如果指定了bins,则normalize 必须为False |
| dropna | bool | 默认值为True,如果为True,则不在结果中包含缺失值(NaN),如果为False,则会在结果中包含缺失值,并计算它们的出现次数 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2713
2713











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











