







1.3.8 loc( ) 与iloc( ) ——选取一行的两种方式
(1)通过loc( )方法,选取index=2的那一行元素
- datafame.loc[row_indexer,column_indexer]
| row_indexer | 行标签;可以是单个标签、标签列表或标签切片 |
| column_indexer | 列标签;可以是单个标签、标签列表或标签切片 |
| 如果row_indexer和column_indexer都是标签列表或标签切片,则表示选择交叉区域的数据。 | |
# 1.通过loc方法,选取index=2的那一行元素
athlete.loc[2]
# 2.得到的结果为
ID 3
Name Gunnar Nielsen Aaby
Sex M
Age 24.0
Height NaN
Weight NaN
Team Denmark
NOC DEN
Games 1920 Summer
Year 1920
Season Summer
City Antwerpen
Sport Football
Event Football Men's Football
Medal NaN
Name: 2, dtype: object(2)通过iloc( )方法选取某一行,根据行号索引
-
dataframe.iloc[row_index,column_index]:用法与loc类似,row_index和column_index可以是单个整数、整数列表、整数切片或布尔数
# 1.选取某一行,根据行号索引
athlete.iloc[2]
# 2.得到的结果为
ID 3
Name Gunnar Nielsen Aaby
Sex M
Age 24.0
Height NaN
Weight NaN
Team Denmark
NOC DEN
Games 1920 Summer
Year 1920
Season Summer
City Antwerpen
Sport Football
Event Football Men's Football
Medal NaN
Name: 2, dtype: object- Series 查看Sex列的数据的类型,发现这个是个一维数组
- DataFrame 查看Sex列的数据类型,发现这是个二维数组
# 1.Series 查看Sex列的数据的类型,发现这个是个一维数组
type(athlete.iloc[2])
# 2.得到的结果为
pandas.core.series.Series
# 3.DataFrame 查看Sex列的数据类型,发现这是个二维数组
type(athlete.iloc[[2]])
# 4.得到的结果为
pandas.core.frame.DataFrame1.3.9 选取多行或多列
(1)显示前五行,同head()方法一样
# 1.显示前五行,同head()方法一样
athlete.iloc[0:5]
# 2.得到的结果为
ID Name Sex Age Height Weight Team NOC Games Year Season City Sport Event Medal
0 1 A Dijiang M 24.0 180.0 80.0 China CHN 1992 Summer 1992 Summer Barcelona Basketball Basketball Men's Basketball NaN
1 2 A Lamusi M 23.0 170.0 60.0 China CHN 2012 Summer 2012 Summer London Judo Judo Men's Extra-Lightweight NaN
2 3 Gunnar Nielsen Aaby M 24.0 NaN NaN Denmark DEN 1920 Summer 1920 Summer Antwerpen Football Football Men's Football NaN
3 4 Edgar Lindenau Aabye M 34.0 NaN NaN Denmark/Sweden DEN 1900 Summer 1900 Summer Paris Tug-Of-War Tug-Of-War Men's Tug-Of-War Gold
4 5 Christine Jacoba Aaftink F 21.0 185.0 82.0 Netherlands NED 1988 Winter 1988 Winter Calgary Speed Skating Speed Skating Women's 500 metres NaN(2)显示前五列
# 1.显示前五列
athlete.iloc[:,0:5]
# 2.得到的结果为
ID Name Sex Age Height
0 1 A Dijiang M 24.0 180.0
1 2 A Lamusi M 23.0 170.0
2 3 Gunnar Nielsen Aaby M 24.0 NaN
3 4 Edgar Lindenau Aabye M 34.0 NaN
4 5 Christine Jacoba Aaftink F 21.0 185.0
... ... ... ... ... ...
271111 135569 Andrzej ya M 29.0 179.0
271112 135570 Piotr ya M 27.0 176.0
271113 135570 Piotr ya M 27.0 176.0
271114 135571 Tomasz Ireneusz ya M 30.0 185.0
271115 135571 Tomasz Ireneusz ya M 34.0 185.0
271116 rows × 5 columns(3)显示前五列与前五行
# 1.显示前五列与前五行
athlete.iloc[0:5,0:5]
# 2.得到的结果为
ID Name Sex Age Height
0 1 A Dijiang M 24.0 180.0
1 2 A Lamusi M 23.0 170.0
2 3 Gunnar Nielsen Aaby M 24.0 NaN
3 4 Edgar Lindenau Aabye M 34.0 NaN
4 5 Christine Jacoba Aaftink F 21.0 185.01.3.10 选取某行某列
(1)loc( ) 方法选取某行某列 :先选取索引Sex,再在这列中选取索引为2的元素
# 1.选取某行某列 先选取索引Sex,再在这列中选取索引为2的元素
athlete.loc[2,'Sex']
# 2.得到的结果为
'M'(2)iloc( ) 方法选取第2行第2列元素
# 1.选取第2行第2列元素
athlete.iloc[2,2]
# 2.得到的结果为
'M'(3)loc( ) 方法选取列名为Sex和Age的列,再选取他们的第2到第4个元素
# 1.选取列名为Sex和Age的列,再选取他们的第2到第4个元素
athlete.loc[2:4,['Sex','Age']]
# 2.得到的结果为
Sex Age
2 M 24.0
3 M 34.0
4 F 21.0(4)iloc( ) 方法选取他们的行和列的第2到第4个元素,这里采用的是切片的方法
# 1.选取他们的行和列的第2到第4个元素,这里采用的是切片的方法
athlete.iloc[2:4,2:4]
# 2.得到的结果为
Sex Age
2 M 24.0
3 M 34.01.4 数据的增删改
1.4.1 drop( ) 方法——删除某列
- drop(labels=None, axis=0,index=None, columns=None,level=None,inplace=False,errors='raise')
| labels | 一个字符或者数值,加上axis ,表示带label标识的行或者列;如(labels = 'A',axis = 1)表示A列 |
| axis | axis=0表示行,axis=1表示列 |
| columns | 列名 |
| index | 表示dataframe的index,如index=1,index=a |
| inplace | True表示删除某行后原dataframe变化,False不改变原始dataframe |
# drop方法:axis=1(列),删除columns,axis=0 指删除index;删除Sex列
athlete.drop('Sex',axis=1)
# 2.得到的结果为
ID Name Age Height Weight Team NOC Games Year Season City Sport Event Medal
0 1 A Dijiang 24.0 180.0 80.0 China CHN 1992 Summer 1992 Summer Barcelona Basketball Basketball Men's Basketball NaN
1 2 A Lamusi 23.0 170.0 60.0 China CHN 2012 Summer 2012 Summer London Judo Judo Men's Extra-Lightweight NaN
2 3 Gunnar Nielsen Aaby 24.0 NaN NaN Denmark DEN 1920 Summer 1920 Summer Antwerpen Football Football Men's Football NaN
3 4 Edgar Lindenau Aabye 34.0 NaN NaN Denmark/Sweden DEN 1900 Summer 1900 Summer Paris Tug-Of-War Tug-Of-War Men's Tug-Of-War Gold
4 5 Christine Jacoba Aaftink 21.0 185.0 82.0 Netherlands NED 1988 Winter 1988 Winter Calgary Speed Skating Speed Skating Women's 500 metres NaN
... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
271111 135569 Andrzej ya 29.0 179.0 89.0 Poland-1 POL 1976 Winter 1976 Winter Innsbruck Luge Luge Mixed (Men)'s Doubles NaN
271112 135570 Piotr ya 27.0 176.0 59.0 Poland POL 2014 Winter 2014 Winter Sochi Ski Jumping Ski Jumping Men's Large Hill, Individual NaN
271113 135570 Piotr ya 27.0 176.0 59.0 Poland POL 2014 Winter 2014 Winter Sochi Ski Jumping Ski Jumping Men's Large Hill, Team NaN
271114 135571 Tomasz Ireneusz ya 30.0 185.0 96.0 Poland POL 1998 Winter 1998 Winter Nagano Bobsleigh Bobsleigh Men's Four NaN
271115 135571 Tomasz Ireneusz ya 34.0 185.0 96.0 Poland POL 2002 Winter 2002 Winter Salt Lake City Bobsleigh Bobsleigh Men's Four NaN
271116 rows × 14 columns
# 3.查看原始数据
ID Name Sex Age Height Weight Team NOC Games Year Season City Sport Event Medal
0 1 A Dijiang M 24.0 180.0 80.0 China CHN 1992 Summer 1992 Summer Barcelona Basketball Basketball Men's Basketball NaN
1 2 A Lamusi M 23.0 170.0 60.0 China CHN 2012 Summer 2012 Summer London Judo Judo Men's Extra-Lightweight NaN
2 3 Gunnar Nielsen Aaby M 24.0 NaN NaN Denmark DEN 1920 Summer 1920 Summer Antwerpen Football Football Men's Football NaN
3 4 Edgar Lindenau Aabye M 34.0 NaN NaN Denmark/Sweden DEN 1900 Summer 1900 Summer Paris Tug-Of-War Tug-Of-War Men's Tug-Of-War Gold
4 5 Christine Jacoba Aaftink F 21.0 185.0 82.0 Netherlands NED 1988 Winter 1988 Winter Calgary Speed Skating Speed Skating Women's 500 metres NaN
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
271111 135569 Andrzej ya M 29.0 179.0 89.0 Poland-1 POL 1976 Winter 1976 Winter Innsbruck Luge Luge Mixed (Men)'s Doubles NaN
271112 135570 Piotr ya M 27.0 176.0 59.0 Poland POL 2014 Winter 2014 Winter Sochi Ski Jumping Ski Jumping Men's Large Hill, Individual NaN
271113 135570 Piotr ya M 27.0 176.0 59.0 Poland POL 2014 Winter 2014 Winter Sochi Ski Jumping Ski Jumping Men's Large Hill, Team NaN
271114 135571 Tomasz Ireneusz ya M 30.0 185.0 96.0 Poland POL 1998 Winter 1998 Winter Nagano Bobsleigh Bobsleigh Men's Four NaN
271115 135571 Tomasz Ireneusz ya M 34.0 185.0 96.0 Poland POL 2002 Winter 2002 Winter Salt Lake City Bobsleigh Bobsleigh Men's Four NaN
271116 rows × 15 columns- 可以发现,原始数据中有15列,并没有改变原始数据,这是因为参数inplace = False(默认)
- 若需要改变原始数据,则inplace = True
1.4.2 drop( ) 方法——删除某行
# 1.删除第0行,不改变原数据
athlete.drop(0,axis=0)
# 2.查看第一行数据
athlete.head(1)
# 3.得到的结果为
ID Name Age Height Weight Team NOC Games Year Season City Sport Event Medal
0 1 A Dijiang 24.0 180.0 80.0 China CHN 1992 Summer 1992 Summer Barcelona Basketball Basketball Men's Basketball NaN
# 1.删除第0行,改变原数据
athlete.drop(0,axis=0,inplace=True)
# 2.查看第一行数据
athlete.head(1)
# 3.得到的结果为
ID Name Age Height Weight Team NOC Games Year Season City Sport Event Medal
1 2 A Lamusi 23.0 170.0 60.0 China CHN 2012 Summer 2012 Summer London Judo Judo Men's Extra-Lightweight NaN1.4.3 insert( )方法——增加一列
- insert(loc,column,value,allow_duplicates = False)
| loc | 插入列的索引,第一列是0 |
| column | 赋予新的列的名称 |
| value | 新的列的值,数组的形式 |
| allow_duplicates | 是否允许新的列匹配现有的列名,默认为Flase |
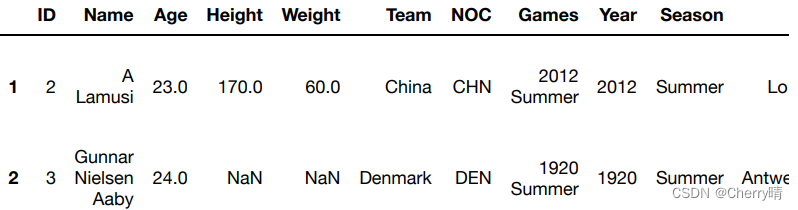
# 1.第二种方法插入新的一列
athlete['rate'] = athlete['Weight']/athlete['Height']
# 2.查看前两列
athlete.head(2)
1.4.4 concat( )方法——增加一行
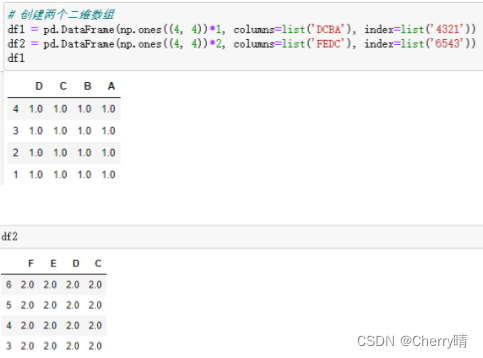
- concal(objs, axis=0, join='outer,join axes=None, ignore index=False, keys=None, levels=None, names=Noneverify integrity=False,copy=True)
| axis | 拼接轴方向,默认为0,沿行拼接;若为1,沿列拼接 |
| join | 默认外联"outer',拼接另一轴所有的label,缺失值用NaN填充;内联"inner,只拼接另一轴相同的label |
| join axes | 指定需要拼接的轴的labels,可在join既不内联又不外联的时候使用 |
| gnore index | 对index进行重新排序 |
| keys | 多重索引 |
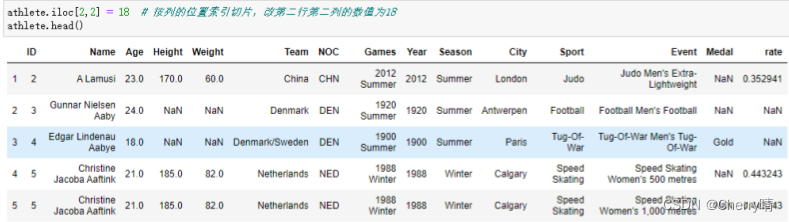
1.4.6 更改某个值
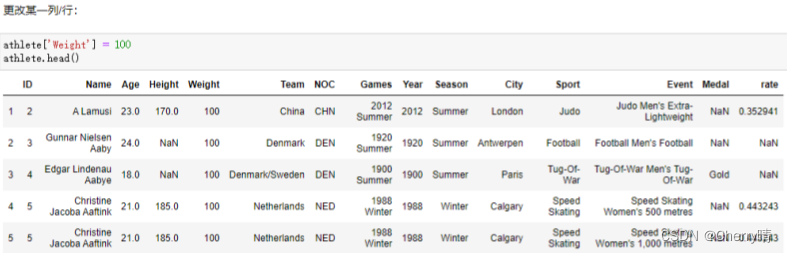
1.4.7 更改某一列或行
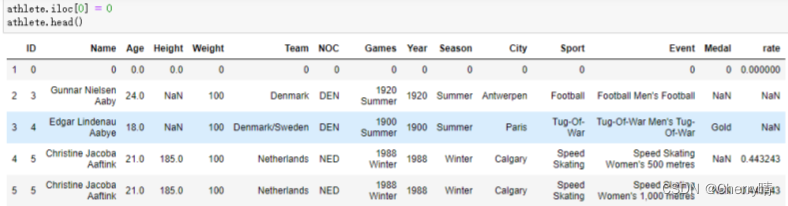
1.5 描述性统计
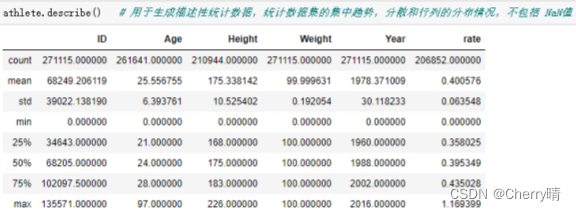
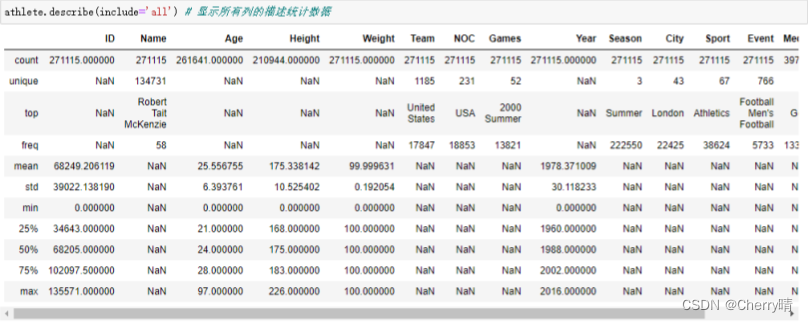
1.5.1 describe( )方法——用于生成描述性统计数据,软计数据集的集中趋势,分教和行列的分布情况,不包括NaN值
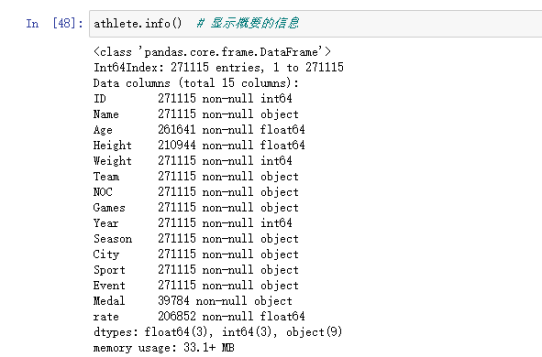
1.5.2 info( )方法 ——显示概要信息
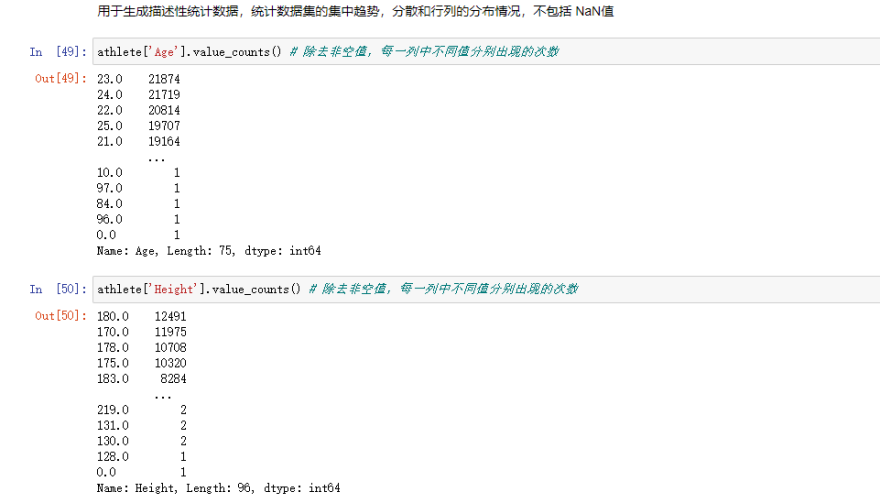
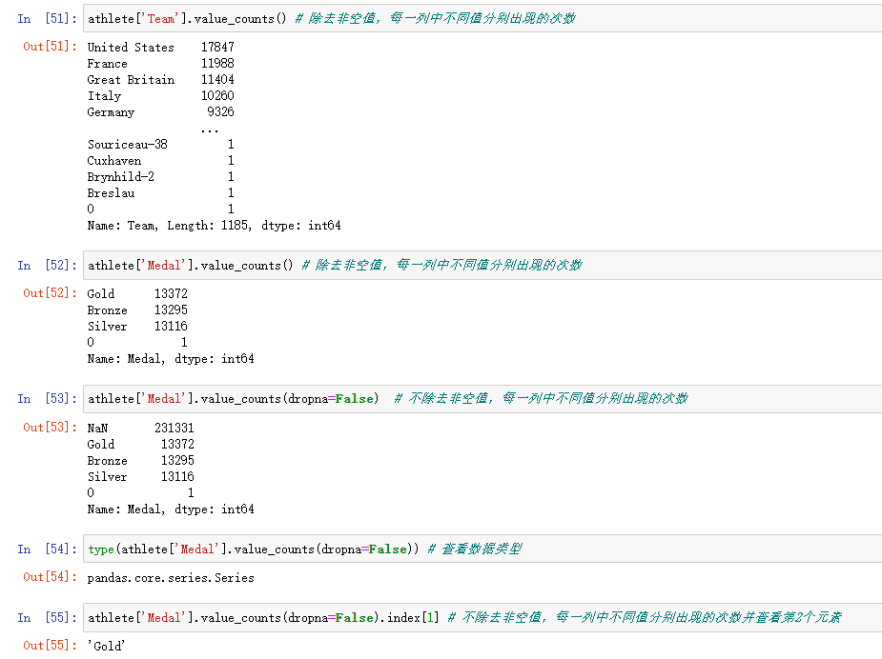
1.5.3 value_counts函数——统计某列中各个值的出现次数
- value counts(normalize=False, sort=True, ascending=False, bins=None, dropna=True)
| nommalize | 布尔值,默认=False,如为true,则以百分比的形式显示 |
| sort | 布尔值,默认=True,对结果进行排序 |
| ascending | 布尔值,默认降序False排列 |
| bins | intege,格式(bins=1),意义不是执行计算,而是把它们分成半开放的数据出合,只适用于数字数据 |
| dropna | 布尔值,默认=True,默认删除na值 |
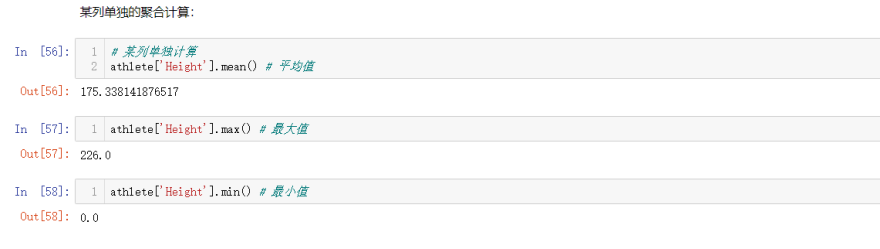
1.5.4 mean、max、min单独计算
注意:本文中数据以及内容若有侵权,请第一时间联系删除。
本文是作者个人学习后的总结,未经作者授权,禁止转载,谢谢配合。
















 875
875











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











