









刚开始跑caffe试验,老是遇见各种错误。今天又遇见:
这明显是内存不够,但是我们服务器足够大,有20G的内存,用top命令查看内存的使用情况,空间也很大,开始我以为我的数据太大了,可是还不到2G:I1214 10:00:57.934880 11810 net.cpp:165] Memory required for data: 1137538000.
最后问师兄,大概是使用查看的内存命令不对,他们使用的是:
nvidia-smi
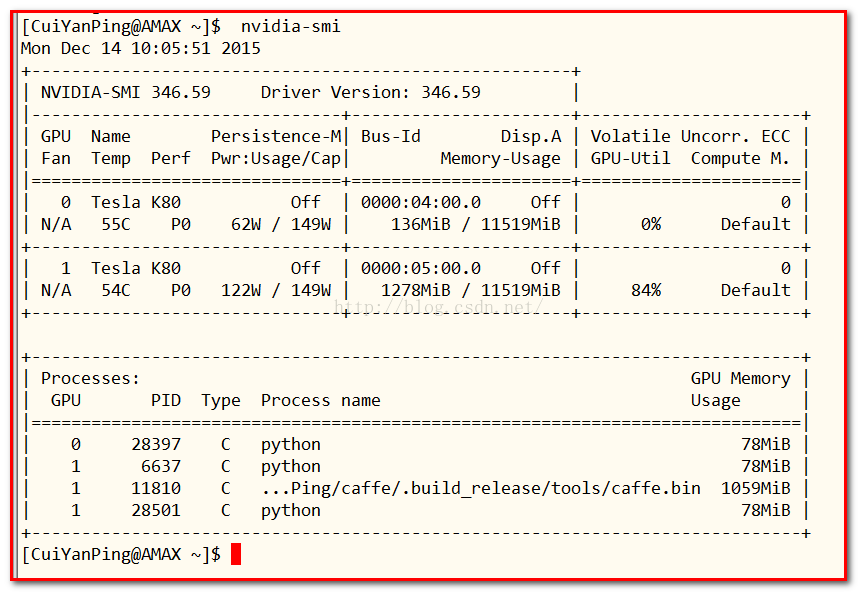
发现有top命令无法查看到的进程,将这些进程杀死掉,释放内存:
杀死进程命令:kill -9 PID
最后重新运行试验,就可以开始跑了,最后我终于知道为什么了:
top是监视CPU的,而 nvidia-smi才是监视GPU的。
nvidia-smi是用来查看GPU使用情况的。我常用这个命令判断哪几块GPU空闲,但是最近的GPU使用状态让我很困惑,于是把nvidia-smi命令显示的GPU使用表中各个内容的具体含义解释一下。
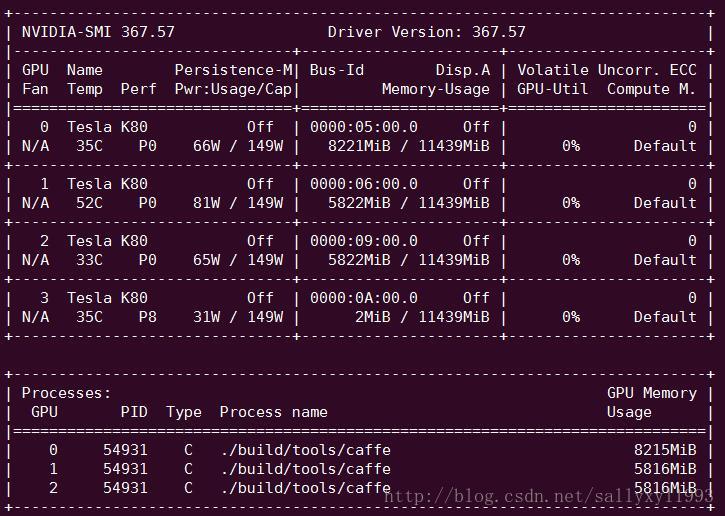
这是服务器上特斯拉K80的信息。
上面的表格中:
第一栏的Fan:N/A是风扇转速,从0到100%之间变动,这个速度是计算机期望的风扇转速,实际情况下如果风扇堵转,可能打不到显示的转速。有的设备不会返回转速,因为它不依赖风扇冷却而是通过其他外设保持低温(比如我们实验室的服务器是常年放在空调房间里的)。
第二栏的Temp:是温度,单位摄氏度。
第三栏的Perf:是性能状态,从P0到P12,P0表示最大性能,P12表示状态最小性能。
第四栏下方的Pwr:是能耗,上方的Persistence-M:是持续模式的状态,持续模式虽然耗能大,但是在新的GPU应用启动时,花费的时间更少,这里显示的是off的状态。
第五栏的Bus-Id是涉及GPU总线的东西,domain:bus:device.function
第六栏的Disp.A是Display Active,表示GPU的显示是否初始化。
第五第六栏下方的Memory Usage是显存使用率。
第七栏是浮动的GPU利用率。
第八栏上方是关于ECC的东西。
第八栏下方Compute M是计算模式。
下面一张表示每个进程占用的显存使用率。
显存占用和GPU占用是两个不一样的东西,显卡是由GPU和显存等组成的,显存和GPU的关系有点类似于内存和CPU的关系。我跑caffe代码的时候显存占得少,GPU占得多,师弟跑TensorFlow代码的时候,显存占得多,GPU占得少。

















 1990
1990

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









