








 超级会员免费看
超级会员免费看

成本比较:向量检索 v.s. Cross-encoder Reranker v.s. 大模型生成
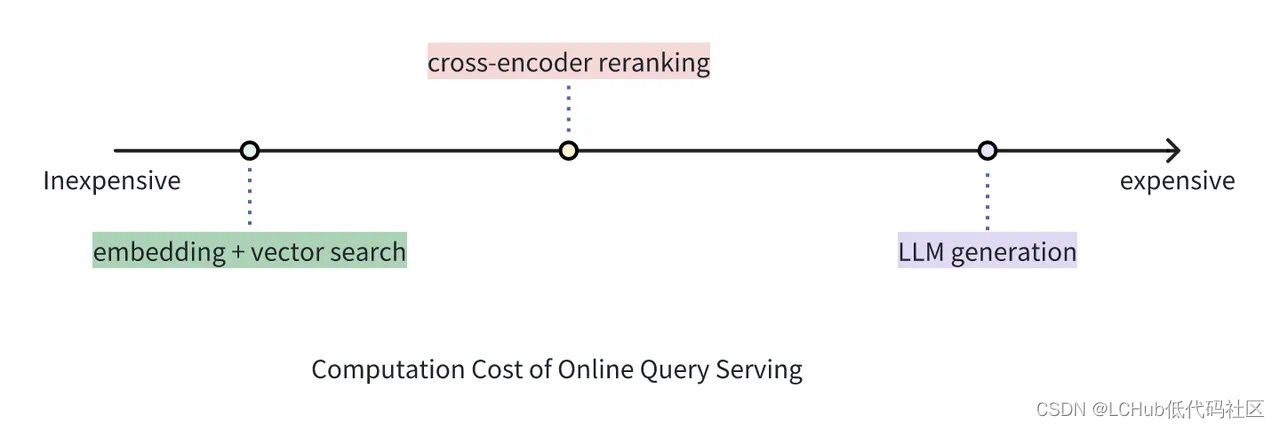
虽然 Reranker 的使用成本远高于单纯使用向量检索的成本,但它仍然比使用 LLM 为同等数量文档生成答案的成本要低。在 RAG 架构中,Reranker 可以筛选向量搜索的初步结果,丢弃掉与查询相关性低的文档,从而有效防止 LLM 处理无关信息,相比于将向量搜索返回的结果全部送进 LLM 可大大减少生成部分的耗时和成本。
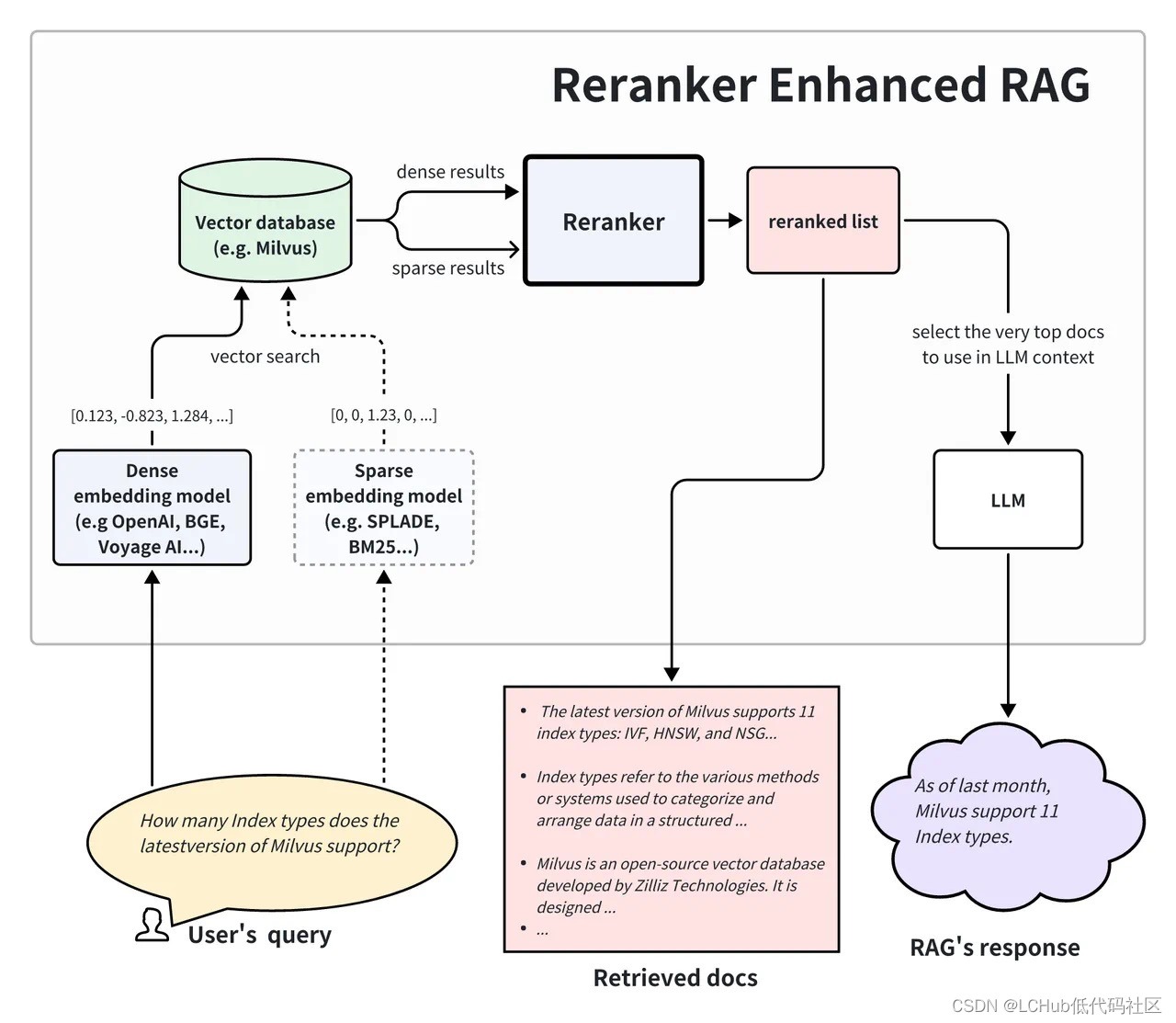
举一个贴近实际的例子:第一阶段检索中,向量搜索引擎可以在数百万个向量中快速筛选出语义近似度最高的 20 个文档,但这些文档的相对顺序还可以使用 Reranker 进一步优化。虽然会产生一定的成本,但 Reranker 可以在 top-20 个结果进一步挑出最好的 top-5 个结果。那么,相对更加昂贵的 LLM 只需要分析这 top-5 个结果即可,免去了处理 20 个文档带来的更高成本和注意力“涣散”的问题。这样一来,我们就可以通过这种复合方案平衡延迟、回答质量和使用成本。
哪种情况适合在 RAG 应用中使用 Reranker?

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 349
349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











