







1,为什么要对特征做归一化?
归一化的目的是希望输入数据的不同维度的特征具有相近的取值范围,从而能够更快的通过梯度下降找到最优解。
特征间的单位(尺度)可能不同,单位的不同会导致计算结果的不同,尺度大的特征会起决定性作用,而尺度小的特征其作用可能会被忽略,为了消除特征间单位和尺度差异的影响,以对每维特征同等看待,需要对特征进行归一化。
原始特征下,因尺度差异,其损失函数的等高线图可能是椭圆形,梯度方向垂直于等高线,下降会走zigzag路线,而不是指向local minimum。通过对特征进行zero-mean and unit-variance变换后,其损失函数的等高线图更接近圆形,梯度下降的方向震荡更小,收敛更快。
实际应用中,通过梯度下降法求解的模型,通常需要归一化,包括线性回归、逻辑回归、支持向量机、神经网络。
但是对于决策树模型并不适用,决策树在进行节点分裂时主要依据数据集D关于各维度特征的信息增益比,而信息增益比与是否归一化无关,归一化不会改变样本在各特征上的信息增益。
归一化方法
1.1 线性函数归一化
对原始数据进行归一化,将其取值范围映射到[0,1]之间,实现对原始数据的等比缩放。
计算公式: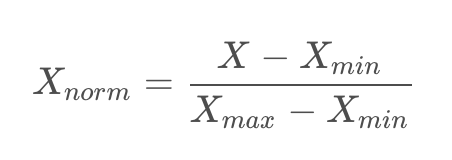
1.2 零均值归一化
将原始数据映射到均值为0、标准差为1的分布上。
计算公式: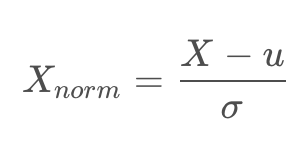
1.3 逐样本的均值消减
在每个样本上减去数据的统计平均值,用于平稳的数据(即数据每一个维度的统计都服从相同分布),对图像一般只用在灰度图上,也就是对图像的各像素点减去其均值。
以上几种归一化方法中:
- 减一个统计量可以看成选哪个值作为原点,是最小值还是均值,并将整个数据集平移到这个新的原点位置。如果特征间偏置不同对后续过程有负面影响,则该操作是有益的,可以看成是某种偏置无关操作;如果原始特征值有特殊意义,比如稀疏性,该操作可能会破坏其稀疏性。
- 除以一个统计量可以看成在坐标轴方向上对特征进行缩放,用于降低特征尺度的影响,可以看成是某种尺度无关操作。缩放可以使用最大值最小值间的跨度,也可以使用标准差(到中心点的平均距离),前者对outliers敏感,outliers对后者影响与outliers数量和数据集大小有关,outliers越少数据集越大影响越小。
- 除以长度相当于把长度归一化,把所有样本映射到单位球上,可以看成是某种长度无关操作,比如,词频特征要移除文章长度的影响,图像处理中某些特征要移除光照强度的影响,以及方便计算余弦距离或内积相似度等。
彩色图像的常见归一化处理过程,一般都是在3个通道上分别减去127.5,然后再除以128。这样做的目的是使得图像的三个通道像素值的取值范围变到[-1,1]之间,好处是:

https://www.cnblogs.com/shine-lee/p/11779514.html
2,什么是组合特征?如何处理高维组合特征?
特征组合是指通过将两个或多个输入特征相乘来对特征空间中的非线性规律进行编码的合成特征。特征的相乘组合可以提供超出这些特征单独能够提供的预测能力,有助于表达非线性关系。
在处理高维组合特征时,往往需要进行特征降维,去除不重要的特征,用低维向量来表示高维特征。如矩阵分解。
3,请比较欧式距离与曼哈顿距离?
欧几里得度量(euclidean metric)(也称欧氏距离)是一个通常采用的距离定义,指在m维空间中两个点之间的真实距离。欧氏距离越小,两个向量的相似度越大;欧氏距离越大,两个向量的相似度越小。
曼哈顿距离也称为城市街区距离。可以看出在曼哈顿距离中,考虑了更多的实际 因素。总之,在曼哈顿距离的世界中,规则是我们只能沿着线画出的格子行进。对异常值敏感。曼哈顿距离将向量各个维度之间的差异等同对待。
向量各个属性之间的差距越大,则曼哈顿距离越接近欧式距离。
4,为什么一些场景中使用余弦相似度而不是欧式距离?
欧式距离体现在数值上的绝对差异,而余弦距离是体现在方向上的相对差异。
余弦相似度即2个向量夹角的余弦。关注的是向量之间的角度关系,并不关心他们的绝对大小,余弦相似度的取值范围是【-1,1】,余弦相似度衡量的是维度间取值方向的一致性,注重维度之间的差异,不注重数值上的差异,而欧氏度量的正是数值上的差异性。
5,One-hot的作用是什么?为什么不直接使用数字作为表示?
One-hot 主要用来编码类别特征,即采用哑变量(dummy variables) 对类别进行编码。它的作用是避免因将类别用数字作为表示而给函数带来抖动。
直接使用数字会给将人工误差而导致的假设引入到类别特征中,比如类别之间的大小关系,以及差异关系等等
6,在模型评估过程中,过拟合和欠拟合具体指什么现象?
过拟合是指模型在训练数据拟合呈过当的情况,反应到评估指标上,就是模型在训练集上的表现很好,但在测试集和新数据上的表现很差。欠拟合指的是模型在训练和预测时都不好的情况。
7,降低过拟合和欠拟合的方法?
降低过拟合风险的方法:
1).从数据入手,获得更多的训练数据。使用更多的训练数据是解决过拟合问题最有效的手段,因为更多的样本能够让模型学习到更多更有效的特征,减少噪声的影响。当然,直接增加实验数据一般是很困难的,但是可以通过一定的规则来扩充训练数据。比如在图像分类问题上,可以通过图像的平移,旋转,缩放等方式扩充数据,更进一步地,可以使用生成式对抗网络来合成大量新训练数据。
2).降低模型的复杂度,在数据较少时,模型过于复杂是产生过拟合的主要因素,适当降低模型复杂化度可以避免模型拟合过多的采样噪声。例如在神经网络模型中减少网络层数,神经元个数等,在决策树模型中降低树的深度,进行剪枝。如加入dropout。
3),正则化方法。给模型参数加上一定正则约束,比如将权值大小加入到损失函数总。
4).集成学习方法。集成学习是吧多个模型集成在一起,来降低单一模型过拟合风险,如Bagging方法。
5),提早停止训练
降低欠拟合风险的方法:
1).添加新特性。当特征不足或者现有特征与样本标签的相关性不强时,模型容易出现欠拟合。通过挖掘上下文特征 ID类特征 组合特征 等新的特征,往往能够取得很好的效果。在深度学习的潮流中,有很多模型可以帮助完成特征工程,如因子分解机,梯度提升决策树,Depp-corssing等都成为丰富特征的方法。
2).增加模型复杂度,简单模型的学习能力较差,通过增加模型的复杂度可以使模型拥有更强的拟合能力。例如在线性模型中增加高次项,在神经网络模型中增加网络层数和神经元个数。
3).减小正则化系数。正则化是用来防止过拟合的,但当模型出现欠拟合现象时,则需要有针对性的减小正则化系数。















 2529
2529











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









