







-
-
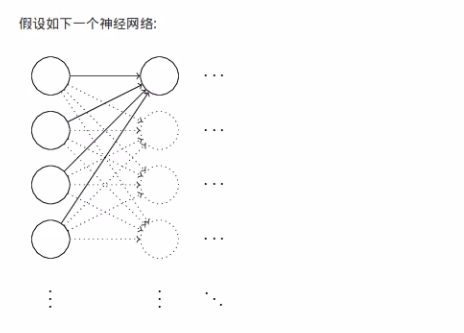
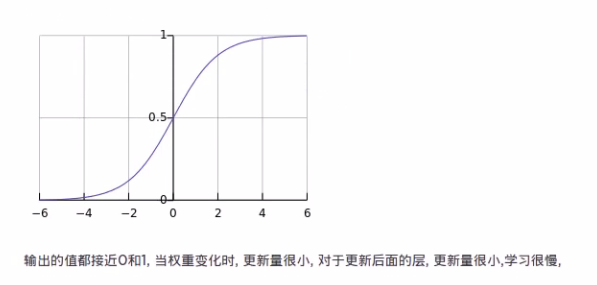
使隐藏层饱和了, 跟之前我们说的输出层饱和问题相似, 对于输出层,我们用改进的cost函数,比如cross-entropy, 但是对于隐藏层, 我们无法通过cost函数来改进
更好的方法来初始化权重? -
因为传统的初始化权重问题是用标准正态分布(均值为0,方差为1)随机初始化的,这其实是存在不合理的部分。
-
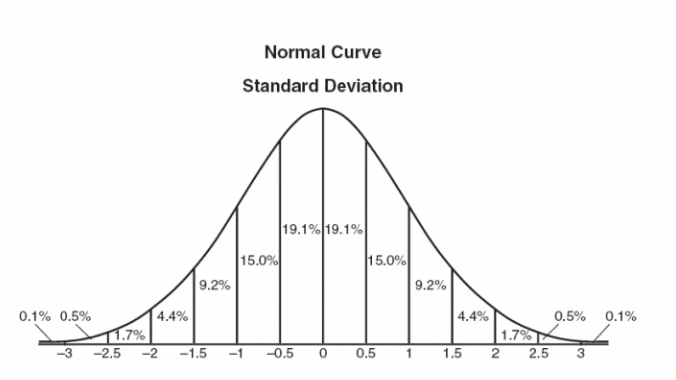
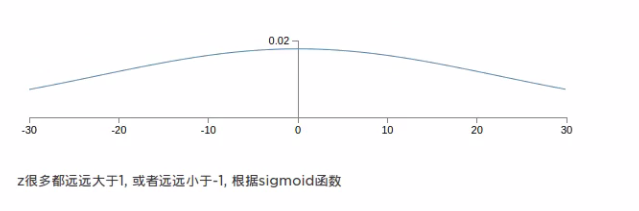
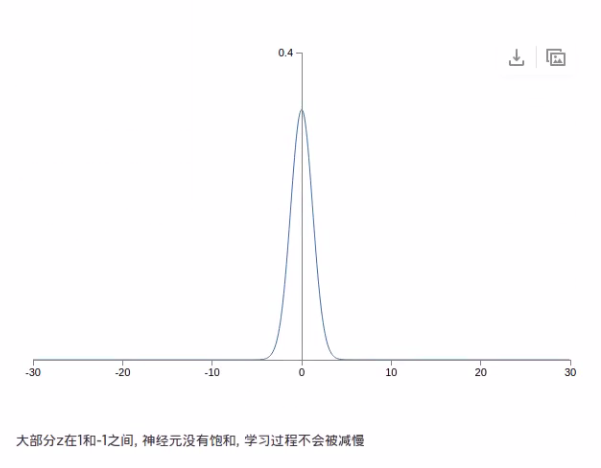
标准正态分布:
可以看出真实数据的分布其实是在靠近坡峰的部分,符合正态分布的。
-
-

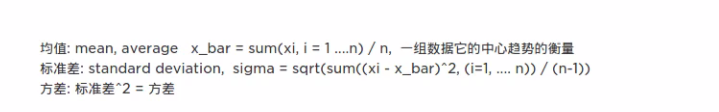
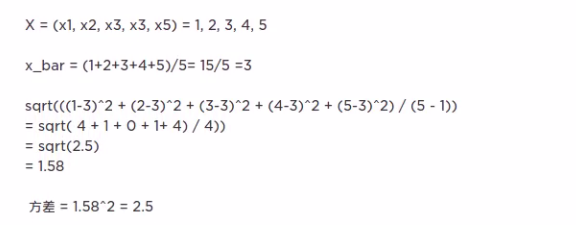


















05-20
 4819
4819
4819
07-27

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









