






一、介绍
本节将通过Bert模型来完成中文地址的自动解析任务。
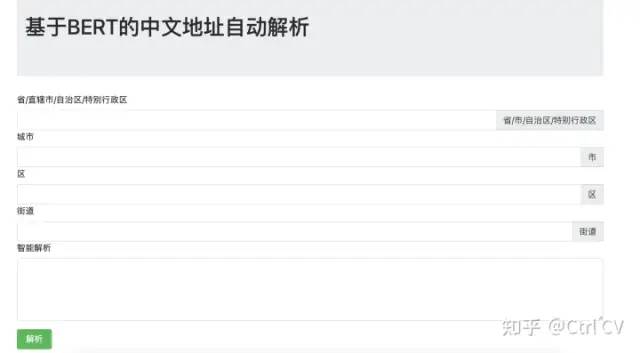
类似于寄送快递单时自动识别文字的地址并进行划分省、市、区、街道等不同字段信息。最终实现的效果见文章结尾:

二、BERT模型
关于BERT模型的介绍参考之前的文章
三、代码实现
3.1、导包与模型配置
import osimport timeimport pickleimport randomimport sklearnimport torchimport torch.nn.functional as Ffrom torch import nnfrom tqdm import tqdmimport randomfrom sklearn.metrics import f1_scorefrom transformers import AdamW, get_linear_schedule_with_warmupdevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')max_train_epochs = 6warmup_proportion = 0.05gradient_accumulation_steps = 1train_batch_size = 32valid_batch_size = 32test_batch_size = 32data_workers = 2save_checkpoint = Falselearning_rate = 5e-5weight_decay = 0.01max_grad_norm = 1.0use_amp = Falseif use_amp:import apexcur_time = time.strftime('%Y-%m-%d_%H:%M:%S')base_path = './data/'# model_select = 'roberta'# model_select = 'albert'model_select = 'bert'if model_select == 'bert':from transformers import BertConfig, BertTokenizer, BertModel, BertForTokenClassificationpretrain_path = 'pretrain_model/bert-base-chinese/'cls_token = '[CLS]'eos_token = '[SEP]'unk_token = '[UNK]'pad_token = '[PAD]'mask_token = '[MASK]'config = BertConfig.from_json_file(pretrain_path + 'config.json')tokenizer = BertTokenizer.from_pretrained(pretrain_path)TheModel = BertModelModelForTokenClassification = BertForTokenClassificationelif model_select == 'roberta':from transformers import RobertaConfig, RobertaTokenizer, RobertaModel, RobertaForTokenClassificationpretrain_path = 'pretrain_model/robert-base-chinese/'cls_token = '<s>'eos_token = '</s>'unk_token = '<unk>'pad_token = '<pad>'mask_token = '<mask>'config = RobertaConfig.from_json_file(pretrain_path+'config.json')tokenizer = RobertaTokenizer.from_pretrained(pretrain_path)TheModel = RobertaModelModelForTokenClassification = RobertaForTokenClassificationelse:raise NotImplementedError()eos_id = tokenizer.convert_tokens_to_ids([eos_token])[0]unk_id = tokenizer.convert_tokens_to_ids([unk_token])[0]period_id = tokenizer.convert_tokens_to_ids(['.'])[0]print(model_select, eos_id, unk_id, period_id)
3.2、构建数据与标签
# 标签labels = ['B-assist', 'I-assist', 'B-cellno', 'I-cellno', 'B-city', 'I-city', 'B-community', 'I-community', 'B-country', 'I-country', 'B-devZone', 'I-devZone', 'B-district', 'I-district', 'B-floorno', 'I-floorno', 'B-houseno', 'I-houseno', 'B-otherinfo', 'I-otherinfo', 'B-person', 'I-person', 'B-poi', 'I-poi', 'B-prov', 'I-prov', 'B-redundant', 'I-redundant', 'B-road', 'I-road', 'B-roadno', 'I-roadno', 'B-roomno', 'I-roomno', 'B-subRoad', 'I-subRoad', 'B-subRoadno', 'I-subRoadno', 'B-subpoi', 'I-subpoi', 'B-subroad', 'I-subroad', 'B-subroadno', 'I-subroadno', 'B-town', 'I-town']label2id = {}for i, l in enumerate(labels):label2id[l] = inum_labels = len(labels)print(num_labels)# 载入数据f_train = open(base_path + 'train.txt')f_test = open(base_path + 'test.txt')f_dev = open(base_path + 'dev.txt')# from load_data import *def get_data_list(f):data_list = []origin_token, token, label = [], [], []for l in f:l = l.strip().split()if not l:data_list.append([token, label, origin_token])origin_token, token, label = [], [], []continuefor i, tok in enumerate(l[0]):token.append(tok)label.append(label2id[l[1]])origin_token.append(l[0])assert len(token) == 0return data_listtrain_list = get_data_list(f_train)test_list = get_data_list(f_test)dev_list = get_data_list(f_dev)print(len(train_list), len(test_list), len(dev_list))max_token_len = 0for ls in [train_list, test_list, dev_list]:for l in ls:max_token_len = max(max_token_len, len(l[0]))print('max_token_len', max_token_len)
3.3、构建Dataset与DataLoader
class MyDataSet(torch.utils.data.Dataset):def __init__(self, examples):self.examples = examplesdef __len__(self):return len(self.examples)def __getitem__(self, index):example = self.examples[index]sentence = example[0]label = example[1]sentence_len = len(sentence)pad_len = max_token_len - sentence_lentotal_len = sentence_len + 2input_token = [cls_token] + sentence + [eos_token] + [pad_token] * pad_leninput_ids = tokenizer.convert_tokens_to_ids(input_token)attention_mask = [1] + [1] * sentence_len + [1] + [0] * pad_lenlabel = [-100] + label + [-100] + [-100] * pad_lenassert max_token_len + 2 == len(input_ids) == len(attention_mask) == len(input_token)return input_ids, attention_mask, total_len, label, indexdef the_collate_fn(batch):total_lens = [b[2] for b in batch]total_len = max(total_lens)input_ids = torch.LongTensor([b[0] for b in batch])attention_mask = torch.LongTensor([b[1] for b in batch])label = torch.LongTensor([b[3] for b in batch])input_ids = input_ids[:, :total_len]attention_mask = attention_mask[:, :total_len]label = label[:, :total_len]indexs = [b[4] for b in batch]return input_ids, attention_mask, label, indexstrain_dataset = MyDataSet(train_list)train_data_loader = torch.utils.data.DataLoader(train_dataset,batch_size=train_batch_size,shuffle=True,num_workers=data_workers,collate_fn=the_collate_fn,)def the_collate_fn(batch):total_lens = [b[2] for b in batch]total_len = max(total_lens)input_ids = torch.LongTensor([b[0] for b in batch])attention_mask = torch.LongTensor([b[1] for b in batch])label = torch.LongTensor([b[3] for b in batch])input_ids = input_ids[:,:total_len]attention_mask = attention_mask[:,:total_len]label = label[:,:total_len]indexs = [b[4] for b in batch]return input_ids, attention_mask, label, indexstrain_dataset = MyDataSet(train_list)train_data_loader = torch.utils.data.DataLoader(train_dataset,batch_size=train_batch_size,shuffle = True,num_workers=data_workers,collate_fn=the_collate_fn,)test_dataset = MyDataSet(test_list)test_data_loader = torch.utils.data.DataLoader(test_dataset,batch_size=train_batch_size,shuffle = False,num_workers=data_workers,collate_fn=the_collate_fn,)
3.4、定义模型
def eval():result = []for step, batch in enumerate(tqdm(test_data_loader)):input_ids, attention_mask, label = (b.to(device) for b in batch[:-1])with torch.no_grad():logits = model(input_ids, attention_mask)logits = F.softmax(logits, dim=-1)logits = logits.data.cpu()logit_list = []sum_len = 0for m in attention_mask:l = m.sum().cpu().item()logit_list.append(logits[sum_len:sum_len+l])sum_len += lassert sum_len == len(logits)for i, l in enumerate(logit_list):rr = torch.argmax(l, dim=1)for j, w in enumerate(test_list[batch[-1][i]][0]):result.append([w, labels[label[i][j+1].cpu().item()],labels[rr[j+1]]])result.append([])print(result[:20])return resultdef log(msg):# with open(cur_time + '.log', 'a') as f:# f.write(time.strftime("%Y-%m-%d_%H:%M:%S") + '\t' + str(msg) + '\n')print(msg)class BertForSeqTagging(ModelForTokenClassification):def __init__(self):super().__init__(config)self.num_labels = num_labelsself.bert = TheModel.from_pretrained('bert-base-chinese')self.dropout = torch.nn.Dropout(config.hidden_dropout_prob)self.classifier = torch.nn.Linear(config.hidden_size, num_labels)self.init_weights()def forward(self, input_ids, attention_mask, labels=None):outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)sequence_output = outputs[0]batch_size, max_len, feature_dim = sequence_output.shapesequence_output = self.dropout(sequence_output)logits = self.classifier(sequence_output)active_loss = attention_mask.view(-1) == 1active_logits = logits.view(-1, self.num_labels)[active_loss]if labels is not None:loss_fct = torch.nn.CrossEntropyLoss()active_labels = labels.view(-1)[active_loss]loss = loss_fct(active_logits, active_labels)return losselse:return active_logitsmodel = BertForSeqTagging()model.to(device)t_total = len(train_data_loader) // gradient_accumulation_steps * max_train_epochs + 1num_warmup_steps = int(warmup_proportion * t_total)log('warmup steps : %d' % num_warmup_steps)no_decay = ['bias', 'LayerNorm.weight'] # no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']param_optimizer = list(model.named_parameters())optimizer_grouped_parameters = [{'params':[p for n, p in param_optimizer if not any(nd in n for nd in no_decay)],'weight_decay': weight_decay},{'params':[p for n, p in param_optimizer if any(nd in n for nd in no_decay)],'weight_decay': 0.0}]optimizer = AdamW(optimizer_grouped_parameters, lr=learning_rate, correct_bias=False)scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=num_warmup_steps, num_training_steps=t_total)
3.5、模型训练
# for epoch in range(max_train_epochs):# # train# epoch_loss = None# epoch_step = 0# start_time = time.time()# model.train()# for step, batch in enumerate(tqdm(train_data_loader)):# input_ids, attention_mask, label = (b.to(device) for b in batch[:-1])# loss = model(input_ids, attention_mask, label)# loss.backward()# # torch.nn.utils.clip_grad_norm_(model.parameters(), max_grad_norm)# if (step + 1) % gradient_accumulation_steps == 0:# optimizer.step()# scheduler.step()# optimizer.zero_grad()## if epoch_loss is None:# epoch_loss = loss.item()# else:# epoch_loss = 0.98 * epoch_loss + 0.02 * loss.item()# epoch_step += 1## used_time = (time.time() - start_time) / 60# log('Epoch = %d Epoch Mean Loss %.4f Time %.2f min' % (epoch, epoch_loss, used_time))# result = eval()# with open('result.txt', 'w') as f:# for r in result:# f.write('\t'.join(r) + '\n')# y_true = []# y_pred = []# for r in result:# if not r: continue# y_true.append(label2id[r[1]])# y_pred.append(label2id[r[2]])# print(f1_score(y_true, y_pred, average='micro'))
加载Bert中文预训练模型训练了6个epoch,最终达到的精度为88.6%。

3.6、模型测试
# 加载训练好的模型model = BertForSeqTagging()model.to(device)model.load_state_dict(torch.load('bert.pkl', map_location=torch.device('cpu')))def print_address_info(address, model):input_token = [cls_token] + list(address) + [eos_token]input_ids = tokenizer.convert_tokens_to_ids(input_token)attention_mask = [1] * (len(address) + 2)ids = torch.LongTensor([input_ids])atten_mask = torch.LongTensor([attention_mask])# x = model(ids, atten_mask)logits = model(ids, atten_mask)logits = F.softmax(logits, dim=-1)logits = logits.data.cpu()rr = torch.argmax(logits, dim=1)# print(rr)import collectionsr = collections.defaultdict(list)for i, x in enumerate(rr.numpy().tolist()[1:-1]):print(address[i], labels[x])r[labels[x][2:]].append(address[i])return rr = print_address_info('广东省汕头市龙湖区黄山路30号荣兴大厦', model)print(r)
得到结果如下:
广 B-prov东 I-prov省 I-prov汕 B-city头 I-city市 I-city龙 B-district湖 I-district区 I-district黄 B-road山 I-road路 I-road3 B-roadno0 B-roadno号 I-roadno荣 B-poi兴 I-poi大 I-poi厦 I-poidefaultdict(<class 'list'>, {'prov': ['广', '东', '省'], 'city': ['汕', '头', '市'], 'district': ['龙', '湖', '区'], 'road': ['黄', '山', '路'], 'roadno': ['3', '0', '号'], 'poi': ['荣', '兴', '大', '厦']})
可以看出模型基本能够识别出地址信息。
四、通过Flask构建web端界面
from flask import Flask, request, render_template, session, redirect, url_forfrom model import get_address_infoapp = Flask(__name__)@app.route('/')def index():return render_template('index.html')@app.route('/parse_address/')def parse_address():addr = request.args.get('addr', None)r = get_address_info(addr)for k in r:r[k] = ''.join(r[k])return rif __name__=='__main__':app.run(host='0.0.0.0', port=1234)"""广东省汕头市龙湖区黄山路30号荣兴大厦安徽省黄山市黄山区205国道云南省丽江市古城区北京市东城区东长安街江苏省南京市建邺区江东中路222号"""
最终实现的结果如下:

可以看到解析后的地址完全正确,也可以尝试使用不同的模型进行地址解析
















 2723
2723











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











