








参考
https://andrew.gibiansky.com/blog/machine-learning/baidu-allreduce/#
https://zhuanlan.zhihu.com/p/343951042
本文只记录一下,为什么DDP的通信比DP的高效。
1、DP
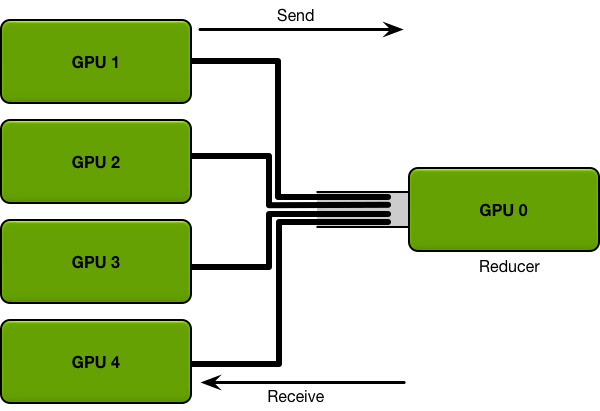
假设共有K个GPU,GPU的通信带宽是B,每个GPU要发送的数据量是P(所有参数的梯度信息),那GPU0接收完所有信息,需要耗时(K-1)P/B,GPU0更新完参数后,需要同步给其他GPU,又需要耗时(K-1)P/B,所以每迭代训练一次,通信耗时2(K-1)P/B,耗时和GPU数量线性相关。
2、DDP
DDP 支持 Ring AllReduce,其通信成本是恒定的,与 GPU 数量无关。
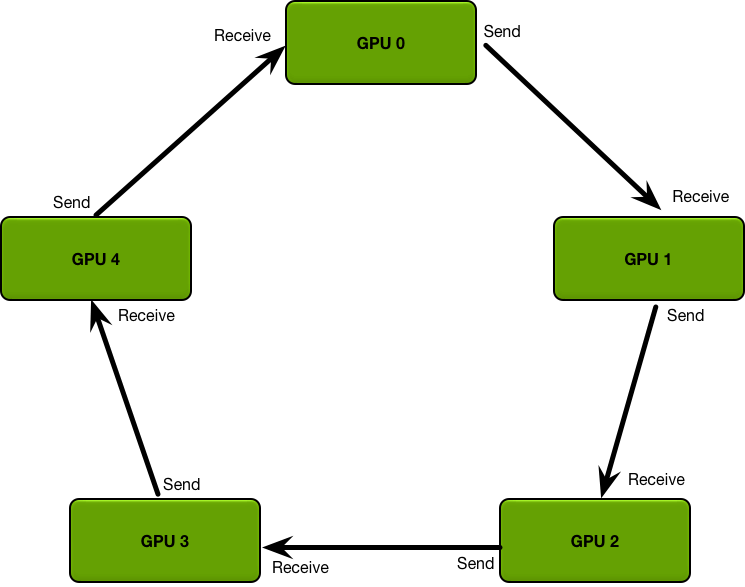
DDP模式下,GPU会把要同步的数据分成K份,K为GPU的个数,每次循环每个GPU需要接收和发送的数据量为P/K。
首先是Scatter-reduce过程,下图第一次循环的情况:
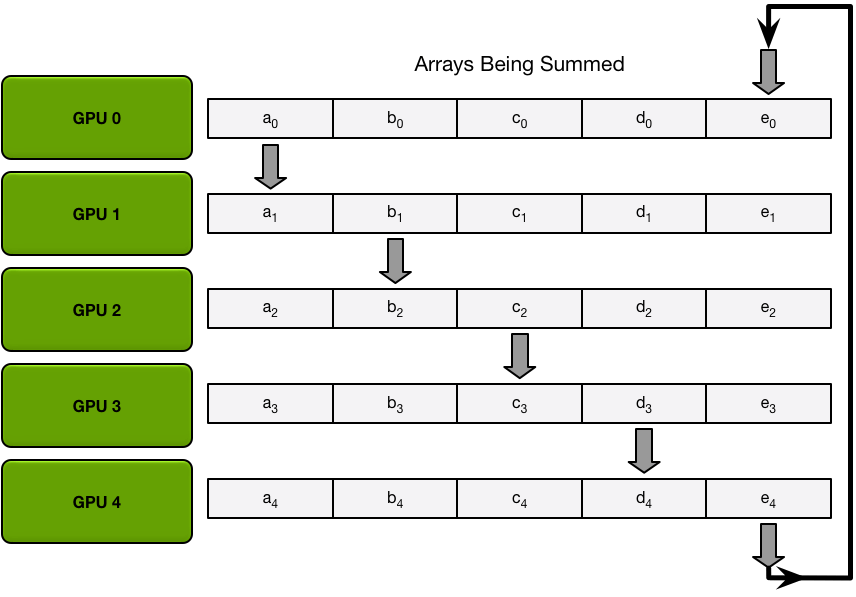
第一次循环后,每个GPU会把收到的数据和自己的数据进行相加,然后进行下一个循环:
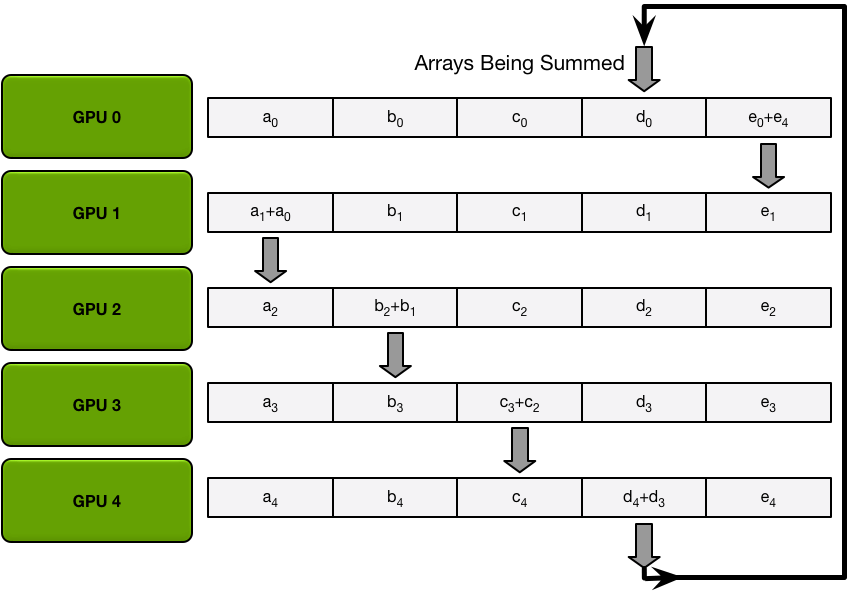
经过K-1次后,每个GPU都有其中一部分参数的完整数据,比如GPU0有完整的b,GPU1有完整的c。
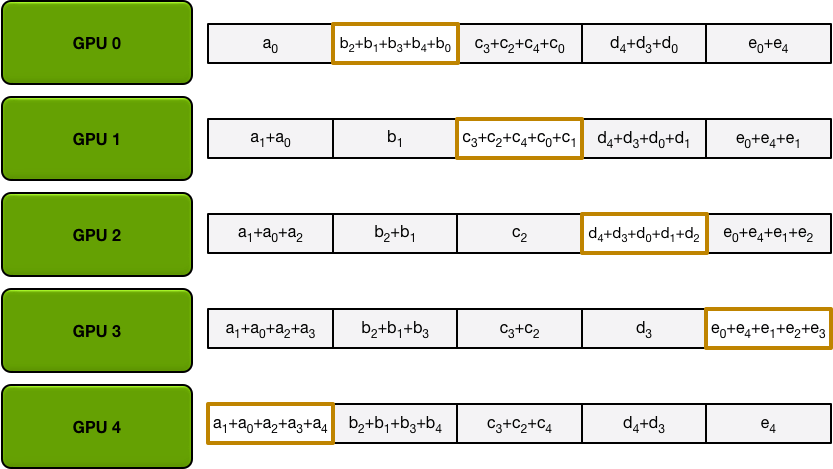
经过上述的Scatter-reduce后,后续再进行Allgather。
Allgather第一次循环:
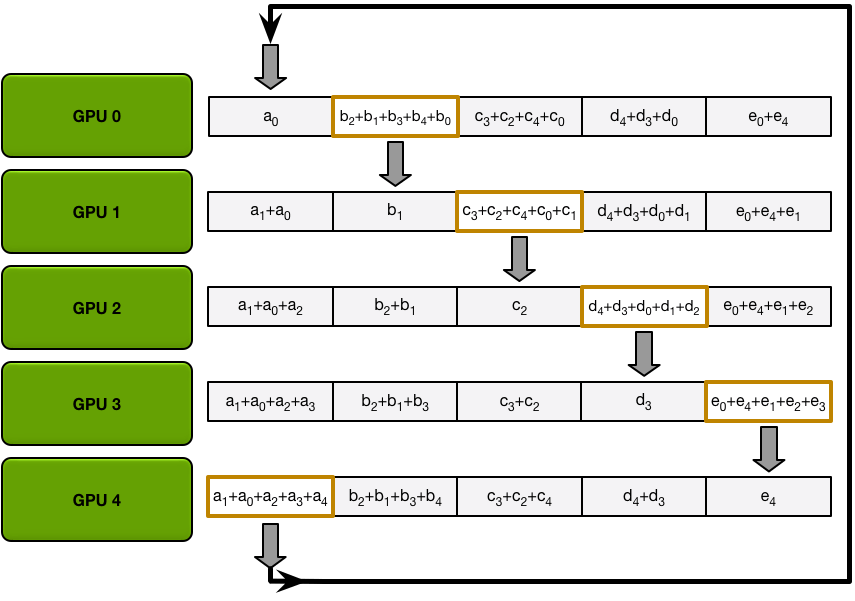
第二次循环:
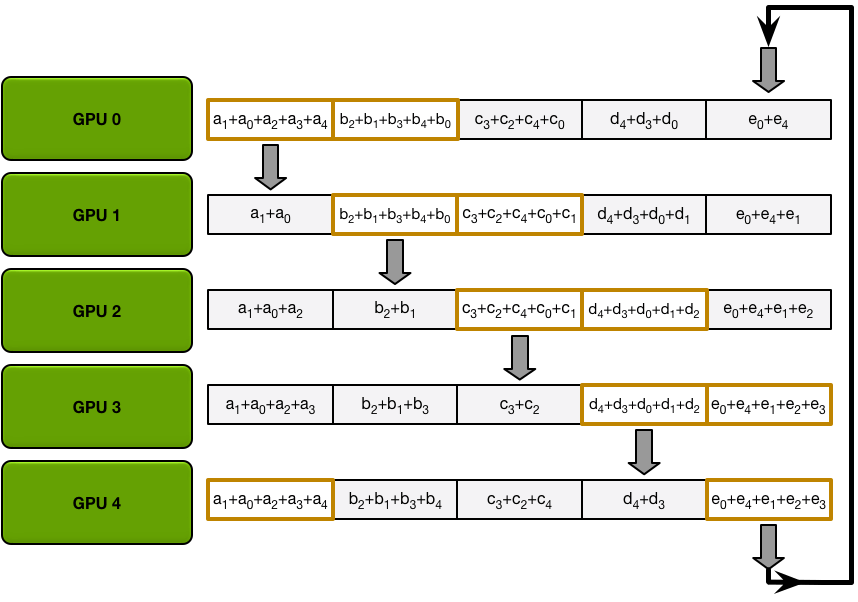
经过K-1次后,所有的GPU都有所有参数的完整数据:

所以整个同步过程需要时间为2(K-1)(P/K)/B,耗时不会随着GPU数量增加而等比增加,大大提高了GPU之间的数据同步效率。














 976
976











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









