







RAG 101:简介
大型语言模型(Large Language Models)旨在理解和生成人类语言。这些模型经过大量数据的训练,可以根据输入内容生成一系列响应内容。虽然它们在内容创作、客户支持、翻译、文档处理和编程等领域带来了变革,但在真正“理解”语言方面仍然存在挑战和限制。尤其是因为人类语言的复杂性。在本文中,将探讨 LLM 的一些局限性,并以示例说明 RAG 的相关操作。
传统 LLM 的局限性
- 传统 LLM 无法轻易扩展或更改其记忆。由于其记忆完全存在于训练模型权重和偏置中,因此没有简单的方法来扩展或修改现有记忆。
- 在没有内部细节的情况下,LL 无法直接提供关于如何得出特定预测的说明。
- 传统 LLM 的另一个重大问题是容易出现“幻觉”。这种情况可能由于多种原因发生,通常与训练数据不足有关,例如数据不充分、无法验证真实情况或过度泛化。
- 甚至是最大型的语言模型也难以记住训练数据中很少提及的知识。
要解决这些问题,需要使用者使用自己的知识。首先,从一个简单的 LLM 调用开始,可以输入一些内容,模型会给出适当的输出——使用 LangChain,因为它的设置更快,并且 LLM 可以被任何模型替代。

# Import the AzureChatOpenAI class from the langchain_openai module
from langchain_openai import AzureChatOpenAI
# Import the load_dotenv and find_dotenv functions from the dotenv module
# These functions are used to load environment variables from a .env file
from dotenv import load_dotenv, find_dotenv
# Load the environment variables from the .env file, if it exists
load_dotenv(find_dotenv())
# Create an instance of the AzureChatOpenAI class,
# which represents a Large Language Model (LLM) from Azure OpenAI service.
# The model used is "gpt-4o" and it's using the
# preview version of the API from March 2023.
# The 'verbose' parameter enables detailed logging for debugging.
# The 'temperature' parameter is set to 1, which controls the
# randomness of the model's outputs (higher values mean more randomness).
llm = AzureChatOpenAI(model="gpt-4o",
api_version="2023-03-15-preview",
verbose=True,
temperature=1)
# Invoke the LLM with a prompt of "Hi" to generate a response.
llm.invoke("Hi")
GPT-4o 会对此作出友好的问候。
AIMessage(content='Hello! How can I assist you today?',
additional_kwargs={},
response_metadata={'token_usage':
{'completion_tokens': 9, 'prompt_tokens': 8, 'total_tokens': 17,
'completion_tokens_details': None}, 'model_name': 'gpt-4o-2024-05-13',
'system_fingerprint': 'fp_67802d9a6d', 'finish_reason': 'stop',
'logprobs': None, 'content_filter_results': {}},
id='run-160f3379-db8c-4035-af27-3678eb7edfeb-0',
usage_metadata={'input_tokens': 8, 'output_tokens': 9, 'total_tokens': 17})
现在,问它几个问题并观察其表现;主要目标是查看上面提到的局限性是否可以重现。
llm.invoke("How many medals did USA win in 2024 Olympics?")
"""
As of my knowledge cutoff in October 2023, the 2024 Summer Olympics have
not yet occurred, so I am unable to provide the number of medals the USA won.
For the most current and accurate information,
please refer to up-to-date sources such as official Olympic websites
or reputable news outlets.
"""
llm.invoke("How many medals did USA win in the most recent Olympics?")
"""
AIMessage(content='The most recent Olympics as of 2023 were the
2020 Summer Olympics held in Tokyo, which actually took place in 2021
due to the COVID-19 pandemic. The United States won a total of 113 medals
at these games: 39 gold, 41 silver, and 33 bronze.
"""
llm.invoke("Who is Shanmukha Ranganath?")
"""
As of my last update in October 2023, there is no widely known public figure
or notable individual by the name of Shanmukha Ranganath.
It's possible that this person could be a private individual or
someone who has gained recognition in a specific field or community
that is not widely covered in mainstream media or public databases.
If you have more context or specific details about Shanmukha Ranganath,
such as their profession, achievements, or the context in which you came
across the name, I might be able to provide more targeted information.
"""
从以上输入和输出的示例中可以看出,LLM 的训练数据截止到 2023年10月,因此它不了解此后发生的任何事件。尽管它对第二个问题给出了正确的答案,但并没有提供一种简单的方法来核查其事实来源(如果 OpenAI 公开内部层权重,这可能实现)。最后,当被问及我的名字时,由于没有足够的数据供 LLM 形成权重,它无法识别我是谁。
解决这个问题的一种方法是为 LLM 提供必要的数据以提取答案,仅使用 LLM 的生成部分,提供更多的输入。可以使用2024年夏季奥运会美国代表团文章的第一部分作为输入(此文章内容来自维基百科),并结合我们的问题。
llm.invoke("""
The United States of America (USA), represented by the United States Olympic & Paralympic Committee (USOPC),
competed at the 2024 Summer Olympics in Paris from July 26 to August 11, 2024. U.S. athletes have appeared in every
Summer Olympic Games of the modern era, except for the 1980 edition in Moscow, when America led a sixty-six-nation
boycott in protest of the Soviet invasion of Afghanistan. As Los Angeles is hosting the 2028 Summer Olympics,
the United States marched penultimately before the homebound French team entered Place du Trocadéro during the
parade of nations segment of the opening ceremony. Additionally, an American segment featuring H.E.R. and Tom Cruise from Paris,
and the Red Hot Chili Peppers, Billie Eilish, Snoop Dogg, and Dr. Dre from Long Beach, was performed during the closing ceremony.
The opening ceremony flag-bearers for the United States were LeBron James and Coco Gauff.
James, a two-time Olympic gold medalist, is the first male basketball player to be chosen.[1][2]
At 20 years of age, Gauff is the youngest American athlete and the first tennis player to be so honored.[3][4]
The closing ceremony flag-bearers were Nick Mead and Katie Ledecky.
Mead was part of the U.S. men's four rowing team that won their first gold medal since 1960, while Ledecky,
a nine-time Olympic gold medalist, became the most decorated female Olympian to be chosen.[5]
The United States competed in all sports except handball and was represented by more female than male athletes for the
fourth consecutive time in the Summer Olympics (278 men and 314 women).[6]
The team topped the medal rankings for the fourth consecutive and 19th overall time, with a total of 40 gold, 44 silver,
and 42 bronze medals.[7] Tied with China on golds (40), the U.S. placed first in the overall medal tally via a
tiebreaker (44–27 in silver). The occasion marked the first time in Summer Olympic history that two countries
finished with an equal number of gold medals at the top.[8] Additionally, the Americans won 126 medals overall
compared to China's 91.[9][10]
How many medals did USA win in the most recent Olympics?
""")
"""
The United States won a total of 126 medals at the 2024 Summer Olympics
in Paris. This included 40 gold, 44 silver, and 42 bronze medals.
"""
太好了!刚刚扩展了 GPT-4o 的记忆!当提供更多的上下文信息以及问题时,可以更好地利用 LLM 的生成能力,并且通过正确的提示来信任提供的数据来源,可以最大限度地减少幻觉出现的可能性。接下来,与其每次都从维基百科复制段落,还是调用Tavily的搜索API更好,选择排名前3的文章,并将其作为输入发送给LLM。

import requests
import json
import os
url = "https://api.tavily.com/search"
payload = json.dumps({
"query": "How many medails did USA won in 2024 Olympics",
"api_key": os.getenv("TAVILY_API_KEY"),
"search_depth": "basic",
"topic": "general",
"include_answer": False,
"include_raw_content": False,
"include_images": False,
"include_image_descriptions": False,
"include_domains": [],
"max_results": 3
})
response = requests.request("POST", url, data=payload)
top_results = response.json()["results"]
context = str.join("\n\n", [result['content'] for result in top_results])
llm.invoke(f"""
{context}
How many medals did USA win in the most recent Olympics?
""")
"""At the 2024 Paris Olympics, the United States won a total of 126 medals.
This included 40 gold, 44 silver, and 42 bronze medals.
The USA led the overall medal count, followed by China with 91 medals
and Great Britain with 65 medals.
"""
这就是全部内容!刚刚扩展了 LLM 的记忆,根据需要进行了修改,减少了幻觉,并最终明确了其信息来源。这就是RAG——检索增强生成背后的理念。在 RAG 出现之前,已经有一些方式来解决这些问题,比如记忆网络、堆栈增强网络和记忆层等。然而,数据层通常在模型的权重内部,需要重新训练。RAG引入了一种最重要的方法,可以在不需要重新训练模型的情况下,更简单地增强LLM的记忆。
什么是RAG
RAG,即检索增强生成,是一种通过整合来自外部来源的相关信息来增强 LLM 响应的技术,从而在无需重新训练模型的情况下增强模型的预训练参数记忆。
简单来说,RAG 允许使用例如 GPT-4o 这样的现有模型结合外部知识,而不需要重新训练整个模型,从而将LLM的强大功能与外部数据的优势结合在一起。可以将其分为三个一般步骤——索引、检索和生成。
实际上,之前实现是一种称为 SearchRAG 的 RAG 变体。SearchRAG 是 RAG 的扩展,其中检索部分使用典型的搜索引擎进行查询,并将结果传递给生成器。由于检索器是一个搜索引擎,它不受限于传统 RAG 提供的知识库,可以使用互联网获取实时数据,因此拥有更广泛的信息,包括任何主题的最新更新和发展。像 Alphabet 和微软这样的公司承认,像 Gemini 和 GPT 这样的 LLM 长期以来一直为他们的搜索引擎 Google 和 Bing 提供支持。
但是,如何使其适用于个性化或公司特定且无法公开在互联网上使用的数据呢?简单,我们构建自己的强大内部搜索引擎!这不是玩笑,RAG 中检索增强步骤的最新理念和方法正是搜索引擎演变的方式。从基础索引到嵌入再到语义搜索及图搜索,这些都成为了 RAG 的一部分。让我们从基础 RAG 开始,了解每一步的内容,最终看看一个生产就绪的 RAG 是什么样子。
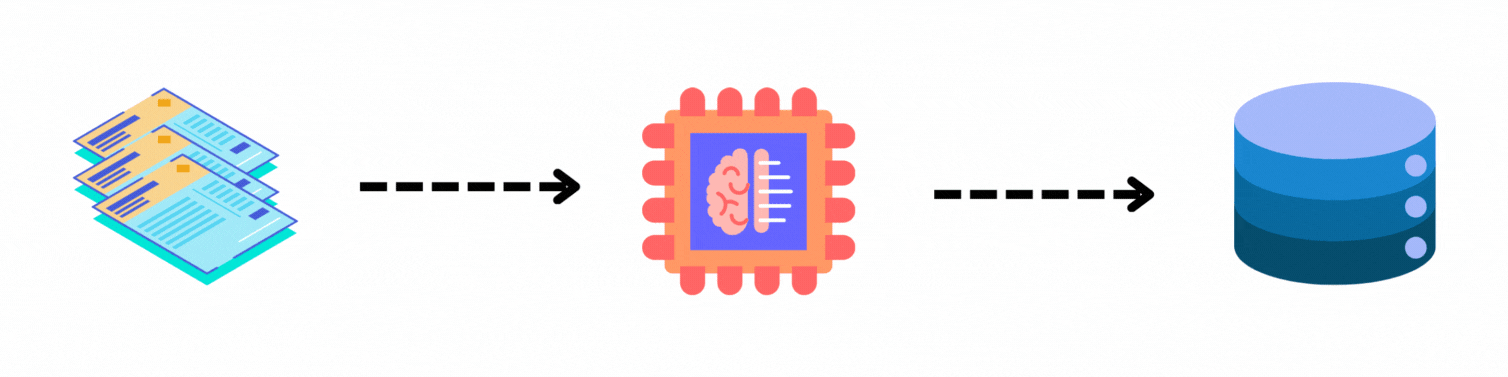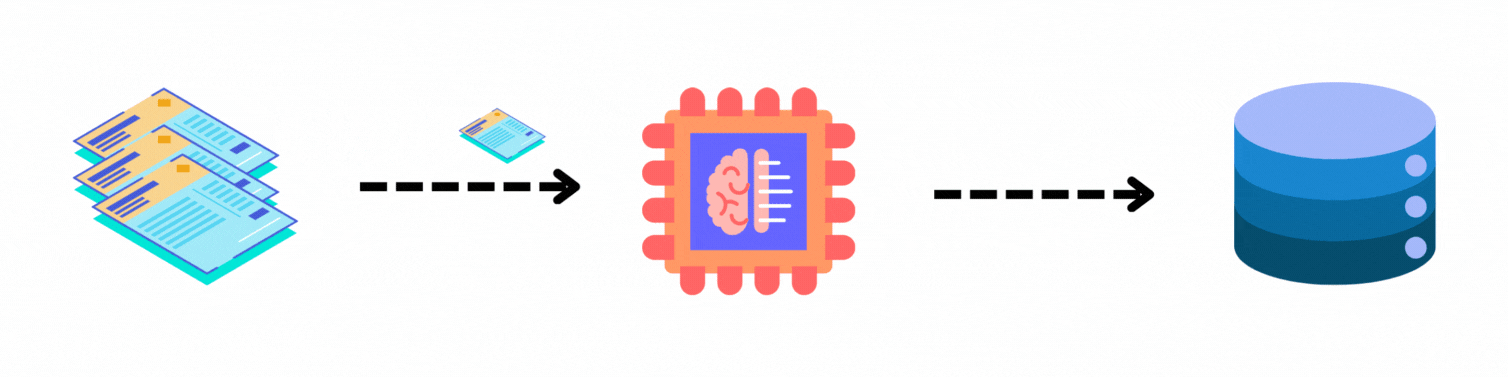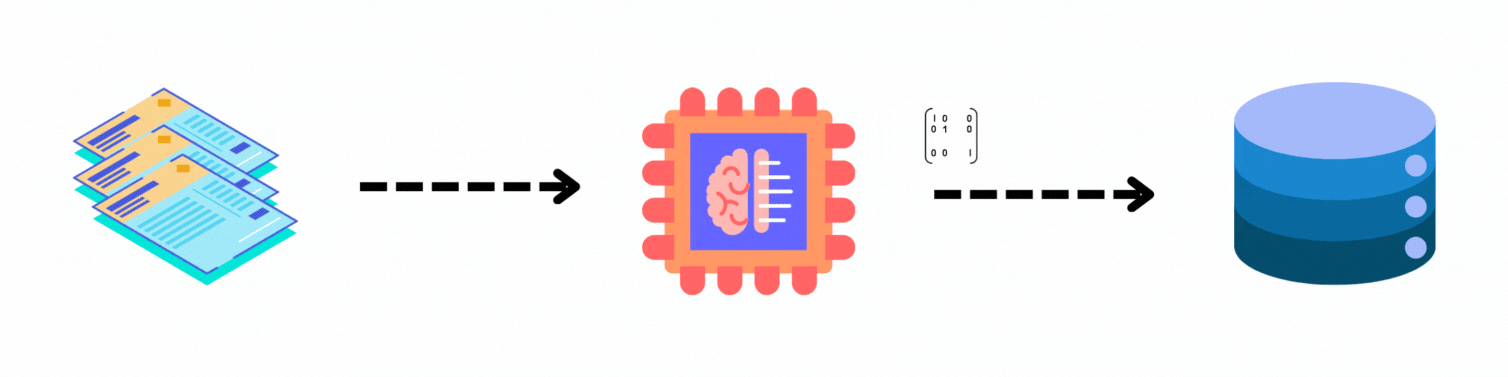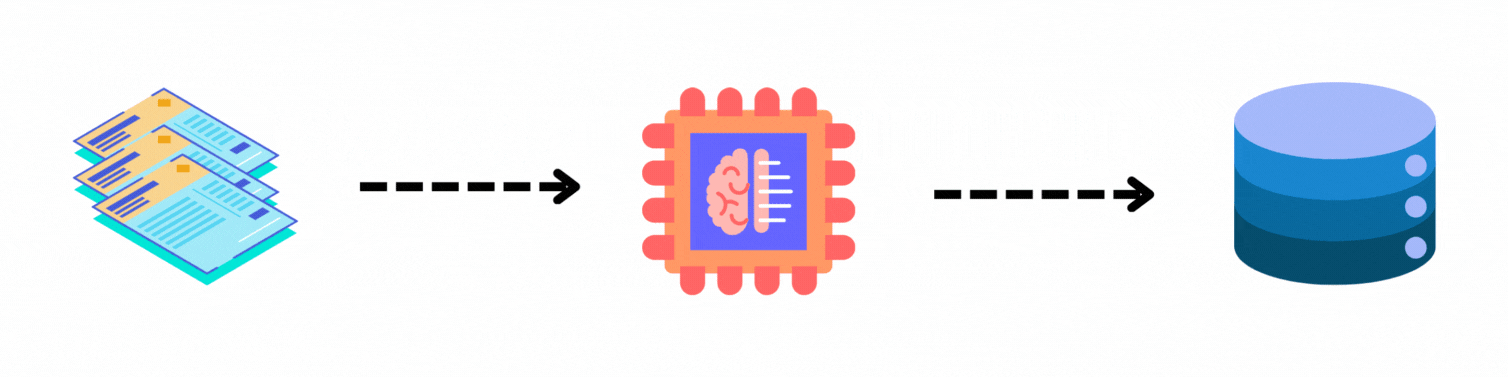
索引
可以将索引用于形成一个数据库,从中可以基于某种启发式方法检索文档或文档块。可以将这一步视为对所有数据进行预处理,为下一步骤做好准备,以便用户查询到来时,能够尽快检索到相关文档。类似于 Google 或 Bing 这样的搜索引擎,当我们搜索某样东西时,因为所有网站都已提前进行预处理和排名,所以几乎能立即得到结果。这种预处理和排名就属于索引的范畴。但是,如何判断两句话在句法和语义上是否相似呢?
数值表示
就像人类理解语言并能从基本词汇构成复杂句子一样,机器也必须理解这些词汇和句子。我们通过数值表示教会机器这一点。这并不是一个新概念,在 LLM 出现很久之前就已经存在,并且在自然语言处理任务中发挥了重要作用。从统计表示方法,如One-hot 编码、词袋模型和Word2Vec,到机器学习表示方法,如向量嵌入,这些都是数值表示演变的不同方式,而大多数已经长期为搜索引擎查询提供支持。文档中建议使用OpenAI的text-embedding-ada-002模型将数据转换为向量,并准备好以便检索。这些向量捕捉了句子的本质:包括语义意义在内的词汇相似性。
from langchain_openai import AzureOpenAIEmbeddings
# A list of articles
articles = [{'title': 'USA Olympic medal count 2024 - Sporting News',
'url': 'https://www.sportingnews.com/us/olympics/news/usa-best-olympic-medal-count-2024-paris-games-final-most-medals-all-time/0809c8a9c89cd4133bb0b281',
'content': 'The nation has ....'}]
# Initialize an empty list to store the embeddings for each article
article_embeddings = []
# Create an instance of AzureOpenAIEmbeddings with a specific model and API version
embedding_model = AzureOpenAIEmbeddings(model="text-embedding-ada-002-01",
api_version="2023-05-15")
for article in articles:
# Generate embeddings for the content of each article using the embed_query method.
# This method converts the article's content into a vector representation.
embeddings = embedding_model.embed_query(article['content'])
article_embeddings.append(embeddings)
这将数据转换为嵌入,这些嵌入存储在一个向量数据库中,以便当用户查询时,可以将查询也转换为向量表示,并以某种方式找到最相关的文档。
在讨论如何准确检索文档之前,需要谈谈分块。尽管 LLM 可以接受较大的输入,但其接受输入和生成输出的能力仍然存在限制,这被称为上下文窗口。因此,当文档变得较大时,需要将其拆分为更小的块,仅将相关的块发送给LLM。这称为分块。关于分块的详细文章,可以参考另外的文章,请关注,讨论如何看待分块以及从头实现的一些方法,帮助读者理解各种方法背后的直觉。
检索
已将所有数据转换为向量,但这些向量代表什么呢?在图形上,每个向量可以绘制在一个n维空间中,所有在语义上相似的向量在空间中存在于邻近位置,即距离和方向几乎相同。因此,当用户进行查询时,将查询转换为向量,并使用某些函数来计算其接近度,以获取邻近的向量。这些函数称为相似性函数。
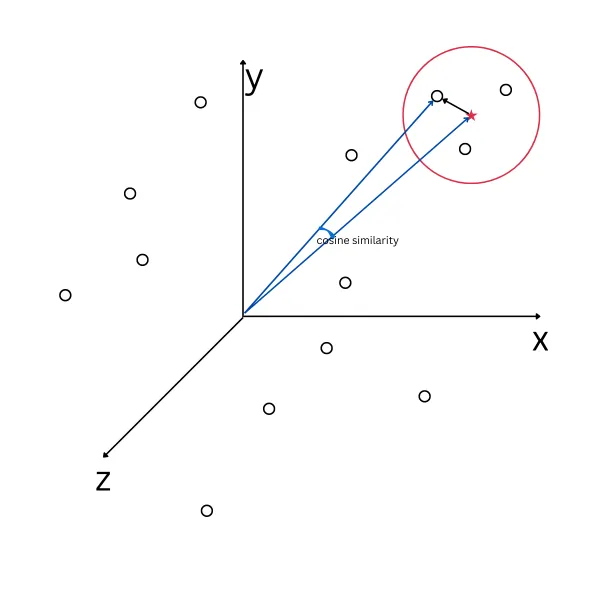
相似性函数
相似性函数是一个实值函数,用于量化两个对象之间的相似程度。虽然没有统一的相似性定义,但通常这些度量在某种意义上是距离度量的逆。余弦相似性是用于实值向量的一种常用相似性度量,在信息检索等领域用来评估向量空间模型中文档的相似性。在机器学习中,常见的核函数,如RBF核,可以视为相似性函数。
任何能够计算两个不同向量相似程度的函数都可以称为相似性函数。执行这些函数有许多策略。一些常见的策略包括:余弦相似性、欧几里得距离、K最近邻和点乘。虽然大多数向量数据库提供开箱即用的实现以使用不同的函数来检索文档,但了解每个函数的实现方式是有益的,因为不同的函数在处理不同类型的数据时表现各异。选择前k个文档(或文档块)作为输入到下一步,即生成。
import numpy as np
# Define a function to calculate cosine similarity between two vectors
def cosine_similarity(vec1, vec2):
# Ensure both vectors are numpy arrays
vec1 = np.array(vec1)
vec2 = np.array(vec2)
# Compute cosine similarity
cos_sim = np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
return cos_sim
query = "Olympic medal count for USA in 2024"
similarities = []
for article, article_embedding in zip(articles, article_embeddings):
similarity = cosine_similarity(query_embedding, article_embedding)
similarities.append({
'title': article['title'],
'url': article['url'],
'similarity': similarity
})
for result in similarities:
print(f"Title: {result['title']}, Similarity: {result['similarity']:.4f}, URL: {result['url']}")
"""
Title: USA Olympic medal count 2024 - Sporting News, Similarity: 0.8754, URL: https://www.sportingnews.com/us/olympics/news/usa-best-olympic-medal-count-2024-paris-games-final-most-medals-all-time/0809c8a9c89cd4133bb0b281
Title: Olympic Games Paris 2024: All U.S. medal winners - full list, Similarity: 0.8779, URL: https://olympics.com/en/news/olympic-games-paris-2024-all-u-s-medal-winners-full-list
Title: Medal Count - Paris 2024 Olympic Medal Table, Similarity: 0.8894, URL: https://olympics.com/en/paris-2024/medals
"""
尽管在这里可以进行多种增强来优化文档查询方式以及获取后的重新排名方式,但这些策略将留待另一篇文章讨论。因此,第三篇文章在相似性方面表现更好,可能会为查询生成更相关的结果,因此选择了前k个(此情况下为1)发送给LLM。
生成
这一步从检索步骤中接收上下文文档,它将查询、上下文和提示结合起来,发送给LLM以生成适当的响应。

超越RAG
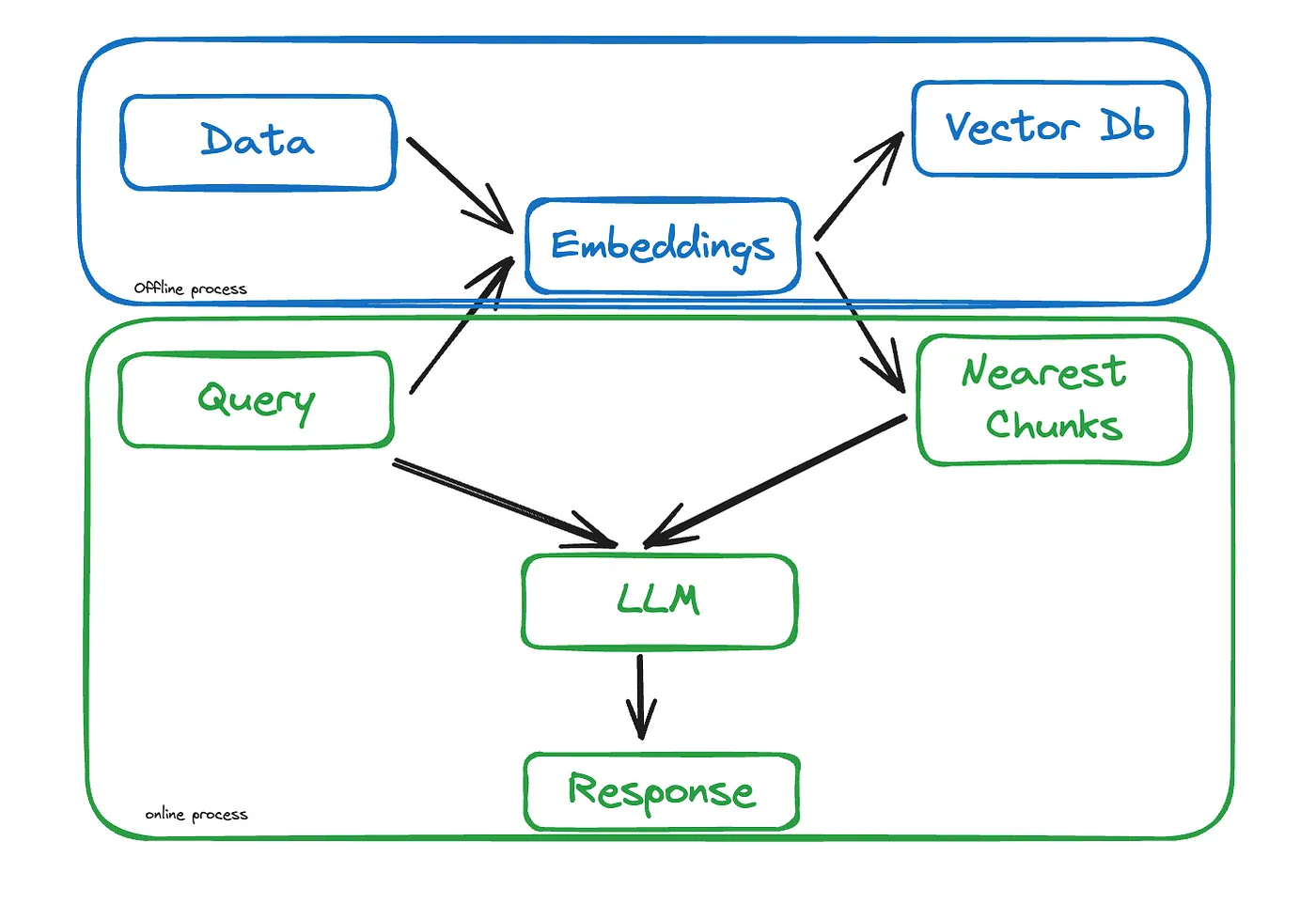
虽然RAG论文为在预训练模型中使用外部知识引入了一种新方法,分为两个步骤,但在实际场景中需要做的远不止这些。下图总结了典型RAG流程中涉及的所有步骤:
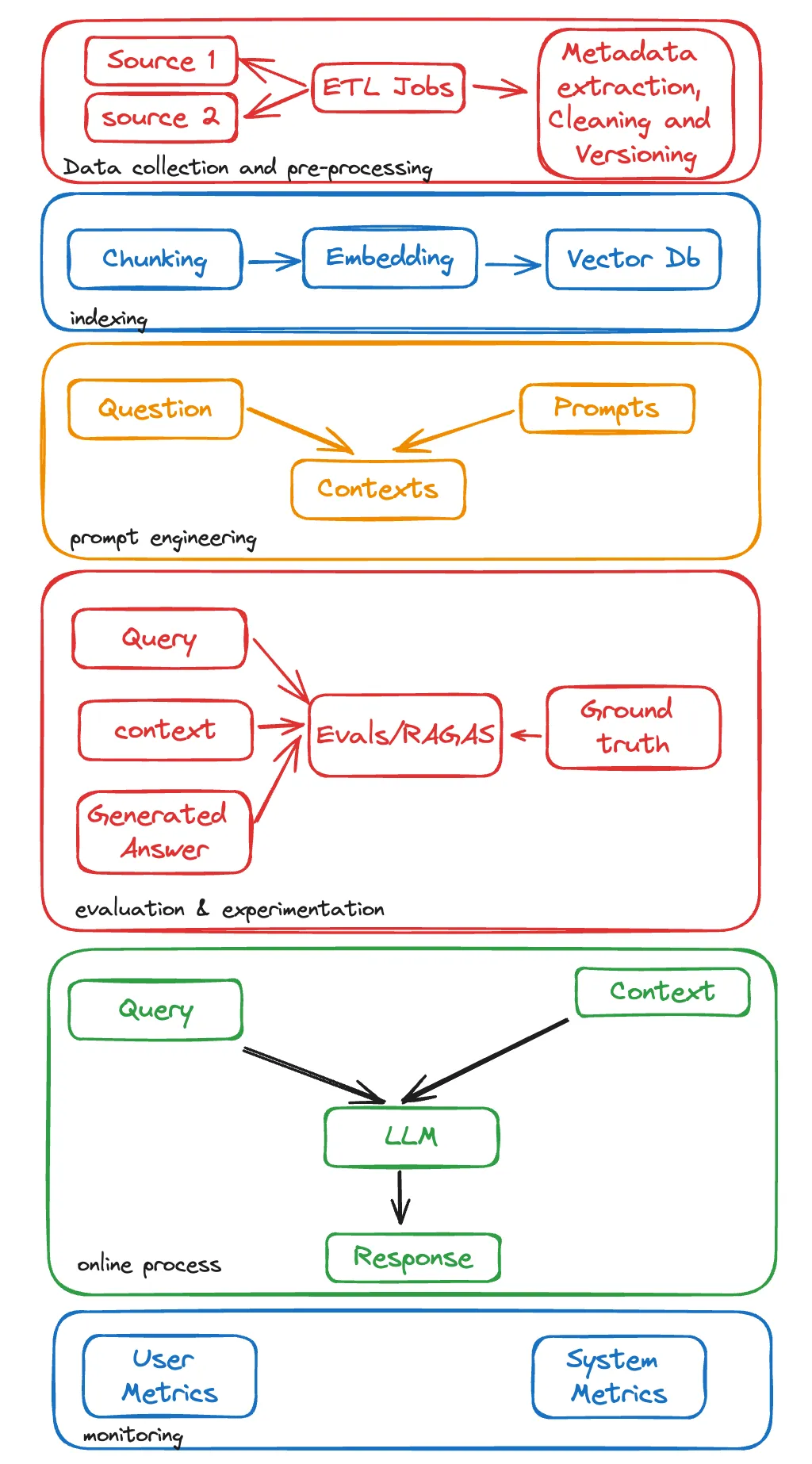
结论
他们已经了解到 LLM 在处理未见过的数据时存在局限性,以及 RAG 如何克服这些问题,大幅减少幻觉并在不重新训练的情况下增强模型的可靠性。了解了简单 RAG 中涉及的步骤,对每个步骤有了认识,并最终看到了一个可投入生产的 RAG 流程可能的样子。


















 1015
1015

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











