








之前做的一款基于语义的app搜索,当时公司希望做一款不仅仅能根据一般文本重合,而且能通过语义上的相关找到更好的推荐app,这里分享一下开发的过程和心得
——————————————————————————————————————————————————————————————————————————
目录:
一、基础特征的选择
二、特征的组合和特征的离散化
三、训练样本的获取
四、排序样本的调整
(三)如何rank
有了候选集后,如何把最优的app放在最前面?那么这时候leaning to rank 就派上用场了。
一、 基础特征的选择
基础特征大致可以分为三大类:
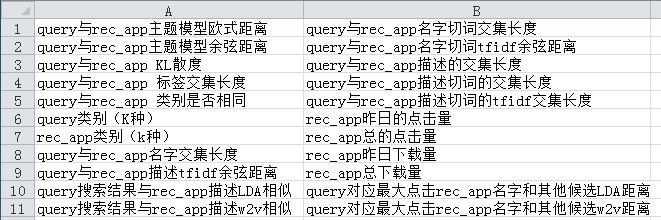
1)文本字面的重合:app文本描述有两处:标题和描述,利用三种分词方式:原子分词,正常分词,ngram组合切分
2)文本语义上的重合:app类别,LDA类别,W2V类别
3)搜索扩展:利用搜索对app标题进行扩展,扩展文本再重复1,2步骤
基础特征如图所示
2、 特征的组合和特征的离散化
这个单开一章吧,感觉还是蛮多东西可以讲的
3、 训练样本的获取
leaning to rank 是个有监督的学习过程,那么训练集如何获取是个很重要的过程。当然可以用人工标注出一批,在没有人工的情况下,怎么办呢。
首先公司原来的app推荐上有一批的点击日志,利用这些日志做出一个点击排名list。
问题来了利用原来非智能推荐的结果来监督学习智能推荐的模型,有效果么?我觉得这个问题是这样的,有两种可能,一种是陷入局部最优,无法达到我们想要的效果,另一种随着用户的使用模型的不断迭代,会不断的优化。
实践中我认为应该是后一种结果。另外我觉得还有许多意外的收获,比如一款游戏中的专业词“之刃”,人工未必知道是哪款游戏app,或者刚刚出现的新app“EXO”不是00后可能根本不知道是什么,又或者交友软件中陌陌和脉脉哪款更应该排在前面,利用点击统计则可以排除这些问题。
4、 排序样本的调整
UBM模型(A User Browsing Model to Predict Search Engine Click Data from Past Observations)
对于搜索的list来说排在后面的往往点击率更低,这个称为眼球模型,就是说人的眼睛一般是从上往下看,越靠上曝光的机会越多,所以点击率越大。
为了改进这个问题,生成更好的训练数据我们可以找list中排位靠后点击反而在前的数据组成pairwise作为训练样本。
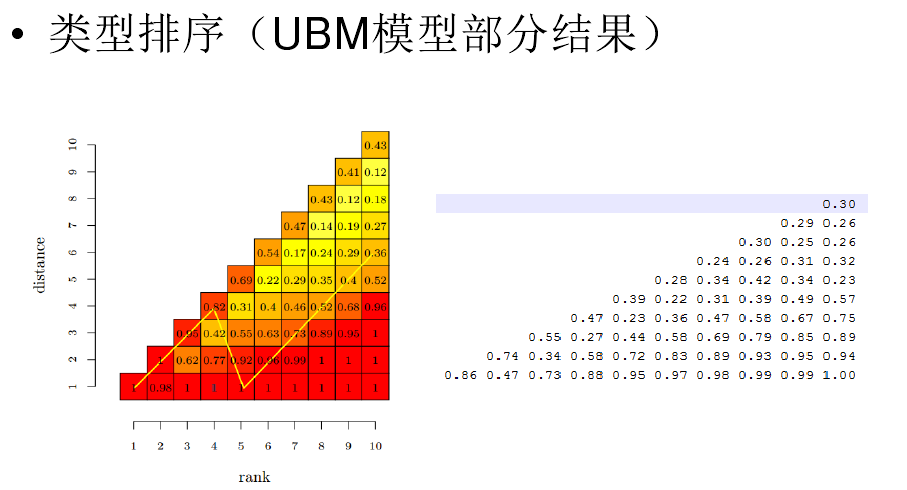
升级的版本就为UBM,UBM在排序的模型中加入了用户点击的考虑,思想是用户点击了某一行,那么他一定看到这一行,于是紧接的行曝光率也增加,如下图所示。我们可以根据整体算出一个用户点击率和位置变化梯度表。当前后两个的点击比率和表中存在差异,我们把他们抽出来作为训练样本
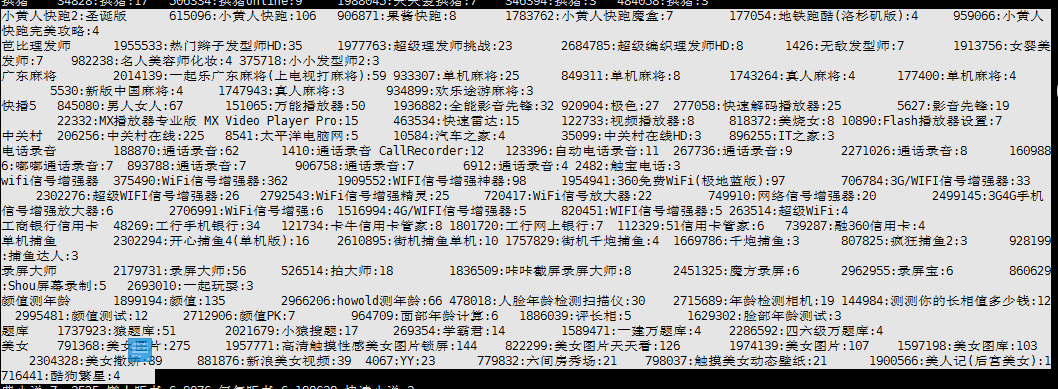
点击排序list如图















 611
611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









