










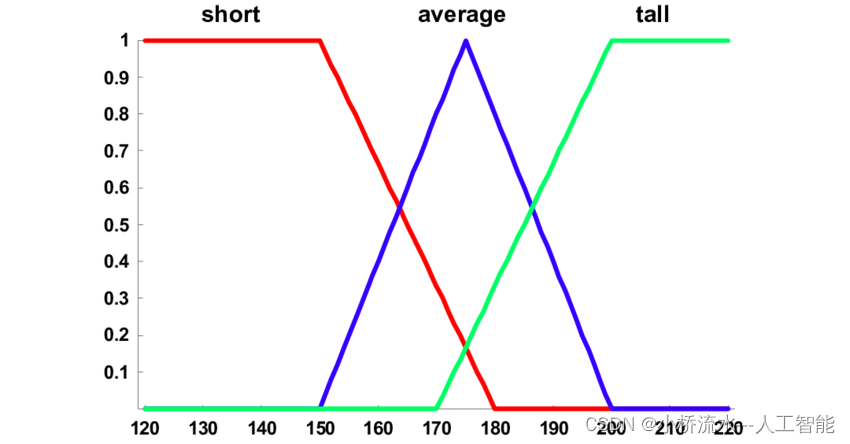
在数据处理中,计算隶属度是一个重要的步骤,尤其是在模糊化处理过程中。隶属度表示一个元素属于某个集合的程度,它是一个介于0和1之间的数值,其中0表示完全不属于,1表示完全属于。在数据噪声抑制和提升数据泛化能力的背景下,对变量数据进行模糊化处理并计算每个变量的隶属度值具有以下作用:
-
噪声抑制:通过模糊化处理,可以平滑数据中的噪声。由于噪声通常是随机的、不规律的,而模糊化处理是根据一定的规则或函数对数据进行转换,因此它能够在一定程度上减少噪声对数据的影响。计算隶属度值能够更精确地定义每个数据点相对于其模糊集合的归属程度,从而进一步减少噪声对数据分析的干扰。
-
特征重要性评估:通过计算每个变量的隶属度值,可以评估每个变量在数据集中的重要程度。隶属度值高的变量可能更具代表性,对数据分析的贡献更大;而隶属度值低的变量可能包含较多的噪声或冗余信息。这有助于在后续的数据处理或模型训练中,对不同的变量进行权重调整或选择,以优化数据分析的效果。
-
提升泛化能力:模糊化处理可以使数据更加平滑和连续,减少数据中的突变或离群点。这有助于模型更好地捕捉数据的整体趋势和规律,而不是过分依赖于某些具体的数值或细节。因此,通过计算隶属度值并进行模糊化处理,可以提升模型的泛化能力,使其在面对新的、未见过的数据时能够更好地进行预测或分类。
-
处理不确定性:在许多实际应用中,数据本身可能存在不确定性或模糊性。通过计算隶属度值,可以更好地处理这种不确定性,提供更丰富、更全面的信息给后续的数据分析或模型训练。















 870
870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









