




概述
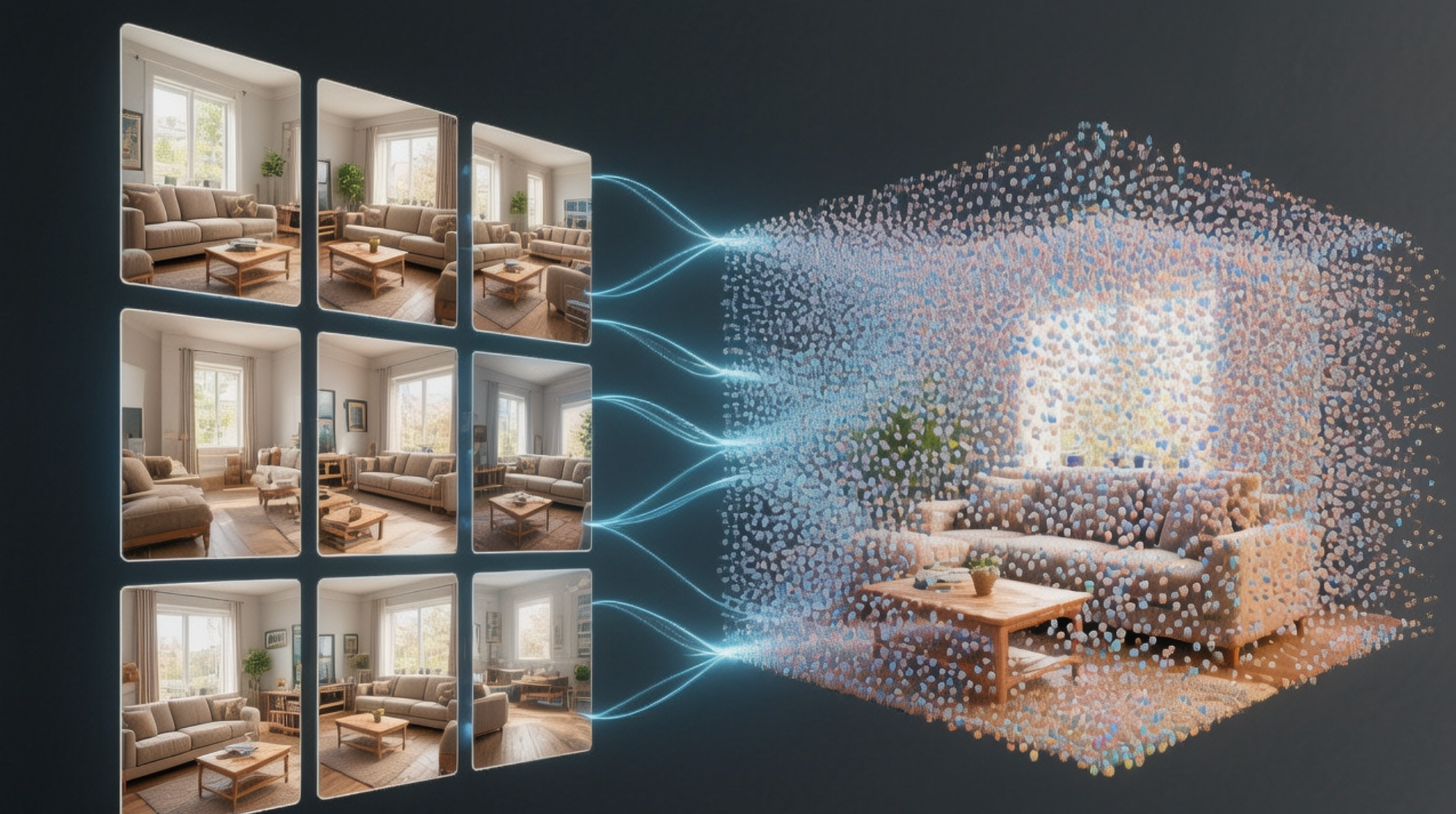
三维建模,指的通过二维图像来构建三维场景模型。
本文主要探讨:如何通过3D高斯泼溅(3D Gaussian Splatting, 3DGS)的方式来建模室内场景。
三维建模技术回顾
三维建模从早期的几何重建到如今的神经场表示(Neural Fields),技术演进可以大致分为以下几个阶段:
1. 几何时代(1990–2015)
核心思想:从多视图图像的几何关系中重建三维点云或网格模型。
代表性工作:
- Structure from Motion(SfM):从多张图像的几何关系中恢复相机位姿和稀疏三维点。
- Multi-View Stereo (MVS):在已知相机位姿下,通过像素匹配重建稠密点云或深度图。
2. 深度学习时代(2016–2020)
核心思想:利用神经网络直接学习从图像到三维形状的映射,突破传统几何算法的局限。
代表性工作:
- 3D-R2N2:用卷积网络从多视图图像预测体素化的三维形状。
- PointNet:直接在点云上进行特征学习,实现端到端的3D理解。
- AtlasNet:通过神经网络学习二维参数映射生成三维网格。
3. 神经隐式表示时代(2020–2022)
核心思想:用连续神经函数而非离散网格来表示三维空间,实现高保真的体积渲染。
代表性工作:
- NeRF:用MLP表示体积密度与颜色,通过体渲染生成任意视角的图像。
- DeepSDF:以隐式函数形式学习物体表面形状的有符号距离场。
- NeuS:结合NeRF与隐式表面渲染,实现高精度几何表面恢复。
4. 实时神经渲染时代(2022–2024)
核心思想:通过新型编码与显式点云表示,实现神经场的实时渲染与可编辑性。
代表性工作:
- Instant-NGP:采用多分辨率哈希编码,实现NeRF的秒级训练与实时渲染。
- 3D Gaussian Splatting:以高斯点云显式表示场景,实现高保真、实时的3D渲染。
- Dynamic Gaussian Splatting:将高斯点拓展到动态场景,支持时间变化建模。
5. 3D生成时代(2024–2025)
核心思想:利用大模型和多模态学习,实现从图像、文本到三维结构的端到端推理与生成。
代表性工作:
- VGGT:Vision Generalist Geometry Transformer,统一SfM、MVS与NeRF任务。
- LRM / Wonder3D:大规模预训练模型,可从单张图像生成完整三维结构。
- DreamFusion / Magic3D:基于扩散模型的文本到3D生成,实现可控三维内容创作。

高斯泼溅基本原理
本文选择高斯泼溅有以下几点原因:
- 一些传统的建模软件,如CC、RealityCapture采用的是主要是几何时代的算法,模型的精细度比较有限,3DGS作为近现代的算法,渲染效果能够做得更加逼真。
- 大模型相关的算法可拓展性较强,但需要的算力资源更高,且基本优先支持Cuda生态。
- 3DGS已有较好地生态支撑,支持Mac系统进行训练,且计算所需资源不高。
3DGS的核心思想是:用一堆带颜色、透明度和方向的高斯椭球体,在三维空间中“拼”出现实世界:
- 每个椭球体代表一个小“体积单元”;
- 它的颜色表示该位置的光线或表面颜色;
- 它的大小与方向(长轴、短轴)表示空间密度的分布方向;
- 它的透明度表示这个区域的遮挡程度。
当这些椭球体在三维空间中恰好排列好,从任意角度看去,它们的投影叠加在一起,就能看到与真实场景几乎一模一样的图像。

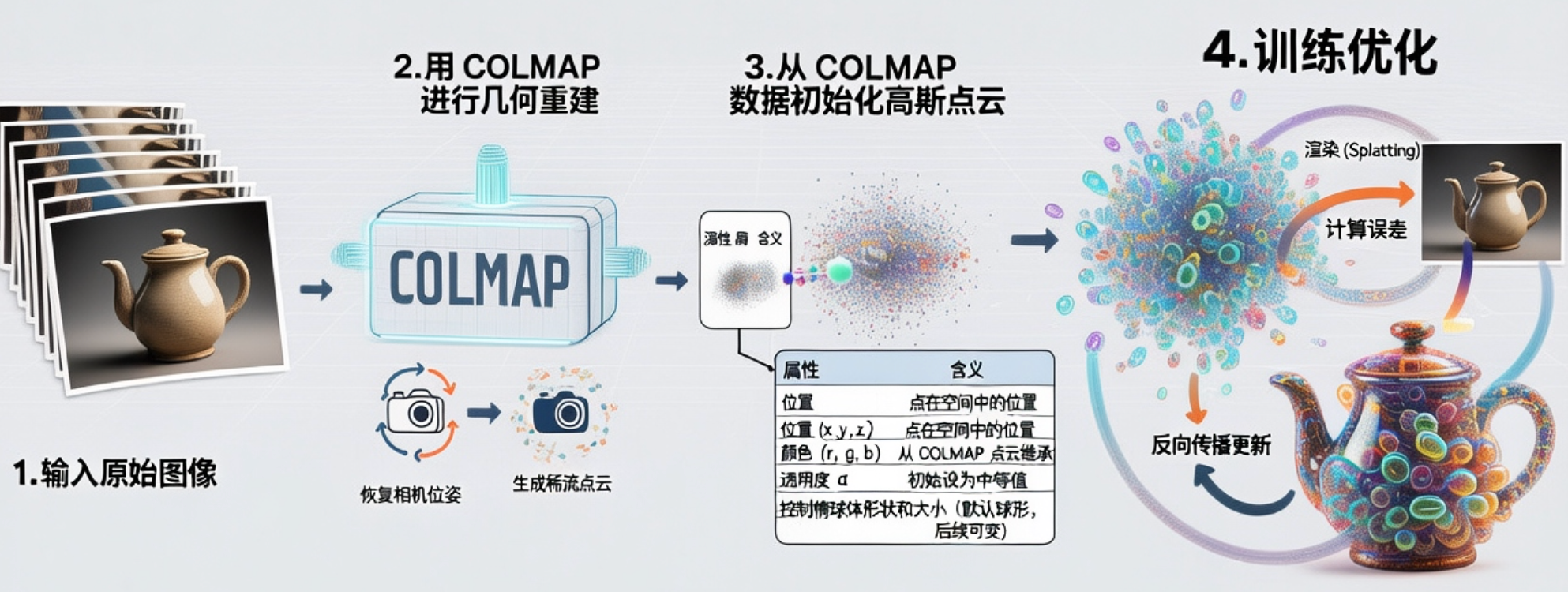
3DGS 的基本步骤如下:
-
1.输入原始图像
先准备一组从不同角度拍摄的照片,这些照片是场景的“视觉依据”,后续训练作为标签。 -
2.用 COLMAP 进行几何重建
3DGS 本身不会估计相机位姿,因此需要先用 COLMAP 对这些图像做结构重建(SfM + MVS):- 计算特征匹配:找到不同照片中的相同点。
- 恢复相机位姿:每张照片的拍摄位置和方向。
- 生成稀疏点云:场景中关键点的三维坐标。
-
3.从 COLMAP 数据初始化高斯点云
3DGS 会读取 COLMAP 的输出,并将稀疏点转化为一堆初始高斯椭球体,每个椭球体包含以下属性:属性 含义 位置 (x, y, z) 点在空间中的位置 颜色 (r, g, b) 从 COLMAP 点云继承 透明度 α 初始设为中等值 协方差矩阵 Σ 控制椭球体形状和大小(默认球形,后续可变) -
4.训练优化
训练的目标是:让这些椭球体从各个视角渲染出来的图像,与真实照片尽可能一致。
具体过程如下:- 从每个训练图像视角出发,用相机参数渲染场景。
- 将每个高斯椭球体投影到图像平面(称为 splatting)。
- 计算渲染图与真实照片的误差(L2或PSNR)。
- 反向传播,更新每个椭球的位置、颜色、大小、方向和不透明度
这个过程让所有椭球体的集合逐渐“拟合”出真实世界。
最后训练完成后,就可以得到支持旋转浏览的高斯点云(成千上万个彩色椭球体)。
实践
下面来进行具体实践,在Mac系统上用3DGS来建模一个室内场景。
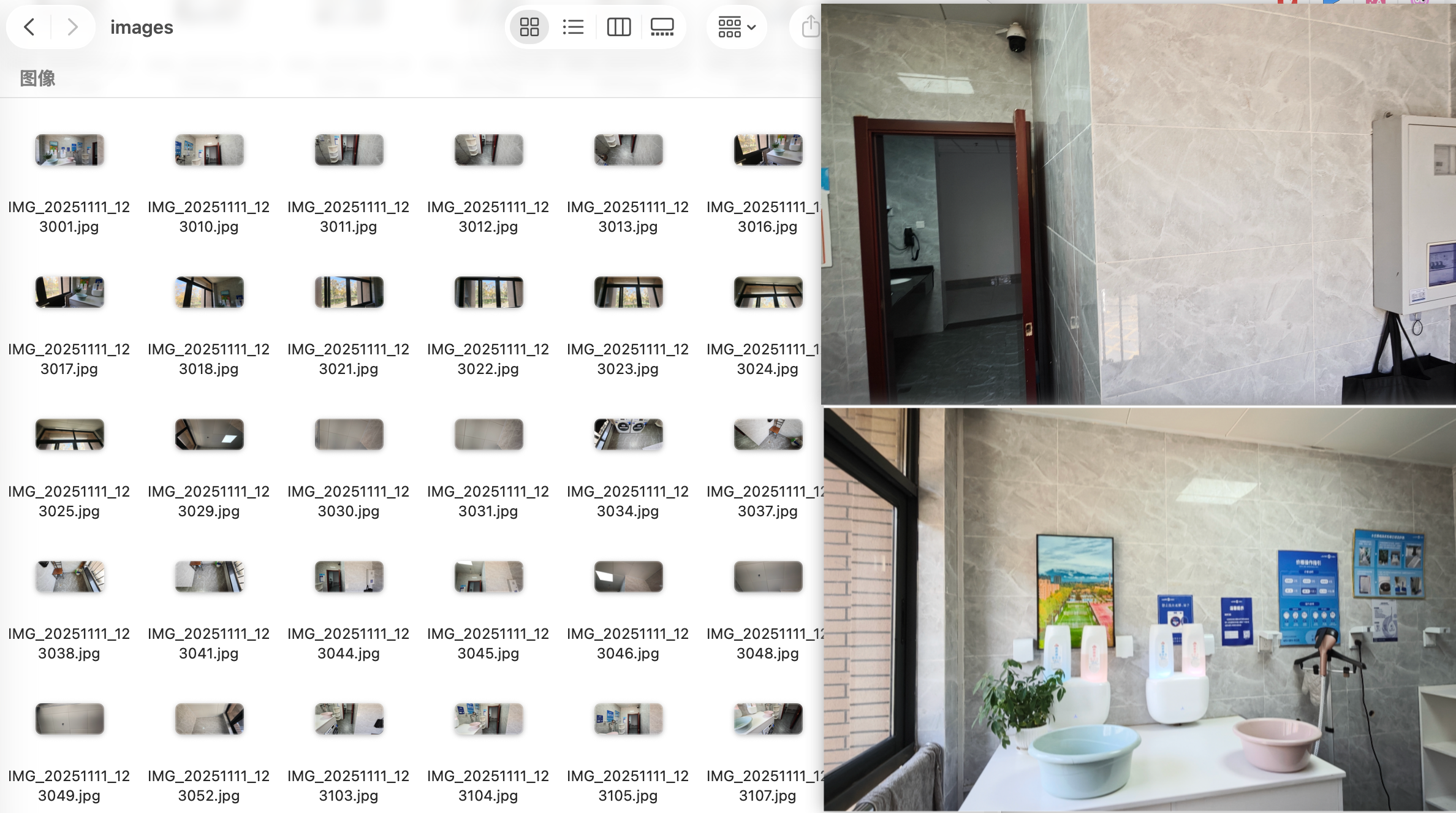
1. 采集图像
室内场景我选择了一间公用洗衣房,用手机广角镜头拍摄了62张图片。
2. 计算结构信息
在得到初始图像后,需要先通过colmap去计算相机参数、位姿、三维点云等结构化信息,以便3DGS进行初始化。
这里我采用colmap-gradio这个仓库[1]进行处理,它提供了可视化的界面,能够方便调节参数。
根据仓库描述,首先需要安装以下依赖:
brew install colmap
brew install imagemagick
然后根据requirements.txt安装py环境,运行:
python colmap_gradio.py
运行后,会得到可访问的本机url:
浏览器访问,输入项目路径,这里注意:它会自动读取路径下的images文件夹,因此,不要指定图像路径,而要指定其上一级的路径。
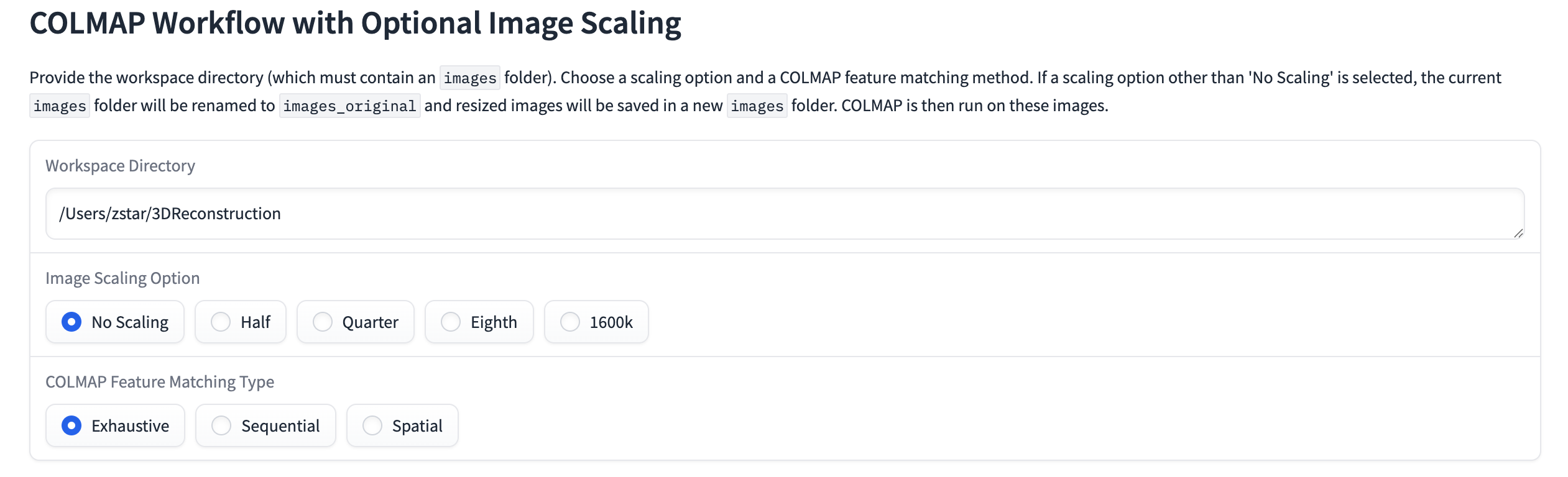
下面有几个参数选项,含义如下:
| 选项 | 说明 | 适用场景 |
|---|---|---|
| No Scaling | 不缩放,使用原始分辨率 | 精度最高,但最慢、占内存最大 |
| Half (1/2) | 图像尺寸缩小一半(宽高各除以2) | 常用平衡方案,速度快、效果仍不错 |
| Quarter (1/4) | 图像缩小为原来的 1/4 尺寸 | 快速预览或低端设备用 |
| Eighth (1/8) | 图像非常小,只用于测试或大规模批量重建 | |
| 1600k | 限制图像的最大像素数(约1600×1600),常用于统一分辨率 | 通常是“自动缩放不超过1600px” 的意思 |
匹配模式:
| 模式 | 工作方式 | 适用场景 |
|---|---|---|
| Exhaustive(穷尽匹配) | 每张图片与所有其他图片两两匹配 | 最精确,但非常慢。适合图片较少(<300)的情况 |
| Sequential(顺序匹配) | 假设图片按时间或序列顺序拍摄,只匹配相邻几张 | 适合视频帧、顺序拍摄的场景(如无人机航拍路径) |
| Spatial(空间匹配) | 利用 GPS 或初步估计的位姿,只匹配相邻空间位置的图片 | 适合带有定位信息的航拍或移动摄影数据集 |
运行之后,大概几分钟就能得到结果,生成以下文件:
| 文件名 | 内容 | 说明 |
|---|---|---|
| project.ini | 当前 COLMAP 工程的配置文件 | 记录数据路径、版本等信息 |
| cameras.bin | 相机模型与内参 | 比如焦距、主点、畸变参数 |
| images.bin | 每张图像的姿态(外参)与对应特征点 | 相机位置、方向、对应的点云索引 |
| points3D.bin | 三维点云数据(稀疏) | 每个三维点的坐标、颜色、可见图像 |
| frames.bin | 如果是视频序列,这里存帧索引和对应图像信息 | 通常在 Sequential 模式下才有 |
| rigs.bin | 多相机 Rig 的同步信息 | 只有多镜头系统(双目、阵列相机)才会用到 |
3. 3DGS训练
下面就可以进入到 3DGS 训练,使用Brush[2]这个仓库,它提供了Mac版本的安装包。
打开软件,可以设置一些参数,实测默认参数就能有比较好的效果。
一般来说,主要可调节训练的步数(steps),默认30000步,如果训练得不好,可以适当调大。
另外可以适当调节一下保存间隔,默认它会每隔5000步进行一次保存。
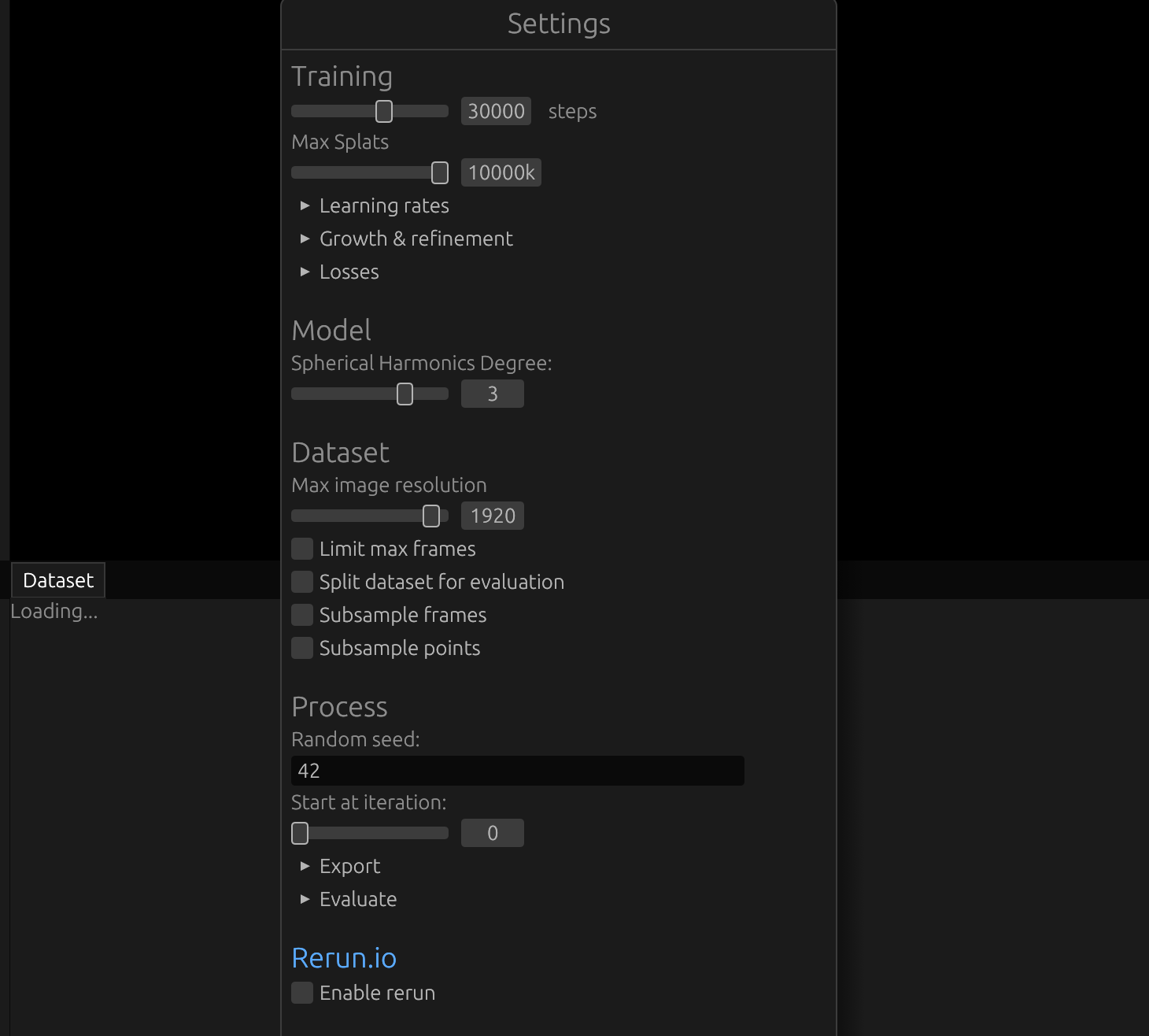
导入文件路径,和上一步类似,选择的是项目路径。
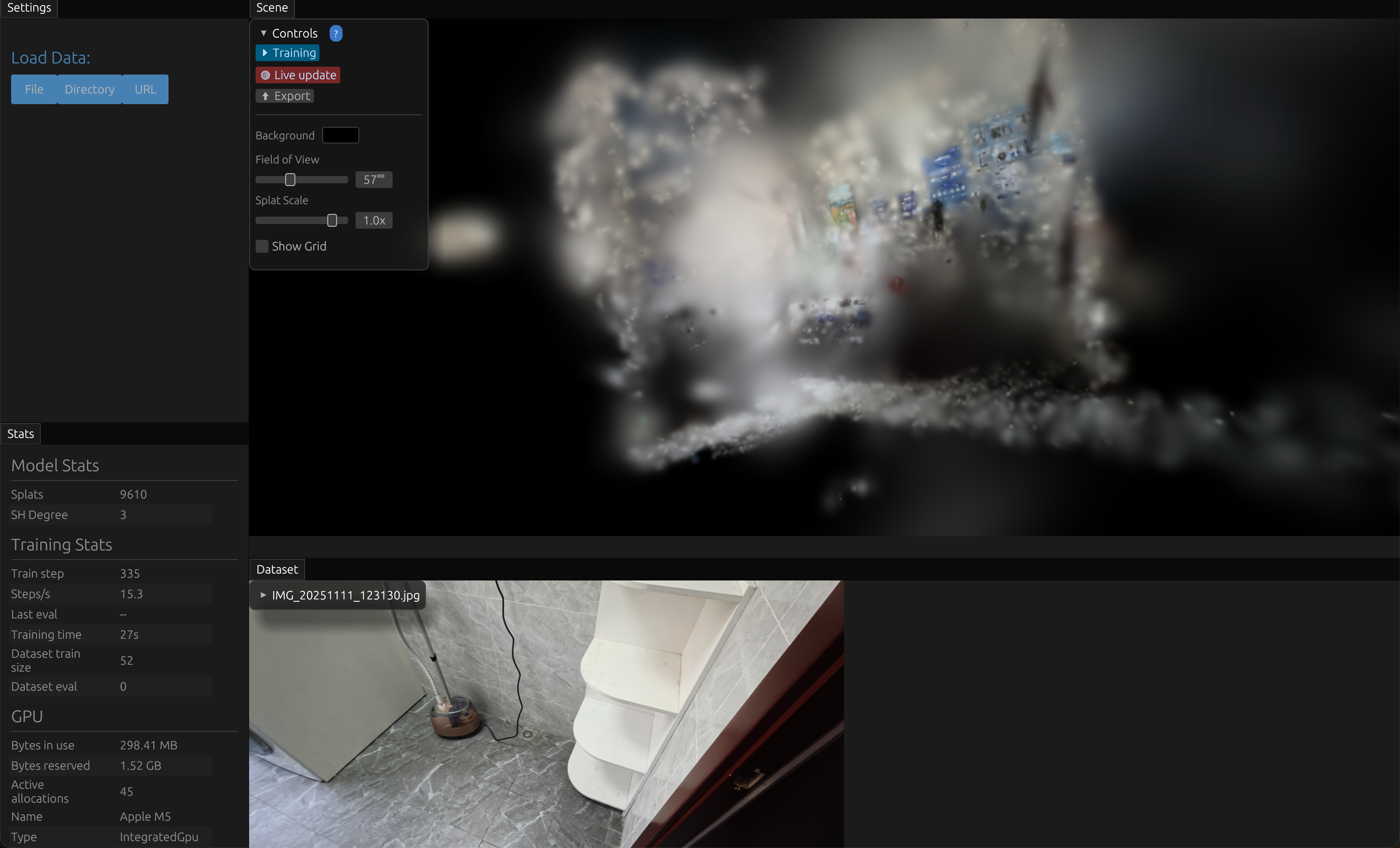
开始运行后,训练结果是可以被实时预览到的,起初建模场景非常模糊,通过训练,不断变清晰。

经过大约一小时的训练后,得到的最终结果如下:

从结果来看,有一个明显的发现是:如果三维视角和拍摄的照片正好重合,此时效果很好,但如果稍微偏离,效果存在明显下降。
此现象表明,要尽可能减少相邻照片的移动间距,即增加照片的重合率,我所拍摄的重叠率不高,并且有些照片存在一定的模糊抖动。
下篇文章,将尝试采用视频采样的方式,看是否能优化结果,以及探究如何对生成的.ply文件进行后处理。
参考
[1] https://github.com/jonstephens85/colmap-gradio
[2] https://github.com/ArthurBrussee/brush



















 491
491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











