







 超级会员免费看
超级会员免费看
文章目录
前言
在大模型时代,RAG(检索增强生成)已成为企业将通用语言模型与私有知识结合、实现可控、可信智能问答的核心技术路径。然而,从“能用”到“好用”,RAG 的落地远非简单拼接检索与生成模块——它需要在检索精度、知识组织、生成质量与工程性能之间取得精细平衡。
本文系统梳理了 RAG 优化的关键环节,围绕“检索器—索引与分块—生成器”三大核心模块,结合工业界成熟实践与前沿探索,深入剖析如何解决“找不准、答不好、跑不快”等典型问题。无论是刚入门的技术团队,还是正在攻坚高阶场景的企业工程师,都能从中获得可复用的方法论与实操建议。
我们不仅关注技术细节,更聚焦真实业务场景下的落地挑战:如何降低幻觉风险?如何提升高并发下的响应效率?如何科学评估优化效果?文章最后以高频问答形式,直击企业实施 RAG 时最关心的痛点,并给出经过验证的解决方案。
愿这份指南,助你在 RAG 的工程化之路上走得更稳、更远。
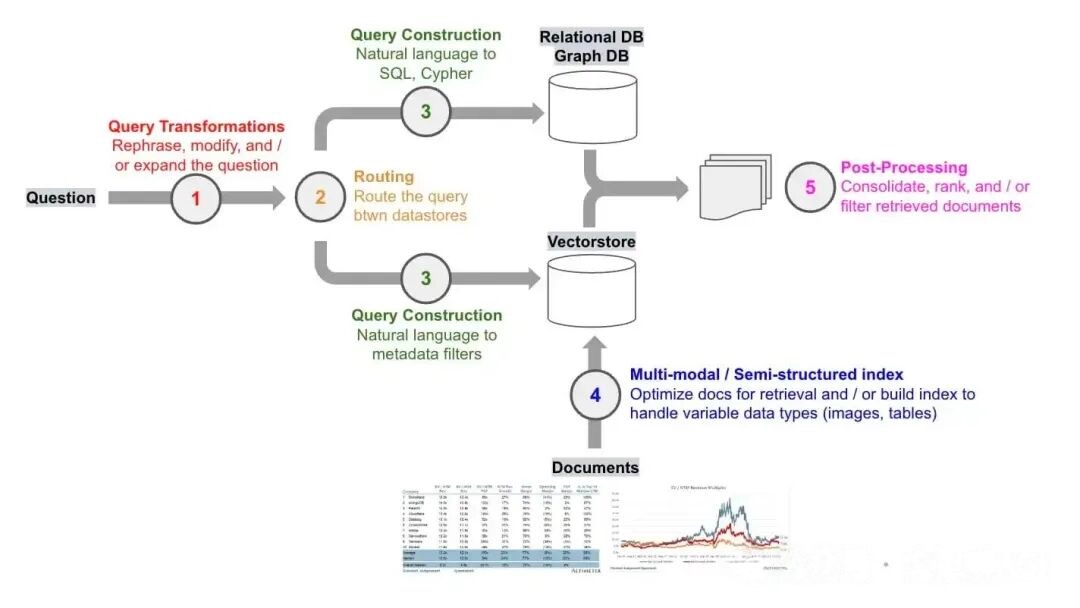
一、明确方向:RAG 优化的关键目标解析
RAG(检索增强生成)的核心流程很简单:用户提问→检索知识库→拼接 Prompt→LLM 生成。但落地时总会遇到三类问题:检索不准、检索不全、生成不稳。
所以企业落地 RAG 优化的本质,就是围绕 “检索器→索引与分块→生成器” 三个核心环节,打造性能闭环,既要 “找得到”,也要 “答得好”。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 533
533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











