







文章目录
一 摘要
将点云分为地面和非地面测量是从机载 LiDAR(光探测和测距)数据生成数字地形模型 (DTM) 的重要步骤。但是,大多数过滤算法需要仔细设置许多复杂的参数才能实现高精度。在本文中,提出了一种新的过滤方法,它只需要几个易于设置的整数和布尔参数。在所提出的方法中,将 LiDAR 点云倒置,然后使用刚性布料覆盖倒置的表面。通过分析布料节点和相应的 LiDAR 点之间的交互,可以确定布料节点的位置,从而生成地表的近似值。最后,通过比较原始 LiDAR 点和生成的表面,可以从 LiDAR 点云中提取地面点。使用 ISPRS(国际摄影测量与遥感协会)工作组 III/3 提供的基准数据集来验证所提出的滤波方法,实验结果产生的平均总误差为 4.58%,这与大多数最先进的滤波算法相当。所提出的易于使用的滤波方法可以帮助没有太多经验的用户更轻松地在自己的应用中使用 LiDAR 数据和相关技术。
二 资源
文章:An Easy-to-Use Airborne LiDAR Data Filtering Method Based on Cloth Simulation
年份:2016
三 内容
1)摘要
将点云分为地面和非地面测量是从机载 LiDAR(光探测和测距)数据生成数字地形模型 (DTM) 的重要步骤。但是,大多数过滤算法需要仔细设置许多复杂的参数才能实现高精度。在本文中,提出了一种新的过滤方法,它只需要几个易于设置的整数和布尔参数。在所提出的方法中,将 LiDAR 点云倒置,然后使用刚性布料覆盖倒置的表面。通过分析布料节点和相应的 LiDAR 点之间的交互,可以确定布料节点的位置,从而生成地表的近似值。最后,通过比较原始 LiDAR 点和生成的表面,可以从 LiDAR 点云中提取地面点。使用 ISPRS(国际摄影测量与遥感协会)工作组 III/3 提供的基准数据集来验证所提出的滤波方法,实验结果产生的平均总误差为 4.58%,这与大多数最先进的滤波算法相当。所提出的易于使用的滤波方法可以帮助没有太多经验的用户更轻松地在自己的应用中使用 LiDAR 数据和相关技术。
2)创新点
①所提出的算法中使用的参数很少,并且这些参数易于理解和设置;
②所提出的算法可以应用于各种景观,而无需确定复杂的过滤参数;
③此方法适用于原始 LiDAR 数据。
3)算法结构
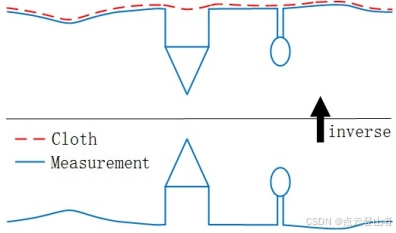
文中方法基于对简单物理过程的模拟。想象一下,一块布放在地形上方,然后这块布由于重力而掉落。假设布料足够柔软,可以粘附在表面上,则布料的最终形状是 DSM(数字表面模型)。但是,如果首先将地形倒置,并且布料定义为刚性,则布料的最终形状就是 DTM。为了模拟这个物理过程,我们采用了一种称为布料模拟的技术。基于这项技术,作者开发了布料模拟过滤 (CSF) 算法,用于从 LiDAR 点中提取地面点。下图说明了所提出的算法的概述。首先,将原始点云倒置,然后一块布料从上方落到倒置的表面上。通过分析布料节点与相应的 LiDAR 点之间的相互作用,可以确定布料的最终形状,并以此为基础,将原始点分为地面和非地面部分
A 基础理论
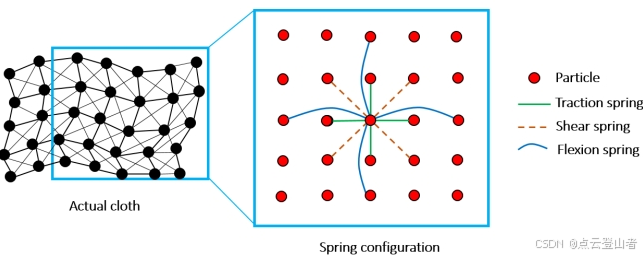
布料模拟是 3D 计算机图形学的一个术语。它也称为布料建模,用于在计算机程序中模拟布料。在布料模拟过程中,布料可以建模为由具有质量和互连的粒子组成的网格,称为质量弹簧模型。上图显示了网格模型的结构。网格节点上的粒子没有大小,但被分配了恒定质量。粒子在 3D 空间中的位置决定了布料的位置和形状。在这个模型中,粒子之间的互连被建模为“虚拟弹簧”,它连接两个粒子并遵循胡克定律。为了充分描述布料的特性,定义了三种类型的弹簧:剪切弹簧、牵引弹簧和弯曲弹簧。
为了模拟布料在特定时间的形状,将计算 3D 空间中所有粒子的位置。粒子的位置和速度由作用在其上的力决定。根据牛顿第二定律,位置和力之间的关系由方程确定:
![]()
其中 X 表示粒子在时间 t 的位置;Fext(X, t) 代表外力,它由粒子在其运动方向上遇到某些物体时由障碍物产生的重力和碰撞力组成;Fint(X, t) 代表粒子在位置 X 和时间 t 处的内力(由互连产生)。由于内力和外力都随时间 t 而变化,因此在布料模拟的传统实现中,方程通常通过数值积分(例如欧拉法)来解决。
B 点云布料滤波
在将布料模拟应用于 LiDAR 点过滤时,进行了大量修改,以使该算法能够适应点云过滤。首先,粒子的运动被约束在垂直方向上,因此可以通过比较粒子和地形的高度值来实现碰撞检测(例如,当粒子的位置低于或等于地形时,粒子与地形相交)。其次,当粒子到达“正确位置”,即地面时,该粒子被设置为不可移动。第三,将力分为两个离散的步骤,以实现简单性和相对较高的性能。通常,粒子的位置由外力和内力的合力决定。在这个修改后的布料模拟中,作者首先计算粒子从重力作用下的位移(粒子在到达地面时被设置为不可移动,因此可以省略碰撞力),然后根据内力修改这个粒子的位置。此过程如下图所示:
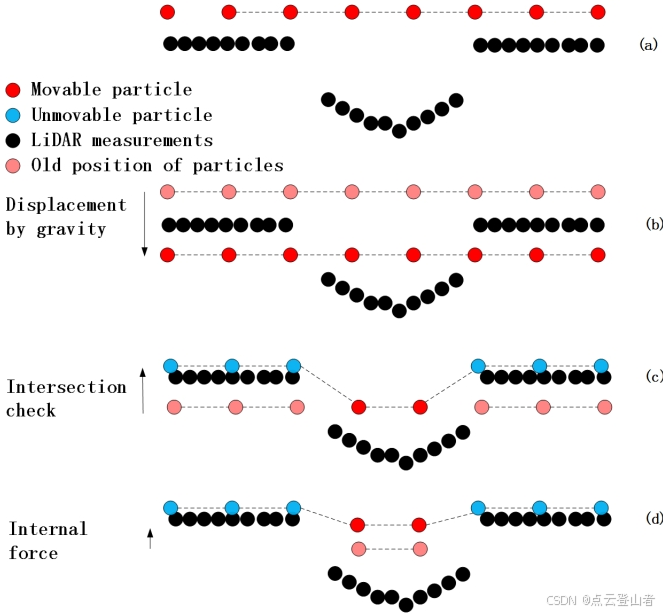
其中,(a) 初始状态。在倒置的 LiDAR 测量值上方放置一块布;(b) 每个粒子的位移是在重力影响下计算的。因此,一些颗粒可能会出现在地面测量下;(c) 交叉路口检查。对于在地下的,他们在地面上移动并被设置为不可移动;(d) 考虑内力。可移动粒子根据相邻粒子产生的力进行移动。
C 实现步骤
如上所述,作用在粒子上的力被认为是两个离散的步骤。首先,只计算每个粒子在重力作用下的位移,即求解内力等于零的方程。那么,这个方程的显式积分形式是:
![]()
其中 m 是粒子的质量(通常,m 设置为 1),∆t 是时间步长。这个方程式很容易求解。给定时间步长和初始位置,可以直接计算当前位置,因为 G 是一个常数。
为了约束粒子在倒置表面的空隙区域中的位移,作者考虑了粒子在重力作用下移动后的第二步中的内力。由于内力的作用,粒子将尝试留在网格中并返回到初始位置。我们不是逐个考虑每个粒子的邻居,而是简单地遍历所有弹簧。对于每个弹簧,比较形成这个弹簧的两个粒子之间的高度差。因此,二维 (2-D) 问题被抽象为一维 (1-D) 问题,如下图所示。
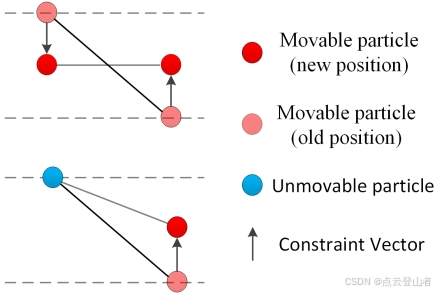
由于限制了粒子的移动方向,因此两个具有不同高度值的粒子将尝试移动到同一水平平面(布料网格水平放置在开始时)。如果两个连接的粒子都是可移动的,则向相反方向移动它们相同的量。如果其中一个是不可移动的,那么另一个将被移动。否则,如果这两个粒子具有相同的高度值,则不会移动它们。因此,每个粒子的位移(矢量)可以通过以下公式计算:
![]()
其中![]() 表示粒子的位移矢量;当粒子可移动时,b 等于 1,否则等于 0。
表示粒子的位移矢量;当粒子可移动时,b 等于 1,否则等于 0。![]() 是当前准备移动的粒子的位置。
是当前准备移动的粒子的位置。![]() 是与 p0 连接的相邻粒子的位置;
是与 p0 连接的相邻粒子的位置;![]() 是指向垂直方向的归一化向量,
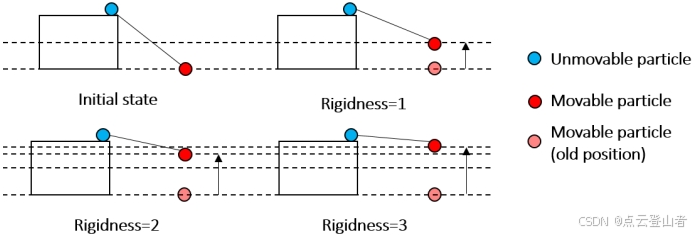
是指向垂直方向的归一化向量, ![]() = (0, 0, 1)T 。这个移动过程可以重复;作者设置了一个参数 rigidness (RI) 来表示重复次数。此参数化过程如下图所示。如果 RI 设置为 1,则可移动粒子仅移动一次,位移是两个粒子之间垂直距离 (VD) 的一半。如果 RI 设置为 2,则可移动粒子将移动两次,总位移为 3/4VD。最后,如果 RI 设置为 3,则可移动粒子将移动 3 次,总位移为 7/8VD。值 3 足以产生非常坚硬的布料。因此,作者将刚性限制为 1、2 和 3 的值。刚度越大,布料的行为就越严格。
= (0, 0, 1)T 。这个移动过程可以重复;作者设置了一个参数 rigidness (RI) 来表示重复次数。此参数化过程如下图所示。如果 RI 设置为 1,则可移动粒子仅移动一次,位移是两个粒子之间垂直距离 (VD) 的一半。如果 RI 设置为 2,则可移动粒子将移动两次,总位移为 3/4VD。最后,如果 RI 设置为 3,则可移动粒子将移动 3 次,总位移为 7/8VD。值 3 足以产生非常坚硬的布料。因此,作者将刚性限制为 1、2 和 3 的值。刚度越大,布料的行为就越严格。
CSF 的主要实现步骤说明如下。首先,将布料粒子和 LiDAR 点投影到同一个水平面上,然后为这个 2D 平面中的每个布料粒子找到最近的 LiDAR 点(称为对应点 CP)。定义交集高度值 (IHV) 以记录 CP 的高度值(投影前)。该值表示粒子可以到达的最低位置(即,如果粒子到达该值定义的最低位置,它就不能再向前移动)。在每次迭代期间,将粒子的当前高度值 (CHV) 与 IHV 进行比较;如果 CHV 等于或低于 IHV,则将粒子移回 IHV 的位置并使粒子不可移动。
仿真后获得真实地形的近似值,然后计算原始 LiDAR 点与仿真粒子之间的距离。距离小于阈值 hcc 的 LiDAR 点被归类为 BE(裸露地表),而其余点被归类为 OBJ(对象)。
(1)使用某些第三方软件(例如 cloudcompare)自动或手动处理异常值。
(2)反转原来的 LiDAR 点云。
(3)启动布料网格。根据用户定义的网格分辨率 (GR) 确定颗粒数量。布料的初始位置通常设置在最高点上方。
(4)将所有 LiDAR 点和网格粒子投影到一个水平面上,并找到该平面上每个网格粒子的 CP。然后记录 IHV。
(5)对于每个网格粒子,如果此粒子是可移动的,则计算受重力影响的位置,并将此布料粒子的高度与 IHV 进行比较。如果粒子的高度等于或小于 IHV,则此粒子将放置在 IHV 的高度,并设置为“不可移动”。
(6)对于每个网格粒子,计算受内力影响的每个粒子的位移。
(7)重复 (5)–(6)。当所有粒子的最大高度变化 (M_HV) 足够小或超过用户指定的最大迭代次数时,模拟过程将终止。
(8)计算网格粒子和 LiDAR 点云之间的云到云的距离。
(9)区分接地点和非接地点。对于每个 LiDAR 点,如果到模拟粒子的距离小于 hcc,则该点被归类为 BE,否则被归类为 OBJ。
D 后处理
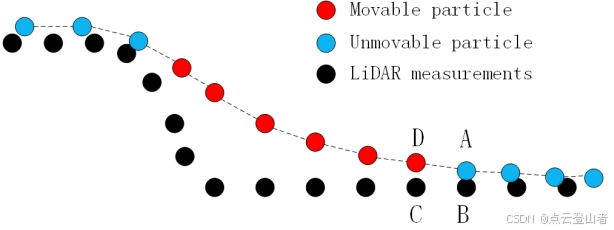
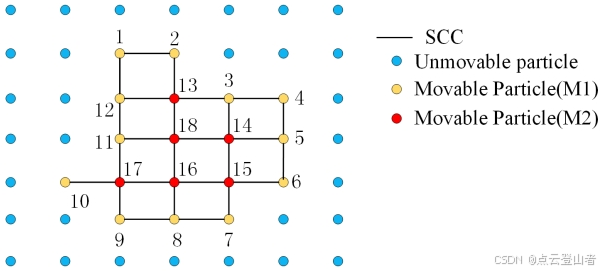
对于陡峭的斜坡,此算法可能会产生相对较大的误差,因为模拟的布料位于陡峭的斜坡上方,并且由于颗粒之间的内部约束,与地面测量值不太吻合,如上图所示。陡坡周围的一些地面测量值被错误地归类为 OBJ。此问题可以通过平滑陡坡边缘的后处理方法来解决。此后处理方法在每个可移动粒子的四个相邻邻域中查找不可移动的粒子,并比较 CP 的高度值。如果高度差在阈值 (hcp) 范围内,则可移动粒子将移动到地面并设置为不可移动。例如,对于上图中的点 D,发现点 A 是来自 D 的四个相邻点的不可移动粒子。然后,比较 C 和 B 之间的高度值(分别为 D 和 A 的 CP)。如果高度差小于 hcp,则此候选点 D 将移动到 C 并设置为不可移动。重复此过程,直到所有可移动粒子都得到正确处理(设置为不可移动或保持可移动)。为了实现后处理,需要遍历所有可移动的粒子,如果逐行扫描布料网格,结果可能会受到这个特定扫描方向的影响。因此,首先构建一组强连接组件 (SCC),每个 SCC 包含一组连接的可移动粒子。在 SCC 中,它通常包含两种粒子,那些至少有一个不可移动邻居的粒子被标记为 M1 类型,其他粒子被标记为 M2(参见下图)。使用 M1 作为初始种子,对 SCC 执行优先遍历,在图中,使用 SCC 从 1 到 18 逐个处理可移动粒子。此过程保证了无论扫描方向如何,后处理都是从边缘到中心执行的。
E 参数解析
CSF 主要由四个用户定义的参数组成:
(1)网格分辨率 (GR),表示两个相邻粒子之间的水平距离;
(2)时间步长 (dT),它控制每次迭代期间粒子从重力引起的位移;
(3)刚性 (RI),控制布料的刚性;
(4)以及可选参数陡坡拟合因子 (ST),用于指示是否需要对处理陡坡进行后处理。
除了这些用户定义的参数外,该算法还使用了两个阈值参数来帮助识别地面点。
第一个是距离阈值 (hcc),它根据到布料网格的距离将 LiDAR 点最终分类为 BE 和 OBJ。此参数设置为 0.5 m 的固定值。
另一个阈值参数是高度差 (hcp),它在后处理过程中用于确定是否应将可移动粒子移动到地面。对于所有数据集,此参数都设置为 0.3 m。
4)实验
A 数据集
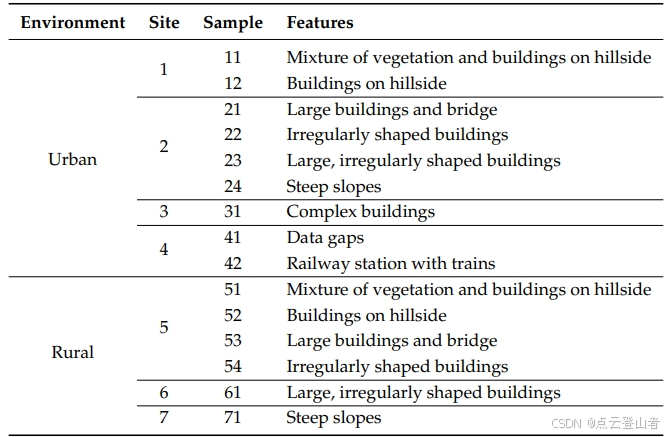
该方法首先通过国际摄影测量与遥感学会(ISPRS)工作组III/3提供的数据集进行了测试,以定量测试不同滤波器的性能并确定未来研究的方向。在这些数据集中,选择了 15 个具有不同特征的样本来测试所提出的 CSF 算法的性能,如下表所示。参考数据集是通过手动过滤 LiDAR 数据集生成的,样本中的每个点都分为 BE 或 OBJ。
B 参数设置
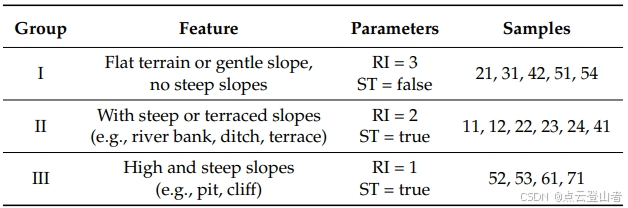
根据 CSF 的实现,当原始 LiDAR 点云倒置时,地面以上的物体会出现在地面测量以下。然后,物体测量的复杂性(例如屋顶)很少影响仿真过程。基于这一特点,根据地形的特性将样品直观地分为不同的组。这些特性表明存在陡坡或梯田坡。如果地形非常平坦,并且没有陡峭或梯田坡度,则 RI 将设置为相对较大的值 (RI = 3),并且不需要后处理 (ST = f alse)。如果存在陡峭的斜坡(例如,河岸、沟渠和梯田),则需要中等软布 (RI = 2) 和后处理 (ST = true)。在处理非常陡峭的斜坡时,我们需要后处理 (ST = true) 和非常柔软的布料 (RI = 1)。因此,这 15 个样品分为三组,每组共享相同的参数集,如下表 所示。
C 结果展示与分析
下图显示了原始数据集、参考 DTM、生成的 DTM 以及一些代表性样本(samp31、samp11 和 samp51)的 I 型和 II 型误差的空间分布。与参考 DTM 相比,生成的 DTM 成功地保留了主要地形形状和微地形,尤其是在矿区(图k)。也可以看到,samp11 和 samp31 的误差点主要存在于对象的边缘,其中一些高度值较低的物体测量值可能被归类为 BE,一些高度值相对较高的地面测量值也可能被归类为 OBJ。samp11 有一大群误差点(II 型),几乎将整个建筑物归类为地面测量值, 发生这种情况是因为建筑物位于斜坡上,并且屋顶几乎与地面相连,导致建筑物在后处理步骤中被视为地面。对于 samp53(与 samp52 和 samp61 相同),非常柔软的布料(第 III 组)使一些小的植被点被错误地归类为 BE。此外,与 BE 点相比,OBJ 点的总数要小得多。

5)结论
本研究提出了一种基于物理过程的新型滤波方法,名为 CSF。它利用布料的性质并修改布料模拟的物理过程以适应点云过滤。与传统的过滤算法相比,参数数量较少且易于设置。无论地面物体的复杂程度如何,样本都根据地形的形状分为三类。需要的参数很少,而且这些参数在三个样本类别中几乎没有变化;用户只需要设置整数参数刚度和布尔参数 ST。这三组参数对于 ISPRS 基准数据集的所有 15 个样本都表现出相对较高的准确性。CSF 算法的另一个好处是,在某些情况下,可以直接将模拟的布料视为最终生成的 DTM,从而避免了地面点的插值,还可以恢复缺失数据的区域。
但是,CSF 算法也有局限性。由于将粒子运动的物理过程修改为两个离散的步骤,因此在处理非常大的低矮建筑物时,粒子可能会粘附在屋顶上,并且一些 OBJ 点可能会被错误地归类为 BE。这个过程通常在屋顶中心产生一些孤立的点,噪声过滤可以帮助缓解这个问题。此外,CSF 算法无法区分连接到地面的物体(例如,桥)。未来,将尝试使用 LiDAR 点的几何信息或结合光学图像(如多光谱图像)来清晰区分桥梁和道路。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











