







K-Means算法(K均值)
一、概念补充
所谓聚类,就是将相似的事物聚集在一起,聚类试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集称为一个“簇”,通过这样的划分,每个簇可能对应于一些潜在的类别。
- 性能度量
对聚类结果,我们需要通过某种性能度量来评估其好坏。
聚类性能度量大致有两类。一类是将聚类结果与某个“参考模型”进行比较,称为“外部指标”;另一类是直接考察聚类结果而不利用任何参考模型,称为“内部指标”。
常用的外部指标有:Jaccard系数,FM指数,Rand指数。
常用的内部指标有:DB指数,Dunn指数。
- 距离计算
通常我们是基于某种形式的距离来定义“相似度度量”,距离越大,相似度越小。
- 能直接在属性值上计算距离的属性,称为“有序属性”,常用“闵可夫斯基距离”:
给定样本![]() 与
与![]() ,距离为
,距离为
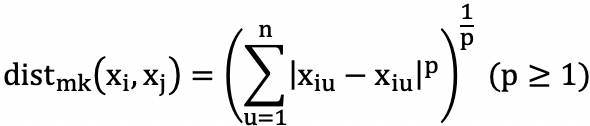
(p=1时,即曼哈顿距离,p=2时,即欧式距离,p→∞时,即切比雪夫距离)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3142
3142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









