







一、前言
在使用LangChain构建自查询检索器时,元数据过滤是一个至关重要的功能,它能够帮助用户更精确地定位所需信息。通过对文档元数据的有效管理和利用,我们可以在检索过程中引入更为细致的过滤条件,例如文档的创建日期、作者、主题标签等。这样,在发起查询时,不仅能够基于关键词进行搜索,还可以根据特定的元数据属性进行筛选,从而提升检索的准确性和效率。
实现这一功能的关键在于设计合理的元数据结构,并在检索算法中集成相应的过滤逻辑。通过这种方式,LangChain不仅能够提供快速的信息检索,还能确保提供的信息与用户的需求高度相关,极大地增强了用户体验和信息获取的便利性。
二、术语
2.1.LangChain
是一个全方位的、基于大语言模型这种预测能力的应用开发工具。LangChain的预构建链功能,就像乐高积木一样,无论你是新手还是经验丰富的开发者,都可以选择适合自己的部分快速构建项目。对于希望进行更深入工作的开发者,LangChain 提供的模块化组件则允许你根据自己的需求定制和创建应用中的功能链条。
LangChain本质上就是对各种大模型提供的API的套壳,是为了方便我们使用这些 API,搭建起来的一些框架、模块和接口。
LangChain的主要特性:
1.可以连接多种数据源,比如网页链接、本地PDF文件、向量数据库等
2.允许语言模型与其环境交互
3.封装了Model I/O(输入/输出)、Retrieval(检索器)、Memory(记忆)、Agents(决策和调度)等核心组件
4.可以使用链的方式组装这些组件,以便最好地完成特定用例。
5.围绕以上设计原则,LangChain解决了现在开发人工智能应用的一些切实痛点。
2.2.ChromaDB
是一个高性能的开源数据库,专门用于存储和检索高维向量数据。它被广泛应用于机器学习和人工智能领域,尤其是在处理自然语言处理(NLP)、计算机视觉和推荐系统等任务时。
2.3.Milvus
是一个开源的向量数据库,专为处理和管理大规模向量数据而设计。它能够高效地存储、检索和分析高维向量,广泛应用于机器学习、自然语言处理、计算机视觉等领域。Milvus 主要用于处理与相似性搜索相关的任务,例如图像检索、推荐系统、文本搜索等。
2.4.FAISS(Facebook AI Similarity Search)
是由 Facebook AI Research 开发的一个开源库,专门用于高效的相似性搜索和密集向量的聚类。FAISS 主要用于处理高维数据,尤其是在机器学习和深度学习领域,常见于图像检索、文本检索和推荐系统等应用。
三、前提条件
3.1. 基础环境
- 操作系统:不限
3.2. 安装虚拟环境
conda create --name langchain python=3.10
conda activate langchain
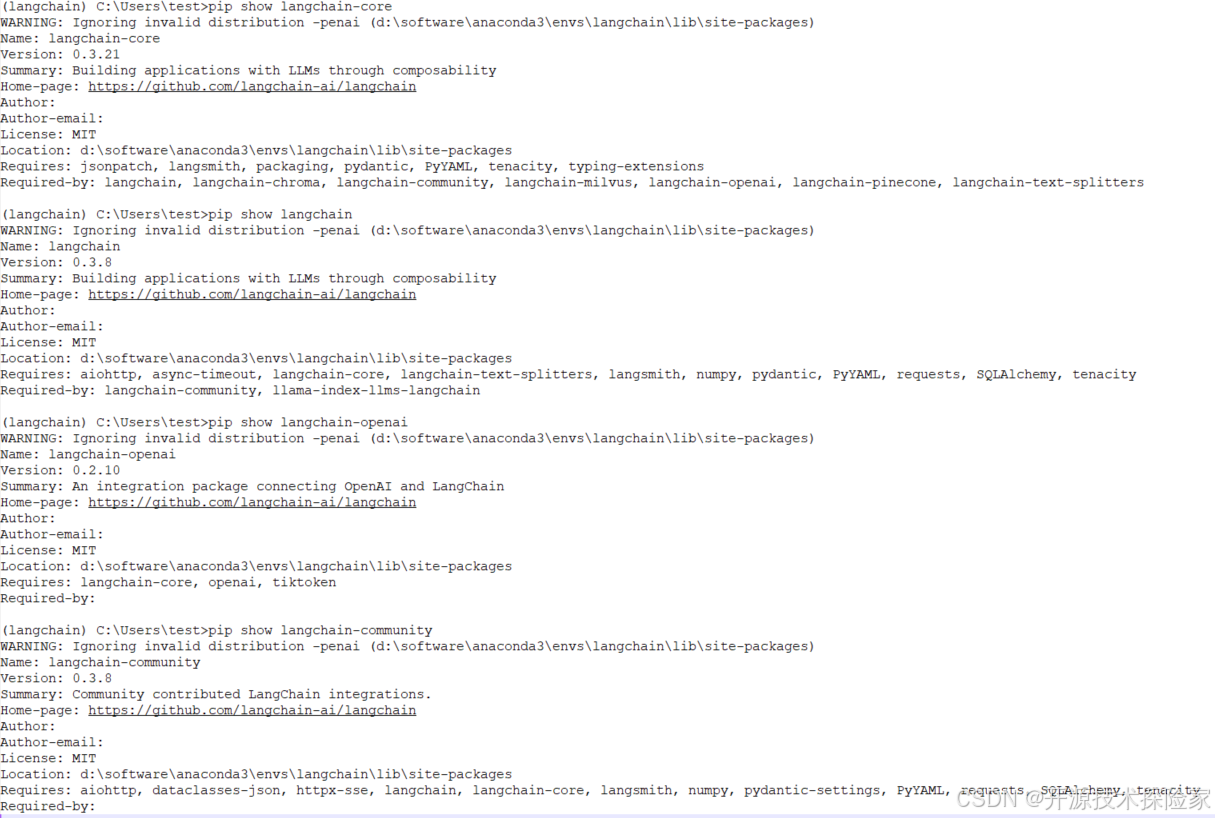
pip install --upgrade --quiet langchain langchain-openai langchain-community langchain-core
pip install --upgrade --quiet langchain-chroma各版本如下:
四、技术实现
4.1. 代码实现
# -*- coding: utf-8 -*-
import os
from langchain.chains.query_constructor.schema import AttributeInfo
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
from langchain_openai import ChatOpenAI
from langchain_openai import OpenAIEmbeddings
os.environ["OPENAI_API_KEY"] = 'sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxx' # 你的Open AI Key
# 1.构建文档列表并上传到数据库
documents = [
Document(
page_content="南沙湿地公园",
metadata={"score": 4.6, "price": 10.0},
),
Document(
page_content="陈家祠",
metadata={"score": 4.5, "price": 20.0},
),
Document(
page_content="长隆欢乐世界",
metadata={"score": 4.8, "price": 250.0},
),
Document(
page_content="越秀公园",
metadata={"score": 4.6, "price": 0.0},
),
Document(
page_content="白云山",
metadata={"score": 4.5, "price": 5.0},
),
]
def getDB():
# URI = 'http://127.0.0.1:19530'
# collection = 'tb_place'
# db = Milvus.from_documents(
# documents,
# embedding=OpenAIEmbeddings(model="text-embedding-3-small"),
# connection_args={"uri": URI},
# )
# db = FAISS.from_documents(documents, OpenAIEmbeddings(model="text-embedding-3-small"))
db = Chroma.from_documents(documents, OpenAIEmbeddings(model="text-embedding-3-small"))
return db
if __name__ == '__main__':
# 2.自查询元数据
metadata_filed_info = [
AttributeInfo(name="score", description="景点的评分", type="float"),
AttributeInfo(name="price", description="景点的门票价格", type="float"),
]
# 3.自查询检索
self_query_retriever = SelfQueryRetriever.from_llm(
llm=ChatOpenAI(model="gpt-3.5-turbo-16k", temperature=0),
vectorstore=getDB(),
document_contents="景点的名称",
metadata_field_info=metadata_filed_info,
enable_limit=True,
verbose=True
)
# 4.检索示例
docs = self_query_retriever.invoke("查找下评分高于4.6分的景点")
print(docs)
4.2. 测试一查找下评分高于4.6分的景点
调用结果:

说明:
返回评分大于4.6分的景点
4.3. 测试二查找下不用钱的景点
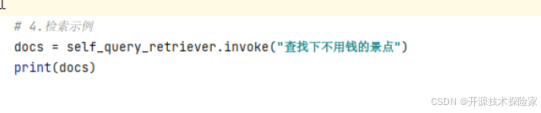
调用结果:

说明:
返回门票为0元的景点
五、附带说明
5.1. FAISS、Milvus不支持构建自查询检索器



















 1146
1146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











