







参考:
https://blog.csdn.net/qq_16234613/article/details/79520929
https://blog.csdn.net/malefactor/article/details/51078135
目录
pooling
目的:
1、整合特征
2、减少参数
2、平移不变性
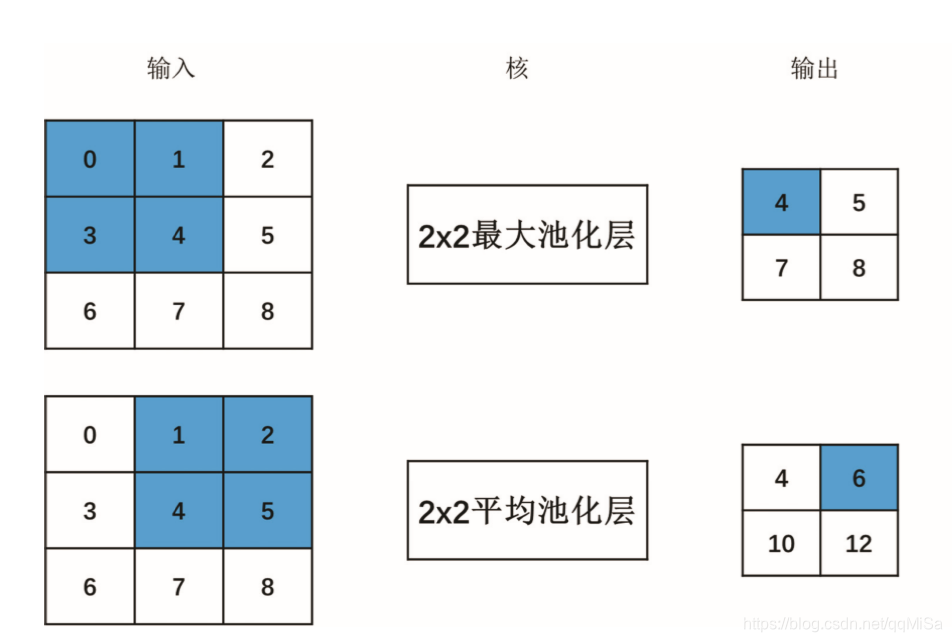
MaxPooling:对邻域内特征点求最大值。
能很好的保留纹理特征
AveragePooling:对邻域内特征点求平均。
能很好的保留背景,但容易使得图片变模糊
除此之外,还有Stochastic-pooling,即随机池化。通过对像素点按照数值大小赋予概率(越大概率越大),再按照概率进行亚采样,概率越大越容易被采到,避免max pooling总是取最大值。在平均意义上,与mean-pooling近似,在局部意义上,则服从max-pooling的准则。
其优点是方法简单,泛化能力更强(带有随机性)
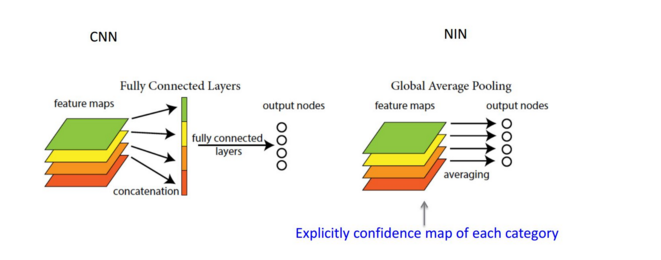
Globalpooling
这个概念出自于 network in network ,主要是用来解决全连接的问题,其主要是是将最后一层的特征图进行整张图的一个均值池化,形成一个特征点,将这些特征点组成最后的特征向量连接到softmax中进行计算.
其优点是大幅度减少网络参数(对于分类网络,全连接的参数占了很大比列),同时理所当然的减少了过拟合现象。赋予了输出feature maps的每个通道类别意义,剔除了全连接黑箱操作,但它可能会导致收敛过慢。
比较直观的解释是下面这张图:
在一些比赛中也有将bert的隐藏层取出做全局平均池化再接softmax等层的做法,而且效果比较不错。
自然语言处理中CNN的一维池化操作
以TextCNN网络结构为例:

各层结构
这里的一维卷积层,其本质上是个特征抽取层,可以设定超参数F来指定设立多少个特征抽取器(Filter),对于某个Filter来说,可以想象有一个k*d大小的移动窗口从输入矩阵的第一个字开始不断往后移动,其中k是Filter指定的窗口大小,d是Word Embedding长度。对于某个时刻的窗口,通过神经网络的非线性变换,将这个窗口内的输入值转换为某个特征值,随着窗口不断往后移动,这个Filter对应的特征值不断产生,形成这个Filter的特征向量。这就是卷积层抽取特征的过程。每个Filter都如此操作,形成了不同的特征抽取器。Pooling 层则对Filter的特征进行降维操作,形成最终的特征。一般在Pooling层之后连接全联接层神经网络,形成最后的分类过程。一般这里有三种常用的pooling方法:
max pooling
k max pooling
Chunk-Max Pooling
对各种池化有一定的总结后才能在自己的模型训练中选择更加合适的池化方式。















 736
736











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









