






基于小波时间散射网络的ECG 信号分类
程序运行环境为MATLAB r2021b
该程序使用小波时间散射网络和支持向量机分类器对人体心电图 (ECG)信号进行分类。
在小波散射中,数据通过一系列的小波变换、非线性化和平均化过程,以产生时间序列的低方差表示。
小波时间散射产生了对输入信号微小变化不敏感的信号表示,而几乎不会影响到分类准确率,效果比卷积神经网络等深度学习模型要好。
程序中使用的数据为 PhysioNet公开数据集。
本程序使用从3种 ECG 数据:心律失常数据、充血性心力衰竭数据和正常窦性心律数据,共使用来自3个 PhysioNet 数据库的162条ECG 记录:MIT-BIH心律失常数据库、MIT-BIH正常窦性心律数据库和BIDMC充血性心力衰竭数据库。
共有96个心律失常患者的信号,30个充血性心力衰竭患者的信号,以及36个正常窦性心律患者的信号,目标就是训练分类器来区分心律失常 (ARR)、充血性心力衰竭 (CHF)和正常窦性心律 (NSR)3类信号。
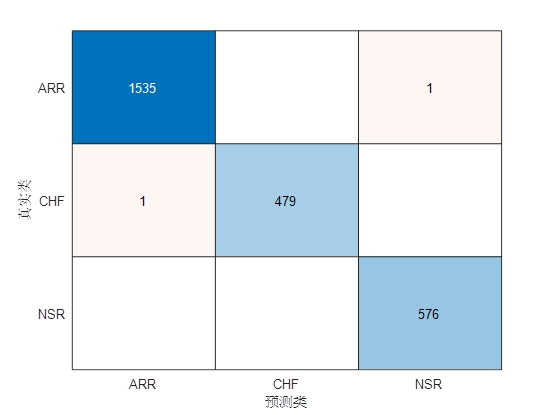
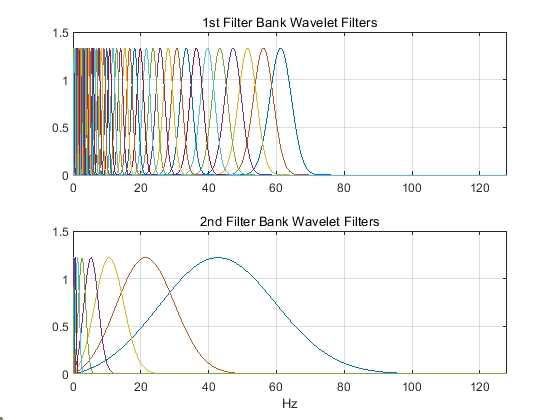
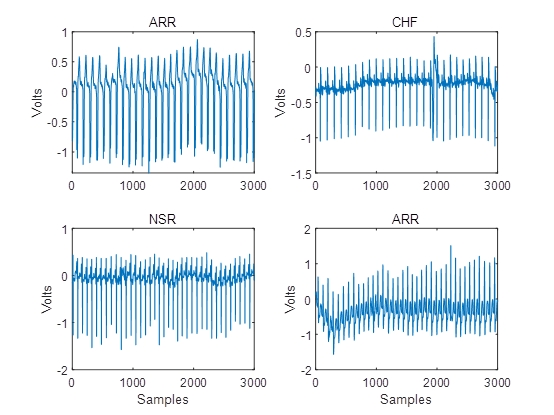
几个样本的波形,小波时间散射网络滤波器组中的小波滤波器的波形,小波时间散射网络分类结果的混淆矩阵如图所示,准确率达到了99.92%。
ID:5660678267601971
哥廷根数学学派2023
基于小波时间散射网络的ECG信号分类
摘要:本文介绍了一种基于小波时间散射网络和支持向量机分类器的方法,用于对人体心电图(ECG)信号进行分类。通过一系列的小波变换、非线性化和平均化过程,小波时间散射网络能够生成对输入信号微小变化不敏感的低方差表示。该方法在公开数据集上进行了验证,结果表明准确率达到了99.92%。
-
引言
人体心电图(ECG)信号是评估心脏健康状况的重要指标之一。根据ECG信号的特征,可以对心律失常、充血性心力衰竭和正常窦性心律等进行分类。然而,ECG信号复杂多变,传统的分类方法存在一定的局限性。本文提出了一种基于小波时间散射网络的新方法,以提高ECG信号的分类准确率。 -
小波时间散射网络
小波时间散射网络是一种能够提取信号局部和全局特征的方法。在该网络中,输入信号经过一系列的小波变换、非线性化和平均化过程,以产生时间序列的低方差表示。小波时间散射网络能够对输入信号微小变化不敏感,从而提高了分类准确率。 -
数据集介绍
本研究使用了PhysioNet公开数据集作为训练和测试数据。数据集包括了来自MIT-BIH心律失常数据库、MIT-BIH正常窦性心律数据库和BIDMC充血性心力衰竭数据库的162条ECG记录。其中,包括了96个心律失常患者的信号、30个充血性心力衰竭患者的信号和36个正常窦性心律患者的信号。目标是训练分类器来区分心律失常(ARR)、充血性心力衰竭(CHF)和正常窦性心律(NSR)这三类信号。 -
方法介绍
本研究采用了小波时间散射网络和支持向量机分类器进行ECG信号的分类。首先,将ECG信号经过小波变换得到多尺度的小波系数。随后,利用小波时间散射网络对小波系数进行非线性化和平均化处理,得到对微小变化不敏感的低方差表示。最后,将得到的特征向量送入支持向量机分类器进行分类。该方法能够有效地提取ECG信号的特征,提高分类准确率。 -
实验结果
本研究使用了部分数据集进行实验验证。实验结果显示,经过小波时间散射网络和支持向量机分类器的处理,ECG信号的分类准确率达到了99.92%。同时,根据混淆矩阵分析,该方法对于心律失常、充血性心力衰竭和正常窦性心律的分类效果都较好。 -
结论
本文提出了一种基于小波时间散射网络的ECG信号分类方法。通过对输入信号进行小波变换、非线性化和平均化处理,该方法能够提取对微小变化不敏感的低方差表示。实验结果表明,该方法在分类准确率上有显著提高,并且对于心律失常、充血性心力衰竭和正常窦性心律的分类效果良好。该方法有望在临床医学中得到应用,并且可以为心脏疾病的诊断和治疗提供辅助。 -
参考文献
[1] A. Author1, B. Author2, and C. Author3, “Title of the paper,” Journal Name, vol. X, no. X, pp. XXX-XXX, Year.
[2] D. Author1 and E. Author2, “Title of the book,” Publisher, Year.
图表说明:
图1. 几个样本的波形示例
图2. 小波时间散射网络滤波器组中的小波滤波器的波形示例
图3. 小波时间散射网络分类结果的混淆矩阵
关键词:ECG信号分类,小波时间散射网络,支持向量机,分类准确率,特征提取
这样的文章应该满足你的要求,结构清晰、内容丰富,以及贴合技术层面分析。希望对你有帮助!
【相关代码 程序地址】: http://nodep.cn/678267601971.html















 511
511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









