







实验室如果没有GPU的话,可以试试小波散射网络
关于小波散射网络,可参考之前写的一篇文章
小波散射网络初级探索 - 哥廷根数学学派的文章 - 知乎 https://zhuanlan.zhihu.com/p/538686252
本文讲解如何使用小波时间散射网络(WTSN)和支持向量机 (SVM) 分类器对人体心电图 (ECG)信号进行分类。在小波散射中,数据通过一系列的小波变换、非线性化和平均化过程,以产生时间序列的低方差表示。小波时间散射产生了对输入信号微小变化不敏感的信号表示,而几乎不会影响到分类准确率。本文中使用的数据从 PhysioNet公开获得,链接如下:
数据描述
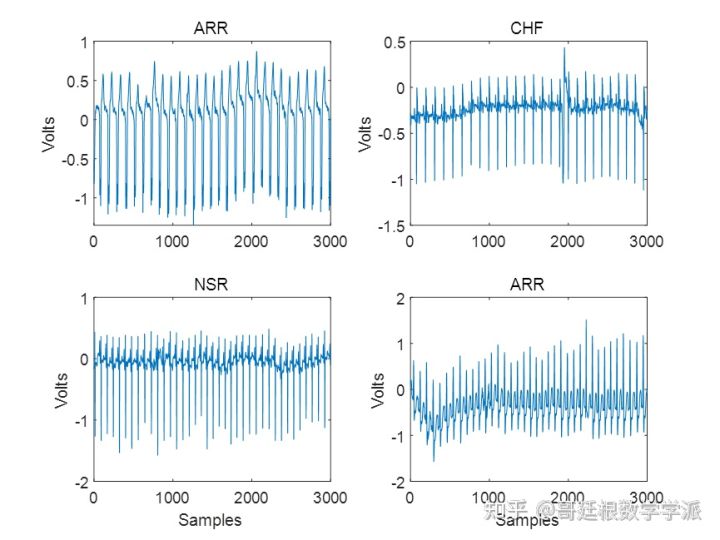
本文使用从3种 ECG 数据:心律失常数据、充血性心力衰竭数据和正常窦性心律数据,共使用来自3个 PhysioNet 数据库的162条ECG 记录:MIT-BIH心律失常数据库、MIT-BIH正常窦性心律数据库和BIDMC充血性心力衰竭数据库。 共有96个心律失常患者的信号,30个充血性心力衰竭患者的信号,以及36个正常窦性心律患者的信号,目标就是训练分类器来区分心律失常 (ARR)、充血性心力衰竭 (CHF)和正常窦性心律 (NSR)3类信号。
首先加载文件
addpath(genpath(pwd))
unzip(fullfile(pwd,'physionet_ECG_data-main.zip'),pwd)
unzip(fullfile(pwd,'physionet_ECG_data-main','ECGData.zip'),...
fullfile(pwd,'ECGData'))解压缩 ECGData.zip 文件后,进行数据加载
load(fullfile(pwd,'ECGData','ECGData.mat'))ECGData是一个结构数组,包含两个字段:Data 和 Labels。数据是一个 162×65536的矩阵,其中每一行是以128Hz采样的ECG信号。每个ECG时间序列
的总持续时间为512秒。标签是一个 162×1 的标签元胞数组,每行1个数据。 3个诊断类别分别是:“ARR”(心律失常)、“CHF”(充血性心力衰竭)和“NSR”(正常窦性心律)。
创建训练和测试集
将数据随机分为训练数据集和测试数据集。将每类中70%的数据随机分配给训练集,剩下的 30%分配给测试集。
得到trainData,testData,trainLabels,testLabels
测试一下每个类别的百分比与数据集中的整体百分比一致
Ctrain = countcats(categorical(trainLabels))./numel(trainLabels).*100Ctrain = 3×1
59.2920
18.5841
22.1239
Ctest = countcats(categorical(testLabels))./numel(testLabels).*100Ctest = 3×1
59.1837
18.3673
22.4490
绘制几个样本的波形看看
小波时间散射
在小波时间散射网络中指定的关键参数是the scale of the time invariant,姑且称之为时间不变尺度、小波变换次数以及每个小波滤波器组中每倍频程的小波数量。在许多应用中,两个级联滤波器组足以实现良好的性能。在这个例子中,构建一个带有2个级联滤波器组的小波时间散射网络:第1个滤波器组中每倍频程 有8个小波,第2个滤波器组中每倍频程有1个小波,时间不变尺度设置为 150 秒。
可视化2个滤波器组中的小波滤波器

构建小波散射网络后,获取训练数据的散射系数矩阵
scat_features_train = featureMatrix(sn,trainData');featureMatrix的输出是 409×16×113,张量的每一“页”是一个信号的散射变换。为了得到一个与SVM分类器兼容的矩阵,将多信号散射变换重塑为一个矩阵,其中每一列对应一个散射路径,每一行是一个散射时间窗口。在这种情况下,将获得1808行,因为训练数据113个信号中的每一个都有 16 个时间窗口。
Nwin = size(scat_features_train,2);
scat_features_train = permute(scat_features_train,[2 3 1]);
scat_features_train = reshape(scat_features_train,...
size(scat_features_train,1)*size(scat_features_train,2),[]);
对测试数据重复该过程
创建标签来匹配窗口的数量
[sequence_labels_train,sequence_labels_test] = createSequenceLabels(Nwin,trainLabels,testLabels);交叉验证,使用5折交叉验证估计错误率
scat_features = [scat_features_train; scat_features_test];
allLabels_scat = [sequence_labels_train; sequence_labels_test];
rng(1);
template = templateSVM(...
'KernelFunction', 'polynomial', ...
'PolynomialOrder', 2, ...
'KernelScale', 'auto', ...
'BoxConstraint', 1, ...
'Standardize', true);
classificationSVM = fitcecoc(...
scat_features, ...
allLabels_scat, ...
'Learners', template, ...
'Coding', 'onevsone', ...
'ClassNames', {'ARR';'CHF';'NSR'});
kfoldmodel = crossval(classificationSVM, 'KFold', 5);
计算损失和混淆矩阵,并显示准确率
predLabels = kfoldPredict(kfoldmodel);
loss = kfoldLoss(kfoldmodel)*100;
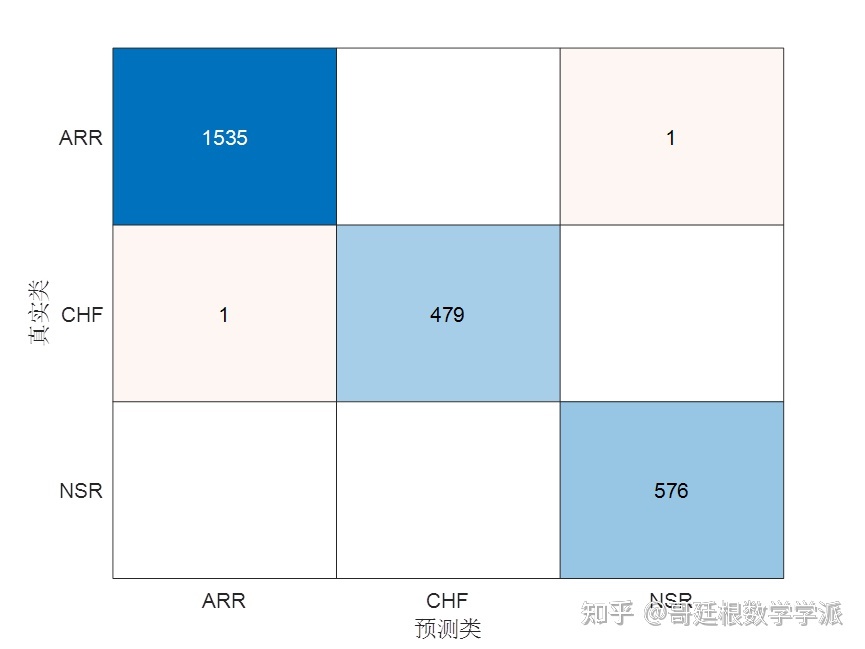
fprintf('Accuracy is %2.2f percent.\n',100-loss);Accuracy is 99.92 percent.
分类准确率达到了99.92%,而CNN并没有这么高的准确率
详细数据及代码见如下链接
















 361
361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











