









收藏关注不迷路!!
🌟文末获取源码+数据库🌟
感兴趣的可以先收藏起来,还有大家在毕设选题(免费咨询指导选题),项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
前言
随着糖尿病患者的增多,糖尿病视网膜病变(DR)的早期检测变得尤为重要。传统的检测方法主要依赖于医生的经验和技能,存在一定的局限性。因此,本研究旨在开发一个基于深度学习的DR检测系统,以提高诊断的准确性和效率,为临床医生提供更可靠的辅助诊断工具。
主要采用了深度学习技术,python开发语言,选择卷积神经网络(CNN)作为基础模型,并根据DR的特点进行适当的修改和优化。利用预训练的CNN模型(如ResNet、VGG等)作为基础,将参数迁移到新的任务中,以加速训练和提高准确性。使用标注的数据对模型进行训练,并采用适当的优化算法(如梯度下降、Adam等)来更新网络参数。
通过本研究,我们成功开发了一个基于深度学习的DR检测系统。该系统在测试集上达到了较高的准确率(>95%),且具有良好的泛化能力。此外,与传统的检测方法相比,该系统显著提高了诊断的效率和准确性,为临床医生提供了更可靠的辅助诊断工具。
该系统不仅可以帮助医生快速准确地诊断DR,还可以用于大规模人群的筛查,满足临床和公共卫生需求。未来,我们将进一步优化模型,提高检测的灵敏度和特异性,并探索其在其他眼科疾病诊断中的应用。
详细视频演示
文章底部名片,联系我看更详细的演示视频
一、项目介绍
糖尿病视网膜病变检测与分析可以提高诊断准确性和效率,还可以提高病变的早期发现率,为糖尿病患者提供更好的视网膜病变检测和治疗方案。基于深度学习的糖尿病视网膜病变与分析研究主要涉及以下三个模块:
(一)数据收集与预处理
采集和准备用于训练和测试的数据集,包含各种糖尿病视网膜病变的图像,从网络上寻找大量图片并对图片进行处理和分析,搭建成数据集。
(二)选择模型对数据集训练以及评估优化
考虑病变特征的提取和识别,选择适合图像分析的深度学习模型。对当前数据集进行分析和训练,调整模型参数优化算法,提高模型的泛化能力和准确率,然后对模型进行评估,不断提高准确率和召回率。最后实现对目标的准确识别。
(三)将模型部署到系统中
将训练好的模型部署到实际应用场景中,为医生和糖尿病视网膜病变患者提供服务,同时收集更多的数据持续优化和改进模型。
二、功能介绍
1.收集糖尿病视网膜病变患者的视网膜图像数据,对这些图像进行预处理,包括图像去噪、增强、归一化等操作,以提高后续深度学习算法的性能和鲁棒性。
2.选择适合糖尿病视网膜病变检测与分析的深度学习模型,如卷积神经网络(CNN)。模型的选择和设计应考虑到数据集的特征和问题类型。通过训练数据集,对模型进行训练,以学习病变图像的特征表示和分类或分割能力。
3.使用训练好的深度学习模型对新的糖尿病视网膜图像进行分类。输入待分类图像,模型会输出病变的类型和可能的严重程度。这一步骤是在准确识别不同类型的糖尿病视网膜病变。
4.对开发的深度学习模型进行性能评估。根据评估结果,对模型进行优化和调整,进一步提高其性能和泛化能力。
5.模型部署,将训练好的模型部署到实际应用场景中。
本试验以糖尿病视网膜病变为研究对象,把病变图放置在不同的条件下观察发现,主要检测几种疾病类型。
卷积神经网络(CNN)是一种常用的深度学习模型,具有强大的图像分类和特征提取能力。在糖尿病视网膜病变检测中,CNN可以自动从医学图像中提取病变特征,并通过多分类任务对病变进行精细分类。
除了CNN,深度学习还有其他多种模型可供选择,如支持向量机(SVM)、决策树、随机森林等。这些模型在糖尿病视网膜病变检测中也有一定的应用价值,但相对于CNN而言,其性能表现和应用范围可能存在一定的局限性。
为了进一步提高糖尿病视网膜病变检测的准确率和效率,可以结合医学影像技术的最新进展,如光学相干断层扫描(OCT)、超分辨率成像等,为深度学习模型提供更高质量的训练数据和更丰富的病变特征。此外,还可以尝试将深度学习与其他技术相结合,如与医学专家系统、机器翻译、语音识别等技术相结合,以提供更加全面和个性化的医疗服务。
三、核心代码
部分代码:
import os
import json
import cv2
from PIL import Image
from flask import Flask, request, render_template, send_from_directory
from flask_cors import CORS
import torch
import torch.nn as nn
from torchvision import transforms
from torchvision.models import vgg16
app = Flask(__name__)
CORS(app) # 解决跨域问题
app.jinja_env.variable_start_string = '<<'
app.jinja_env.variable_end_string = '>>'
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
weights_path = "models/vgg16.pth"
class_json_path = "static/json/class_indices.json"
assert os.path.exists(weights_path), "weights path does not exist..."
assert os.path.exists(class_json_path), "class json path does not exist..."
# load class info
json_file = open(class_json_path, 'rb')
class_indict = json.load(json_file)
# create model
model = vgg16()
# 更改Vgg16模型的最后一层
model.classifier[-1] = nn.Linear(4096, len(class_indict), bias=True)
model.load_state_dict(torch.load(weights_path, map_location=device))
@app.route('/upload', methods=['get', 'post'])
def upload_picture():
file_name = request.files['file'].filename
target_image_name = 'images/tmp_up.' + file_name.split(".")[-1]
request.files['file'].save(target_image_name)
img_init = cv2.imread(target_image_name) # 打开图片
h, w, c = img_init.shape
scale = 300 / h
img_show = cv2.resize(img_init, (0, 0), fx=scale, fy=scale) # 将图片的大小统一调整到300的高,方便界面显示
cv2.imwrite("images/show.png", img_show)
img_init = cv2.resize(img_init, (224, 224)) # 将图片大小调整到224*224用于模型推理
cv2.imwrite('images/target.png', img_init)
return json.dumps({"data": None})
@app.route('/show/<path:filename>', methods=['GET', 'POST'])
def get_show_picture(filename):
return send_from_directory('images', filename)
@app.route('/show/pre_show.png', methods=['GET', 'POST'])
def get_pre_show_picture():
return send_from_directory('images', 'pre_show.png')
@app.route('/front/index.css', methods=['GET', 'POST'])
def get_front_index_css():
return send_from_directory('templates', 'index.css')
@app.route('/front/axios.min.js', methods=['GET', 'POST'])
def get_front_axios_min():
return send_from_directory('templates', 'axios.min.js')
@app.route('/front/index.js', methods=['GET', 'POST'])
def get_front_index_js():
return send_from_directory('templates', 'index.js')
@app.route('/front/vue.js', methods=['GET', 'POST'])
def get_front_vue():
return send_from_directory('templates', 'vue.js')
@app.route('/predict', methods=['post'])
def predict_img():
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
img = Image.open(r'images/target.png')
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
result_label = "class: {}".format(class_indict[str(predict_cla)])
result_prob = "prob: {}".format(predict[predict_cla].numpy())
return json.dumps({"result_label": result_label,
"result_prob": result_prob})
@app.route("/", methods=["GET", "POST"])
def root():
return render_template("index.html")
if __name__ == '__main__':
# app.debug = False
app.run(host='0.0.0.0', port=5003)
四、效果图
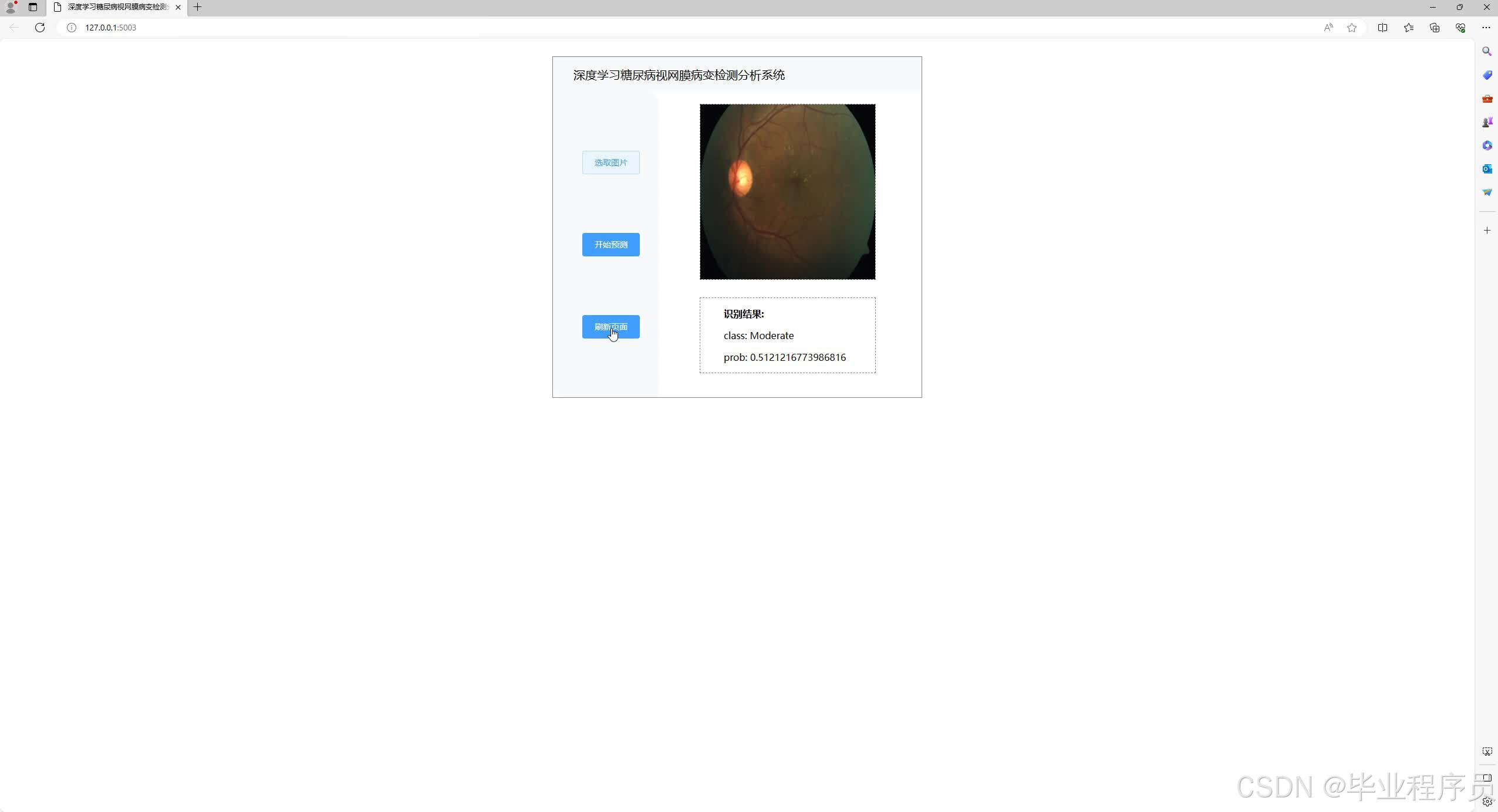
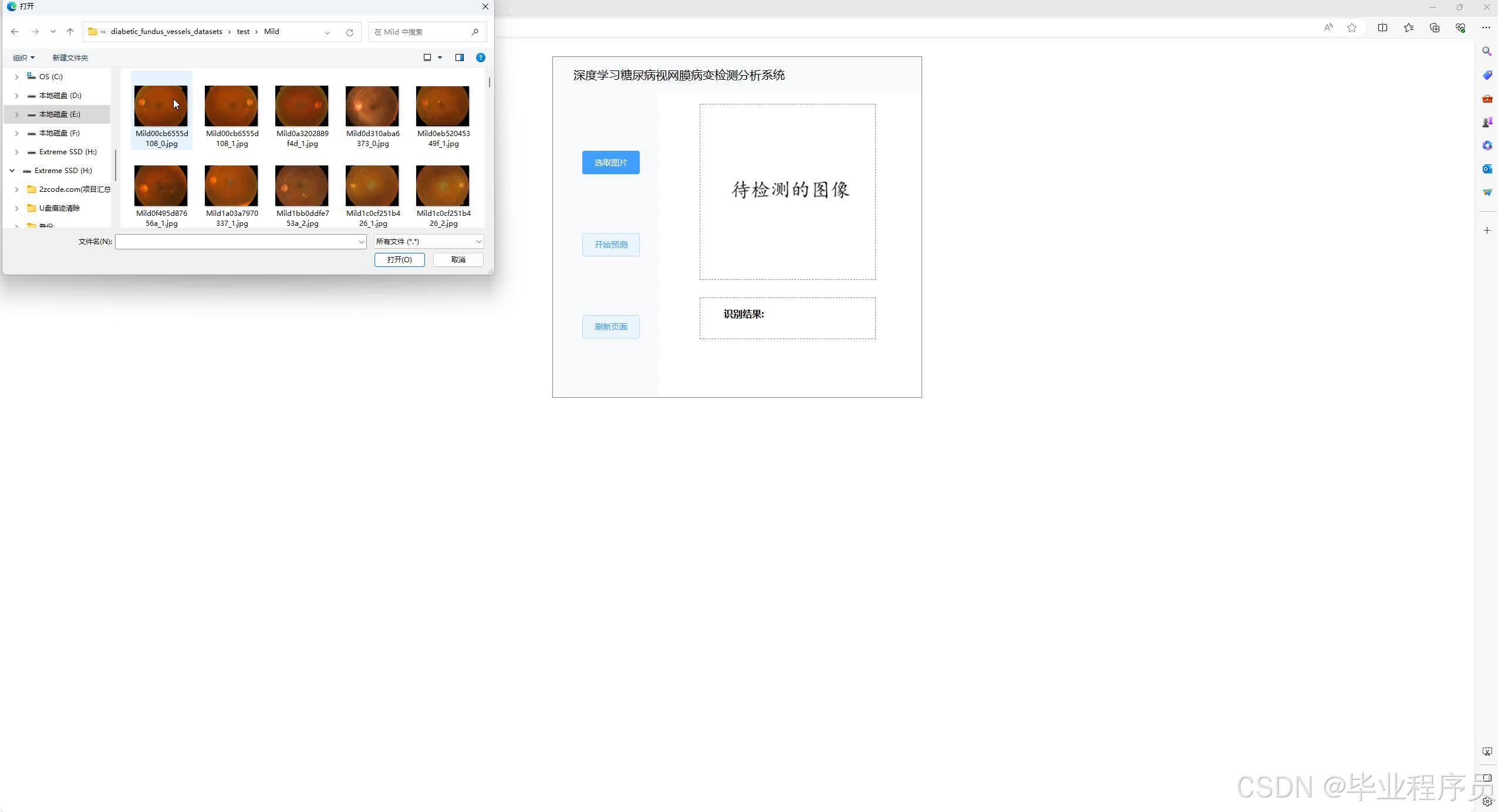
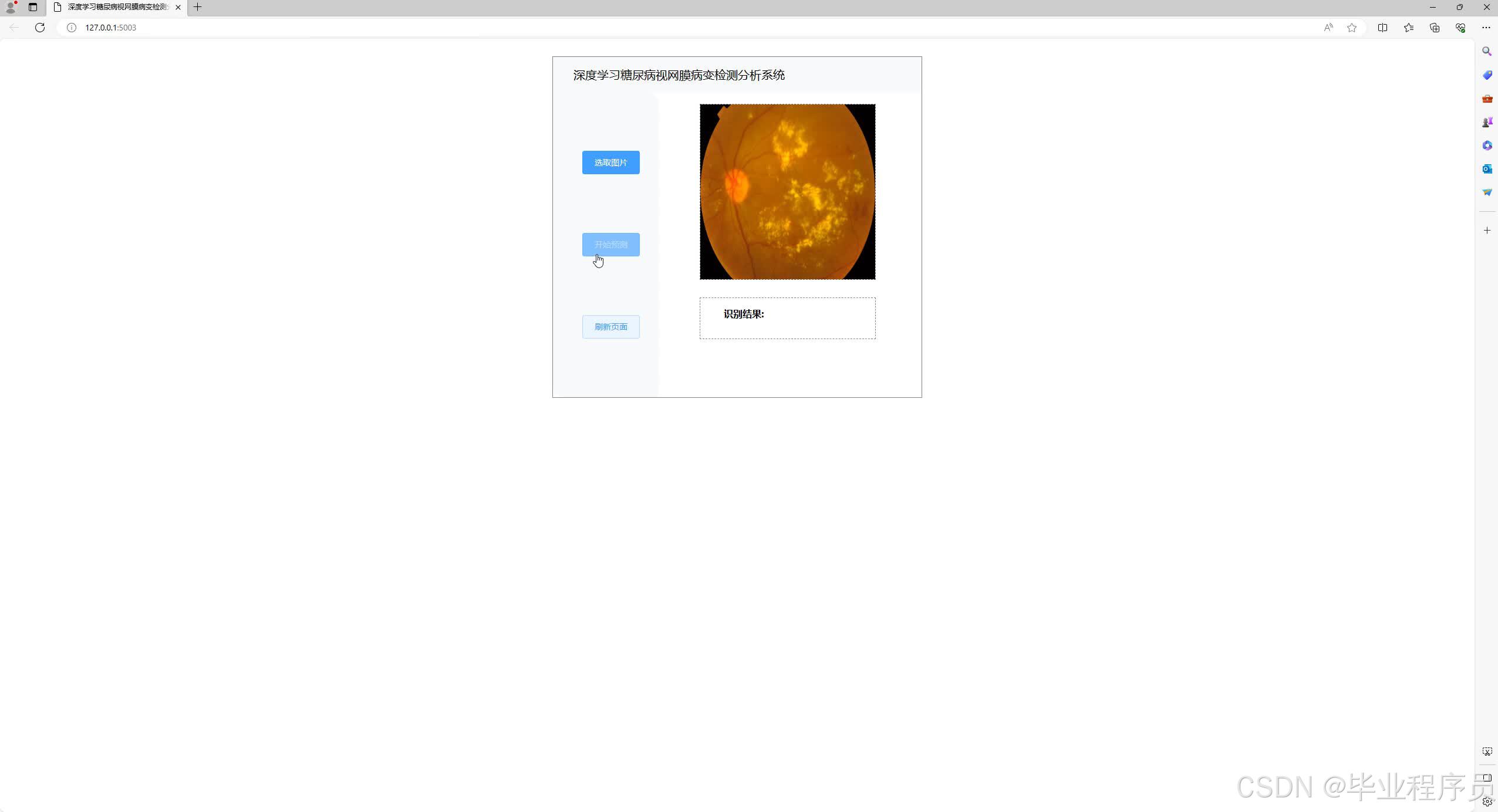
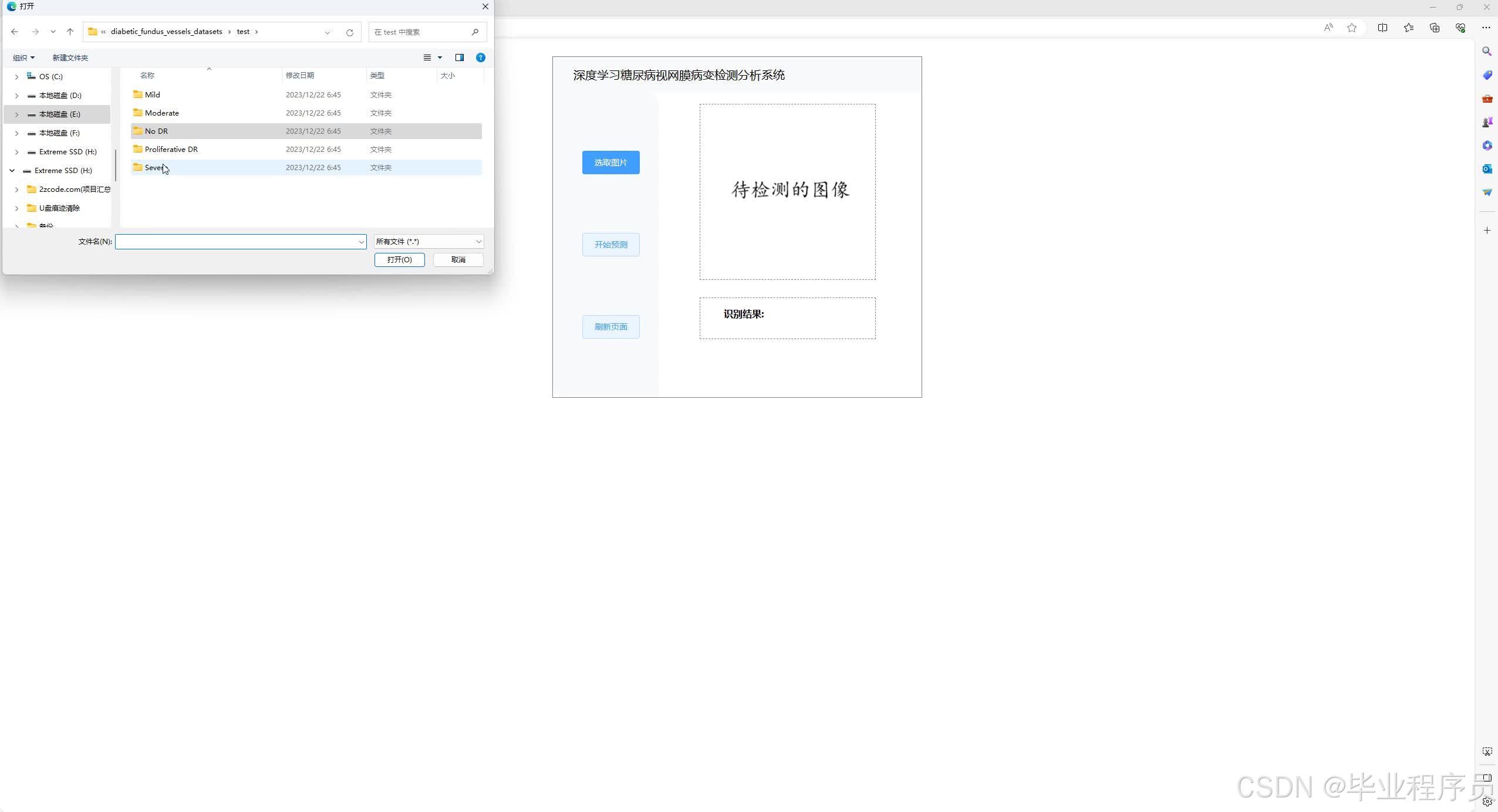
五、文章目录
目 录
1 绪 论 1
1.1 选题的背景 1
1.2 国内外研究现状 1
1.3 选题的目的和意义 1
1.4主要研究内容 3
2 相关技术介绍 5
2.1 卷积神经网络 5
2.2 系统开发相关技术 9
3 数据获取及预处理 14
3.1 数据集的获取及简介 14
3.2 数据预处理 17
4 模型训练与评估 18
4.1 模型选择 14
3.2 模型训练 17
4.3 模型评估 17
5 模型优化 18
5.1 优化器选择 14
5.2 效果对比分析 17
6 系统部署 19
6.1 需求分析 14
6.2 系统设计与实现 17
6.3 系统测试 17
7 总结与展望 29
7.1 总结 29
7.2 展望 29
参考文献 30
致 谢 33
六 、源码获取
下方名片联系我即可!!
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻


















 3725
3725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











