







1、贝叶斯公式:
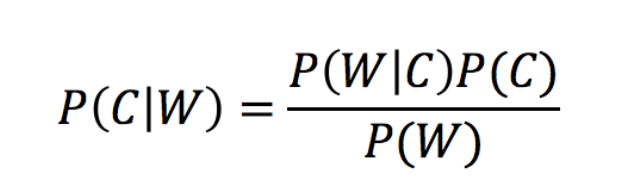
2、拉普拉斯平滑系数(防止计算出的概率为0的情况):
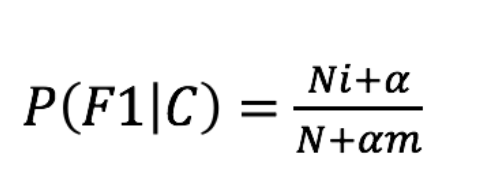
from sklearn.datasets import load_breast_cancer #导入数据
from sklearn.metrics import accuracy_score #准确率
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.naive_bayes import MultinomialNB #朴素贝叶斯
def pbaye_algorithm():
'''
朴素贝叶斯:假定事件之间相互独立,使用贝叶斯公式对样本进行计算,常用拉普拉斯平滑系数消除由于数据集有限导致概率为0的情况;
优点:1)有有稳定的分类效率;2)对缺失数据不太敏感,算法简单;3)分类准确度高,速度快
缺点:特征属性有关联时其效果不好
应用:常用语文本分类等
API:sklearn.naive_bayes.MultinomialNB(alpha = 1.0)
alpha:拉普拉斯平滑系数
'''
datal = load_breast_cancer()
x_train,x_test,y_train,y_test = train_test_split(datal['data'],datal['target'],random_state = 20,train_size = 0.8)
pbaye = MultinomialNB()
pbaye.fit(x_train,y_train)
pred = pbaye.predict(x_test)
print(accuracy_score(y_test,pred))
print(confusion_matrix(y_test,pred))
print(classification_report(y_test,pred))
return None
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











