







Hierarchical Gaussian Mixture Normalizing Flow Modeling for Unified Anomaly Detection
1、Background
在这项工作中,旨在解决一个更实际的任务:统一异常检测。如图1b所示,一个统一的模型用多个类别的正常样本进行训练,目标是无需任何微调就能检测所有这些类别的异常。然而,解决这样一个任务是非常具有挑战性的。
目前,有两种基于重建的异常检测方法来应对这一具有挑战性的统一AD任务,UniAD和PMAD。但是,基于重建的方法可能会陷入“相同捷径重建”的困境,其中异常也可以被很好地重建,导致异常检测失败。UniAD和PMAD试图通过掩盖相邻或可疑的异常来避免相同的重建。然而,由于异常的规模和形状多样,掩盖机制不能完全避免重建过程中异常信息的泄露,相同重建的风险仍然存在。
为此,考虑从正常数据分布学习的角度来设计统一AD模型。优势在于原则上不再面临异常信息泄露的风险,因为HGAD方法基于正常数据分布,并且根本上避免了重建。具体来说,使用归一化流(NF)来学习正常数据分布。
然而,发现基于NF的AD方法在应用于统一AD任务时表现不佳。它们通常会陷入**“同质映射”问题,其中基于NF的AD模型倾向于为正常和异常输入生成大的对数似然**(见图2b)。
分析了这一问题,认为基于NF的AD方法采用了单峰高斯先验来学习多类分布(多峰)。这可以看作是从异构空间学习到潜在同构空间的映射。为了更好地学习这种映射,网络可能会倾向于关注粗粒度的共同特征(例如,局部像素相关性)并抑制不同类别特征之间的细粒度可区分特征(例如,语义内容)。因此,网络将不同类别的特征同质地映射到接近的潜在嵌入中。即使异常也能获得大的对数似然,变得不易区分。
为了解决这个问题,首先实证确认了映射到多峰潜在分布是有效的,可以防止模型学习到这种偏差(见图2c)。因此,提出了一种类间高斯混合建模方法,用于基于NF的AD网络,以更有效地捕获复杂的多类分布。其次,认为类间高斯混合建模只能确保特征被吸引到整个分布中,但缺乏类间排斥,导致对不同类别特征的区分能力仍然较弱。这可能导致不同类别中心坍塌到同一个中心。
为了进一步提高类间可区分性,提出了一种互信息最大化损失,以引入类别排斥属性,更好地构建潜在特征空间,其中类别中心可以相互推开。第三,引入了类内混合类中心学习策略,可以促使模型即使在一个类内也能学习多样的正常模式。最后,形成了一种用于统一异常检测的层次高斯混合归一化流建模方法,称之为HGAD。
supplement
基于归一化流(Normalizing Flow)的异常检测方法是一种利用归一化流模型来学习正常数据分布,并通过比较测试数据与该分布的匹配程度来检测异常的方法。归一化流是一种深度生成模型,它通过一系列可逆的变换将一个简单的概率分布(如标准正态分布)转换成一个更复杂的分布,以此来模拟数据的分布。在异常检测的上下文中,这种方法的核心思想是:
-
学习正常数据分布:归一化流模型被训练以最大化正常样本的对数似然(log-likelihood),这意味着模型试图找到参数,使得正常样本在模型定义的分布下出现的概率最大。
-
异常检测:在训练完成后,模型能够为新的输入样本估计一个对数似然值。异常样本通常与正常数据分布不一致,因此它们的对数似然值会显著低于正常样本。通过设置一个阈值,可以识别出那些对数似然值低于阈值的样本作为异常。
-
可逆变换:归一化流的一个关键特点是其变换是可逆的,这意味着可以从潜在空间中的任何点映射回原始数据空间的点。这种可逆性不仅有助于理论上的概率密度估计,还有助于生成样本和进行精确的异常评分。
-
模型结构:归一化流模型通常由多个“耦合层”组成,每一层都对数据的某些部分进行变换,同时保持其他部分不变。这些层的设计允许模型捕捉数据中的复杂结构和依赖关系。
-
异常评分:在基于归一化流的异常检测中,异常评分通常是基于样本的对数似然值或者与正常数据分布的偏离程度来计算的。对数似然值越低,样本是异常的可能性就越大。
基于归一化流的异常检测方法在处理高维数据和复杂数据分布时表现出了强大的能力,但同时也需要仔细设计和调整模型结构和训练策略,以确保模型能够有效地区分正常和异常样本。此外,这类方法通常需要大量的正常样本来训练,而在实际应用中,异常样本往往是稀缺的。因此,如何有效地利用有限的异常样本或者无监督地提高模型的异常检测能力,是当前研究中的一个活跃领域。
在文献中提到的“同质映射”(homogeneous mapping)问题是指在使用基于归一化流(NF)的方法进行统一异常检测(Unified Anomaly Detection, UAD)时遇到的一个挑战。统一异常检测的目标是训练一个模型,使其能够检测多个类别数据中的异常,而不仅仅是单一类别。这个问题的核心在于,当模型试图将来自多个类别的正常数据映射到一个共同的潜在空间时,可能会忽略不同类别数据之间的细微但重要的特征差异。
具体来说,“同质映射”问题表现在以下几个方面:
-
特征表示的偏差:在训练过程中,基于NF的AD模型可能会倾向于学习一种偏差,将不同类别的正常和异常特征都映射到潜在空间中的相似区域。这意味着模型可能会为正常和异常输入生成较大的对数似然值,导致难以区分它们。
-
忽略类别间差异:由于模型试图将所有输入映射到一个单一的高斯先验分布,它可能会过度关注不同类别之间的共同特征(如局部像素相关性),而忽略那些区分不同类别的细粒度特征(如语义内容)。
-
异常检测性能下降:由于模型无法有效地区分不同类别的正常和异常特征,它可能会将异常特征误判为正常,导致异常检测的漏检率(false negative rate)升高。
为了解决这个问题,文献中提出的HGAD方法采用了层次高斯混合建模,通过引入类间高斯混合建模和类内混合类中心学习策略,增强了潜在空间的表示能力。这种方法可以避免将不同类别的分布映射到相同的单一高斯先验,从而有效地避免了或减轻了“同质映射”问题。此外,通过最大化互信息损失,模型被鼓励学习更强的类间排斥性,进一步增强了对不同类别特征的区分能力。
2、Method
HGAD(Hierarchical Gaussian Mixture Normalizing Flow Modeling for Unified Anomaly Detection)方法主要的核心思想:
- 层次高斯混合建模(Hierarchical Gaussian Mixture Modeling):HGAD通过层次化的高斯混合模型来拟合不同类别的正常数据分布。这种方法可以为每个类别甚至类别内的不同模式学习独特的潜在表示,从而增强模型对不同类别特征的区分能力。
- 互信息最大化(Mutual Information Maximization):通过引入互信息最大化损失,HGAD鼓励模型将不同类别的特征映射到不同的类中心,增强了类间区分能力,并避免了类别中心的坍塌。
- 类内混合类中心学习(Intra-Class Mixed Class Centers Learning):HGAD进一步考虑了即使在单个类别内部也可能存在多样的正常模式,通过学习类内混合的类中心来更好地模拟这些模式。
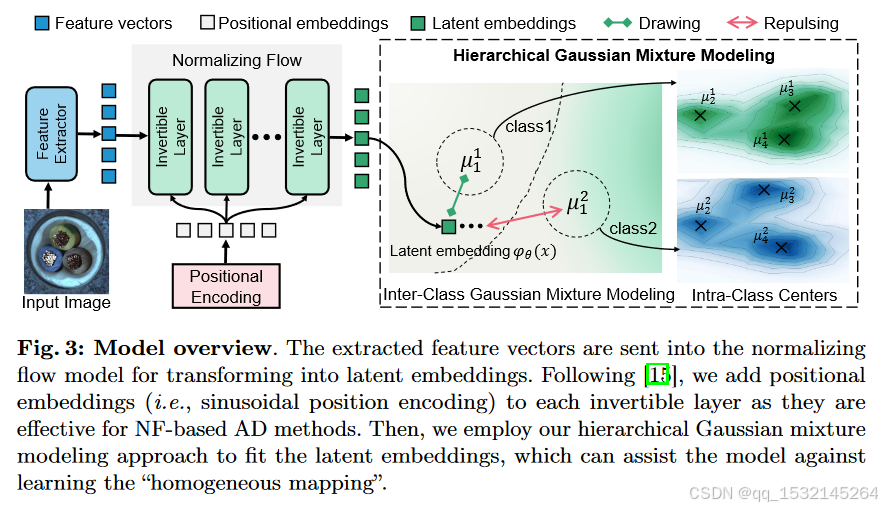
层次高斯混合归一化流模型(HGAD)的整个流程如下:
-
特征提取:
- 首先,使用预训练的特征提取器(例如EfficientNet)从输入图像中提取特征向量。这些特征向量捕获了图像的高层表示,为后续的异常检测提供了基础。
-
归一化流模型:
- 提取的特征向量随后被送入归一化流(NF)模型。归一化流模型是一种能够学习输入数据分布的生成模型,通过一系列可逆的变换将特征向量映射到潜在空间中的嵌入(latent embeddings)。
-
位置编码:
- 为了提高归一化流模型的性能,特别是在异常检测任务中,模型在每个可逆层中加入了位置编码,通常是正弦位置编码。这种编码方式有助于模型捕捉输入数据的空间结构信息,从而更有效地进行异常检测。
-
层次高斯混合建模:
- 在潜在空间中,使用层次高斯混合建模方法来拟合由归一化流模型生成的潜在嵌入。这种方法通过引入多个高斯分布来模拟不同类别数据的复杂分布,每个类别或类别内的不同模式都有其对应的高斯分布中心。
- 这种层次建模策略有助于区分不同类别的特征,避免了“同质映射”问题,即避免了将不同类别的数据映射到相同的潜在空间区域,从而提高了模型区分正常和异常样本的能力。
-
对抗“同质映射”:
- 通过层次高斯混合建模,模型能够学习到每个类别的独特特征,即使在统一模型中处理多个类别的数据时,也能保持对异常的敏感性。这有助于减少正常样本和异常样本在潜在空间中的重叠,提高异常检测的准确性。
总的来说,图3展示了HGAD方法如何通过结合归一化流模型和层次高斯混合建模来有效地进行统一异常检测。这种方法通过在潜在空间中为每个类别或模式分配独特的表示,解决了传统方法在多类别数据上训练时可能出现的“同质映射”问题。
pseudo-code
import torch
import torch.nn as nn
import torch.optim as optim
class HGAD(nn.Module):
def __init__(self, num_classes, num_features, num_intra_centers):
super(HGAD, self).__init__()
# 初始化类中心
self.class_centers = nn.ParameterDict({
f'mu_{y}': nn.Parameter(torch.randn(num_features)) for y in range(num_classes)
})
# 初始化可学习向量
self.class_weights = nn.Parameter(torch.zeros(num_classes))
self.intra_class_weights = nn.ParameterDict({
f'psi_{y}': nn.Parameter(torch.zeros(num_intra_centers)) for y in range(num_classes)
})
# 初始化归一化流模型
self.normalizing_flow = NormalizingFlow(num_features)
def forward(self, x, y):
# 特征提取
features = self.extract_features(x)
# 归一化流转换
latent_embeddings = self.normalizing_flow(features)
# 计算损失
return self.calculate_loss(latent_embeddings, y)
def extract_features(self, x):
# 使用预训练的特征提取器提取特征
# 这里假设有一个预训练的特征提取器模型
return feature_extractor(x)
def calculate_loss(self, latent_embeddings, y):
# 计算类间损失
Lg = self.class_loss(latent_embeddings, y)
# 计算互信息最大化损失
Lmi = self.mutual_information_loss(latent_embeddings, y)
# 计算熵损失
Le = self.entropy_loss(latent_embeddings, y)
# 计算类内损失
Lin = self.intra_class_loss(latent_embeddings, y)
# 总损失
L = Lg + Lmi + Le + Lin
return L
def class_loss(self, latent_embeddings, y):
# 类间高斯混合建模损失
pass
def mutual_information_loss(self, latent_embeddings, y):
# 互信息最大化损失
pass
def entropy_loss(self, latent_embeddings, y):
# 熵损失
pass
def intra_class_loss(self, latent_embeddings, y):
# 类内混合类中心学习损失
pass
# 训练模型
def train(model, dataloader, optimizer):
model.train()
total_loss = 0
for x, y in dataloader:
optimizer.zero_grad()
loss = model(x, y)
loss.backward()
optimizer.step()
total_loss += loss.item()
return total_loss / len(dataloader)
# 测试模型
def evaluate(model, dataloader):
model.eval()
total_auc = 0
with torch.no_grad():
for x, y in dataloader:
# 计算AUROC
auc = calculate_auroc(model(x, y), y)
total_auc += auc
return total_auc / len(dataloader)
# 主程序
if __name__ == "__main__":
num_classes = 10 # 类别数量
num_features = 128 # 特征数量
num_intra_centers = 5 # 类内中心数量
model = HGAD(num_classes, num_features, num_intra_centers)
optimizer = optim.Adam(model.parameters(), lr=0.001)
dataloader = DataLoader(dataset, batch_size=32) # 数据加载器
for epoch in range(100):
train_loss = train(model, dataloader, optimizer)
test_auc = evaluate(model, test_dataloader)
print(f'Epoch {epoch}, Train Loss: {train_loss}, Test AUC: {test_auc}')
3、Experiments
🐂🐎。。。
4、Conclusion
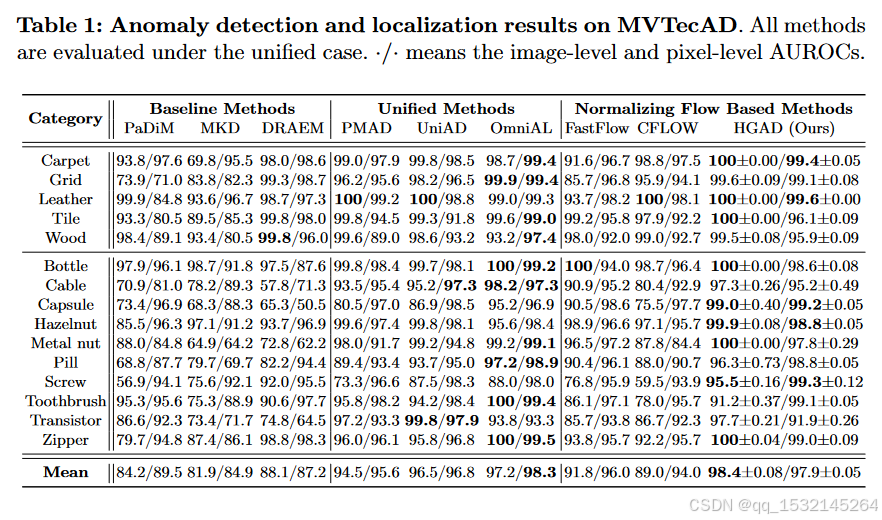
本研究专注于如何统一多类别的异常检测。对于这样一项具有挑战性的任务,流行的基于归一化流的异常检测方法可能会陷入“同质映射”问题。为了解决这个问题,提出了一种名为HGAD的新型方法,通过三个关键改进来对抗学习偏差:类间高斯混合建模、互信息最大化和类内混合类中心学习策略。在统一的异常检测设置下,该方法可以显著提高基于NF的异常检测方法的性能,并且也超越了最新的统一异常检测方法。

















 2797
2797

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









