







| 三、实验内容及步骤:
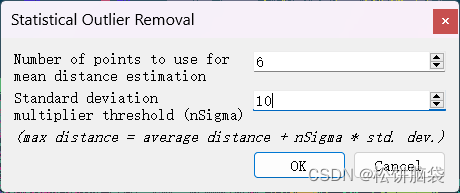
图1 SOR剔除的参数设置 number of points to use for mean distance estimation值设为6 Standard deviation multiplier threshold(nSignma)值设为10, 在这种情况下,算法将计算每个点与其6个最近邻的平均距离,并根据 nSigma * 标准差阈值过滤距离超出平均距离的点。这种设定可以充分去除离群点,同时保留较大对象的细节和形状特征,所以得到了最佳结果。
图1 SOR异常值剔除离群点 1.2、剔除地面连接点 使用【Plugins】下的【CSF Filter】剔除掉地面连接点的点云数据
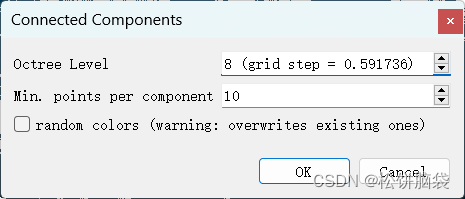
1.3、使用【Tools】-【Segementation】-【Label Connected Components】进行聚类分析 1.3.1、此处要分割出树的数据,可设置的参数为八叉树分级和每簇点云数据的最小点数值
图2 聚类分析参数设置 1.3.2、将两个参数设为不同值并进行比较得出最佳的参数设置结果 以下参数设置表达为10-1000表示八叉树分级和每簇点云数据的最小点数值为10和1000,其他类似。
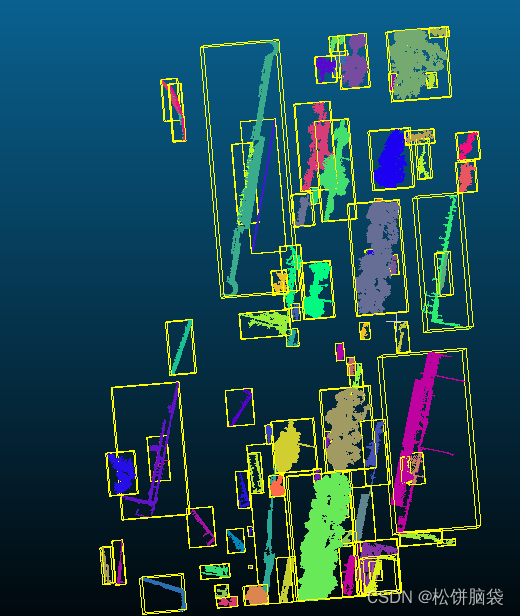
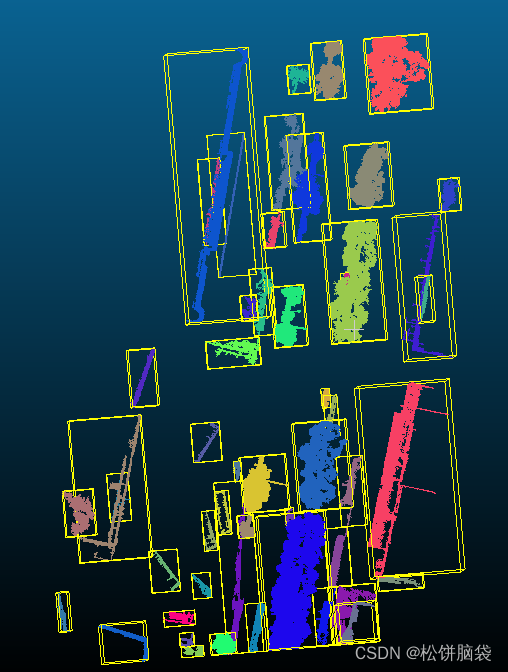
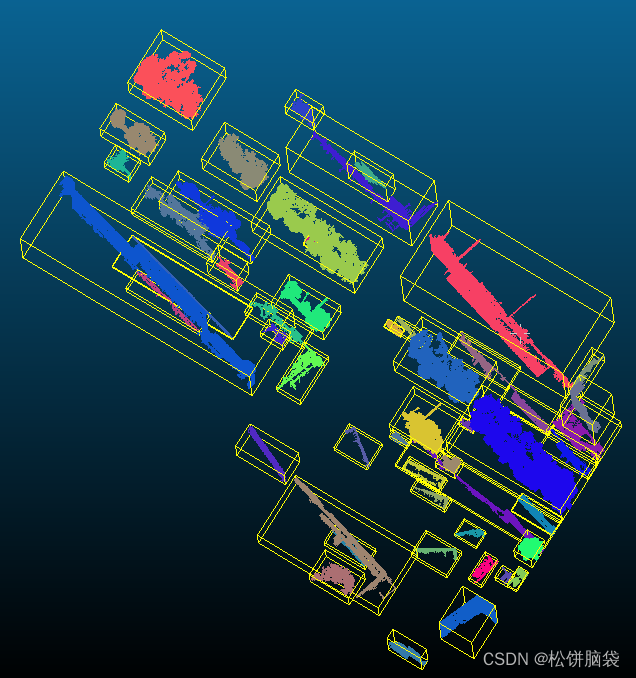
1.3.3、分析聚类分析结果 对比8-1000和10-1000的一小部分图发现,在树与花坛有点云数据相连的部分时,八叉树等级设为8并为精细分开,这是设为10时结果更优
再对比10-1000和10-2000的一小部分图 ,可以发现每簇点云数据的最小点数值设为1000时,最后所得的簇树很多,给后续的手工处理带来更多的操作量,可得设为2000时结果更优
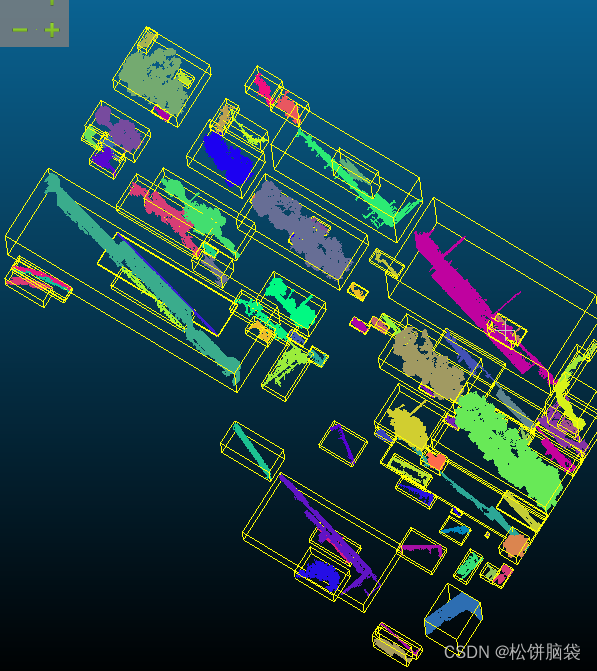
根据所得结果保留树的cluster,得到结果图
图6 保留树的点云数据后的结果图 | ||||||||||||||||||||||||||||||






















 2290
2290
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









