







 本文提出了一种针对稀疏标注的弱监督点云语义分割方法CPCM,通过区域屏蔽和上下文屏蔽训练来有效提取上下文信息。实验结果显示,CPCM在ScanneNetV2和S3DIS基准上表现出色,超越了现有技术。
本文提出了一种针对稀疏标注的弱监督点云语义分割方法CPCM,通过区域屏蔽和上下文屏蔽训练来有效提取上下文信息。实验结果显示,CPCM在ScanneNetV2和S3DIS基准上表现出色,超越了现有技术。

摘要:
我们研究了稀疏标注(例如,标注点少于 0.1%)的弱监督点云语义分割任务,旨在降低密集标注的昂贵成本。然而在标注点极其稀疏的情况下,很难同时提取上下文信息和物体信息来进行场景理解(如语义分割)。受图像和视频表示学习中的掩蔽建模(如 MAE)的启发,我们试图赋予掩蔽建模从稀疏注释点中学习上下文信息的能力。然而,直接将 MAE 应用于具有稀疏注释的三维点云可能会失败。首先,从三维点云中有效地遮蔽出信息丰富的视觉上下文并非易事。其次,如何充分利用稀疏注释进行上下文建模仍是一个未决问题。在本文中,我们提出了一种简单而有效的上下文点云建模(CPCM)方法,该方法由两部分组成:区域屏蔽(RegionMask)策略和上下文屏蔽训练(CMT)方法。具体来说,RegionMask 在几何空间中连续屏蔽点云,为后续的上下文学习构建有意义的屏蔽预测任务。CMT 分离了有监督分割学习和无监督掩蔽上下文预测学习,分别用于有效学习非常有限的标记点和大量未标记点。在广泛测试的 ScanNet V2 和 S3DIS 基准上进行的大量实验证明,CPCM 优于最先进的技术。

介绍:
在几种弱注释标签类型中,部分点标注方案是注释成本与分割性能之间的最佳权衡方案[9, 22]。在部分标注的点云数据中,标注部分通常只占每个场景中很小一部分点(如 0.1%)[9]。在这种情况下,只对有限的标注部分直接应用有监督的交叉熵损失容易造成过拟合 [25, 33, 43]。因此,主要的挑战是从相当大比例的未标注点进行学习,以提高模型的泛化性能,而不是只利用标注点[16, 53]。
现有方法试图通过利用各种数据增强下不同程度的特征一致性来应对这一挑战。具体来说,研究人员通过对比学习[8, 11, 16, 45]、探索颜色和几何平滑度[48, 52]、更先进的一致性损失(如 JSdivergence[53] 和相似性加权损失[43])来区分来自不同场景的点,从而在不同增强或几何校准的点云之间实现特征一致性。然而,由于注释有限,仅探索特征一致性不足以捕捉点云的复杂结构,因此很难同时提取上下文信息和对象信息以获得令人满意的分割性能。为了检验基于一致性的方法对场景上下文的理解能力,我们通过掩蔽评估进行了一项试验性研究:评估给定上下文待填充点云的分割性能。如图 1 所示,基于一致性的方法的性能急剧下降,表明即使在这种简单的情况下,对场景上下文的理解也很差。因此,从大量无标记点中理解复杂的场景背景仍然是一个尚未解决的问题。
图像和视频中的遮蔽建模(如 MAE [7])通过遮蔽输入图像的随机片段并重建缺失信息来学习良好的表示,受此启发,我们试图将遮蔽建模的强大功能用于弱监督点云分割。然而,由于以下原因,直接将 MAE 应用于具有稀疏注释的三维点云可能会失败。首先,由于三维点云通常是无序和不规则的,因此要从三维点云中屏蔽出信息丰富的视觉上下文以进行后续上下文学习并非易事。其次,考虑到弱标注点云中有限但有价值的标注数据,如何在屏蔽建模中充分利用标注点仍是一个未决问题。
我们提出了一种简单而有效的上下文点云建模(CPCM)方法,它由两部分组成:区域屏蔽(RegionMask)策略和上下文屏蔽训练(CMT)方法。具体来说,RegionMask 将几何空间均匀地划分为一组立方体,并以给定的掩蔽率掩蔽所选立方体内的所有点。与执行点随机屏蔽的微不足道的点屏蔽解决方案[26]不同,我们的 RegionMask 在几何空间中连续屏蔽点云,以提供有意义的屏蔽上下文预测任务。除此之外,RegionMask 还能通过调整超参数区域大小来控制掩蔽特征预测任务的难度,从而灵活处理不同数量的注释。与 MAE[7]类似,我们预计在很高的掩码比(即 0.75)下,模型能够学习到更多的视觉概念[7],从而掌握上下文信息。然而,正如我们的实验所显示的那样,直接将掩码建模目标纳入基于一致性的训练框架会阻碍从有限但有价值的标注点进行学习,从而导致性能下降。为了解决这个问题,我们提出了一种上下文掩蔽训练(CMT)方法,在基于一致性的框架中增加了一个额外的掩蔽特征预测分支,这不仅为学习标记数据铺平了道路,还能让模型有效地学习复杂的场景上下文。所提出的 CPCM 在两个广泛测试的基准 ScanNet V2 和 S3DIS 上取得了一流的性能。例如,在 ScanNet V2 [4],CPCM 在在线测试集上以 5.6% 的 mIoU 优于 SQN [9]。
相关工作:
弱监督点云分割。从弱标注点云数据中学习已成为一个热门研究课题 [9、25、42、43、48、52、53],这不仅降低了标注成本,而且对于现实生活中的分割场景来说是一种更通用的解决方案 [22、42]。对于部分标注的点云,监督交叉熵损失适合从标注点学习,但由于标注非常有限,容易学习到过拟合的分割模型[25, 33, 43]。因此,现有方法侧重于学习主要的未标注部分,可分为两种范式:伪标注 [9, 25, 42] 和基于一致性的正则化 [16, 48, 49, 52, 53]。伪标注方法预测未标注点的伪标签,以探索这些点。MPRM [42] 在子云标签上训练分割模型,并使用类激活图[55]对整个子云进行伪标签,以训练最终模型。OTOC [25] 通过多轮自我训练提高了伪标签的质量。SQN [9] 则利用几何先验来更好地利用有限的标签。由于伪标签注定是不准确的,因此基于一致性的方法会学习不同增强[16, 43, 48, 49, 52, 53]或校准视图[43]的特征一致性,以使用大量无标签数据。MIL[49]为模型优化强制执行场景级特征一致性。此外,通过考虑颜色或几何平滑度[48, 52]、特征相似性[43, 53]或使用伪标记作为指导[16],也可利用点上一致性。然而,不同增强体之间的特征一致性可能无法完全理解弱标注点云的复杂结构。相反,我们建议学习屏蔽特征一致性,以更好地探索上下文信息。
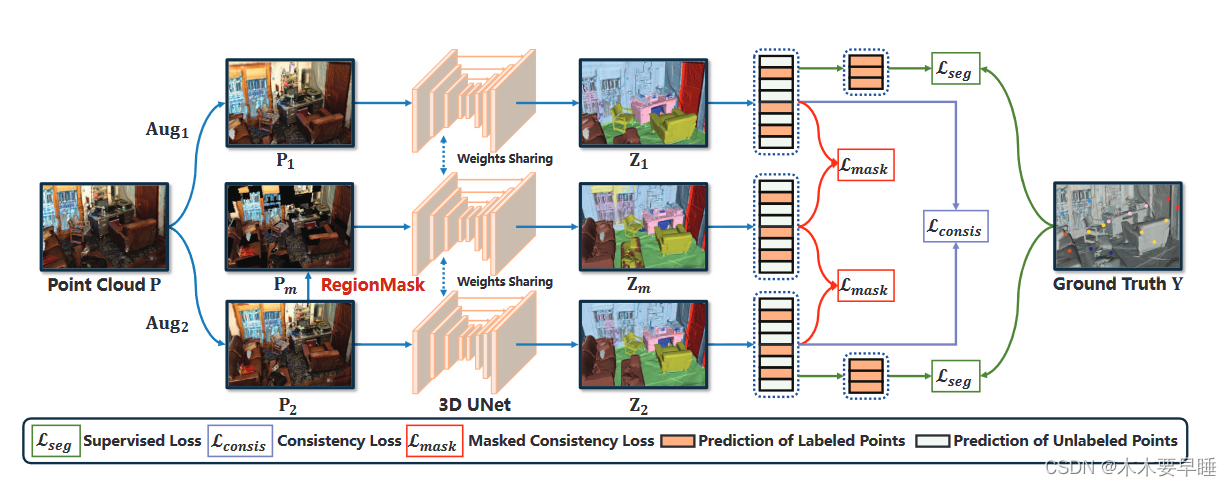
点云上下文建模:
面对有限的标记数据和大量的未标记数据,弱监督点云语义分割侧重于从大量的未标记数据中学习有用的表征,以提高模型的泛化能力。现有的方法通常是通过在各增强点之间强制执行点特征一致性来实现这一目标 [16, 48, 49, 53]。给定一个弱标记点云数据(P,Y),应用两个随机增强:P1 = Aug1(P)和 P2 = Aug2(P)。在此基础上,通过 Z1 = Softmax(fθ(P1))、Z2 = Softmax(fθ(P2))计算两个点云的点分类。基于一致性的方法的一般形式如下:
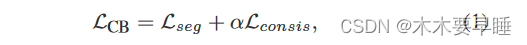
![]()
![]()
来自不同增强的特征一致性可以利用无标记数据,但信息量可能不足以理解点云数据的复杂结构,无法有效探索空间、颜色和语义连续性等对满意分割至关重要的上下文信息。在图像和视频表征学习中,掩蔽建模具有强大的上下文建模能力,受此吸引,我们试图将掩蔽建模的强大功能赋予弱监督点云分割。然而,为三维点云数据设计有效的掩码策略,以及开发兼容的训练方案以充分利用有限的标记数据进行掩码建模,仍然是有待解决的问题。
为了回答上述问题,我们提出了上下文点云建模(CPCM),通过两个步骤对上下文信息进行有效建模:首先,我们提出了一种区域性屏蔽策略,在连续的几何空间中屏蔽点云,提供有意义的缺失上下文信息。通过增加一个额外的掩蔽特征提取流,促进有限标记点的学习和掩蔽特征预测任务的上下文掩蔽训练。然后,我们在屏蔽和未屏蔽特征之间执行特征一致性,以学习有效的上下文表征。CPCM 的整体框架和算法分别如图 2 和算法 1 所示。
本节中,我们将介绍区域性掩蔽方案,它为模型学习上下文信息提供了有效的监督信号。为了制定掩蔽策略,我们首先定义 M∈R N 为零一向量,表示点云 P∈R N×6 中的点是否被掩蔽,并将掩蔽率表示为 R(0 ≤ R ≤ 1),即被掩蔽点的数量为 R∗ N。然后,以点为单位将颜色信息设为零,计算出遮蔽点云 Pm:
![]()
要获得遮蔽点云,一种简单直接的解决方案(称为 PointMask)是以给定的遮蔽率 R 对每个点(或体素)进行随机采样。
如表 4 所示,与基线相比,PointMask 的改进效果并不理想,尤其是在掩码率非常高(即 0.75)的情况下。我们认为失败的原因如下:PointMask 策略往往会降低点云的分辨率(见图 3b),从而无法有效屏蔽有意义的视觉词[7]进行预测。

为了合理地去除点云中的一些背景信息,我们引入了区域屏蔽(RegionMask)技术,它能将场景均匀地分割成立方体.屏蔽了随机选取的立方体内的点。我们首先定义区域大小 G 来表示立方体的数量。请注意,在三维坐标系中,平行于坐标轴的立方体用[(xmin,ymin,zmin), (xmax,ymax,zmax)]表示。假设覆盖点云的最小立方体为[(0, 0, 0), (l, w, h)]。
RegionMask 可连续屏蔽无序和不规则的点云,提供有意义的上下文待填充模式,如部分内实例屏蔽和跨实例屏蔽。此外,如第 4.3 节所示,RegionMask 还能通过调整区域大小灵活应对不同数量的注释。

本节将介绍我们的上下文掩码训练方法,用于学习掩码数据和未掩码数据之间的上下文信息。我们首先将掩码操作视为 "强增强",并将其直接纳入基于一致性的训练框架。然而,如图 4 所示,训练交叉熵误差显著增加,性能大幅下降。这些结果表明,掩码操作极大地改变了输入分布,阻碍了从有限但有价值的标注点进行学习。 我们建议增加一个额外的分支来执行屏蔽特征预测任务,而不触及两个弱监督分支。具体来说,给定一个弱标记点云数据(P, Y),我们通过两次随机增强获得两个点云 P1、P2,并通过建议的 RegionMask 获得掩蔽版本 Pm。然后,我们使用分割模型 Softmax(fθ(-)) 提取它们对应的特征 Z1、Z2、Zm。最后,我们的上下文掩码训练的总体训练目标如下:
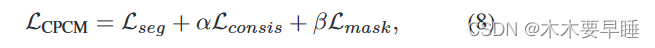
我们试图通过屏蔽和未屏蔽特征来学习上下文信息。为此,我们建议尽量缩小遮挡特征和未遮挡特征之间的分布差距。这样,模型就能学会利用屏蔽点云中的未屏蔽部分,即周围环境,从而提高分割性能。具体来说,我们分别从两个随机增强点云和屏蔽点云中提取特征 Z1、Z2 和 Zm,并引入屏蔽一致性损失如下:
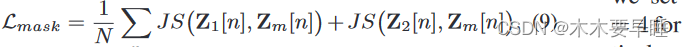
实验:
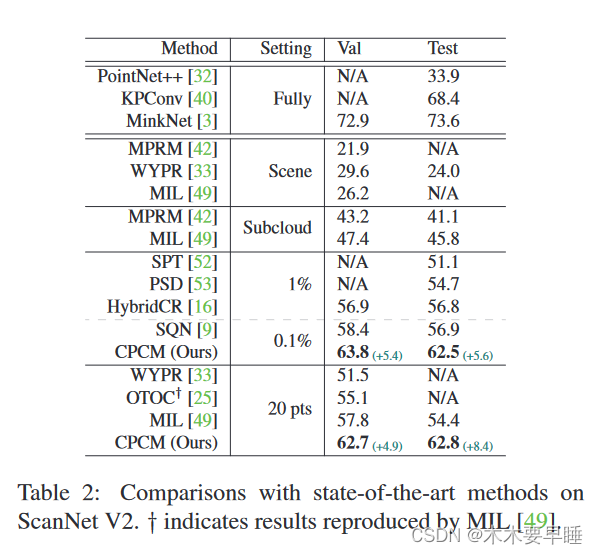
。。。
总结:
在这项工作中,我们研究了弱监督点云分割任务中的上下文信息学习问题,现有方法尚未对这一问题进行深入探讨。为此,我们提出了 CPCM,通过强制屏蔽特征的一致性来模拟大量未标记点之间的上下文关系。我们首先介绍了一种区域性掩蔽策略,以有效灵活地掩蔽点云,为后续学习生成上下文待填充数据。然后,我们提出了一种上下文掩蔽训练方法,帮助模型从有限的标注数据和掩蔽特征预测任务中捕捉上下文信息。在弱监督点云分割基准上进行的大量实验表明,我们的方法性能优越。未来,我们将在弱监督点云检测和实例分割中进一步探索屏蔽建模方案。

















 5689
5689

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











