







参考大数据百度网盘下载链接: 决战大数据 提取码: qkxt
1 Presto整体架构
Presto采用典型的master-slave模型:
- coordinator(master):负责meta管理,query的解析和调度,worker管理
- worker:负责计算和读写。
下图中浅蓝色的部分主要在Presto-main中进行实现。
红色部分的API是由Presto-spi实现了接口定义,main中调用spi实现与数据源的交互。
SPI具体的实现则是由各个数据库的connector层来实现的。

2 Presto主要流程

- 通过jdbc或cli获得SQL语句,将SQL语句组装为一个Restful请求,发给coordinator,等待返回response。
Statement、Query、Stage、Task、Split、Driver、Operator、Exchange
coordinator 拆分整个计划,使得集群中的 worker 节点能够并行处理,加速了整个查询过程。拥有多个阶段会导致创建阶段的依赖树。stage 的数量依赖于查询的复杂度。
stage 是计划片段的运行时化身,它包含由 stage 的计划片段描述的工作的所有任务。

分布式查询计划定义了查询在 presto 集群上执行的 stage 和方式。coordinator 用来进一步在 worker 之间计划和调度任务。一个 stage 由一个或多个 任务构成。
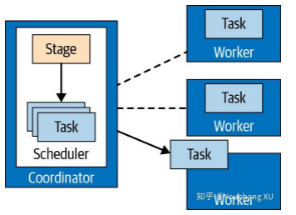
任务被指定到 worker 节点时,是运行时计划片段的化身。当任务被创建后,它给每一个 split 实例化一个 driver。每个 driver 是对 split 中数据操作处理的 pipeline 的实例化。一个 task 可能使用一个或多个 driver,这取决于 presto 的配置。一旦 所有的 driver 结束,数据将会传递到下一个 split,driver 和 task 将随着他们工作的结束被销毁。

为了处理查询,协调器将使用连接器中的元数据创建 split 列表。通过使用 split 列表,协调器开始调度 worker 节点上的任务,以收集 split 中的数据。在查询执行期间,协调器跟踪可用于处理的所有 split,以及在工作线程和处理 split 上运行任务的位置。当任务完成处理并为下游处理生成更多split时,协调器将继续调度任务,直到没有 split 可供处理为止。在worker上处理完所有 split后,所有数据都可用,协调器可以将结果提供给 client。

split : 任务处理的数据单位被称为 split,split 是底层数据段的描述符,可以由工作进程检索和处理。
pages :
- 任务在源阶段以 pages 的形式处理数据,这是一组列格式的行。这些 pages 流向其他中间下游阶段。Pages 通过交换操作在 stages 之间转换,从上游 stage 的任务读取数据。一个 task 操作的序列被称作 pipeline。pipeline 的最后一个操作通常是放置它的 output pages 到任务的 output buffer。下游任务的交换操作消费来自上游任务 output buffer 的 pages。所有的这个操作并行发生在不同的 worker 中。
- source 任务在 connector 的帮助下,使用 data source SPI 从底层数据源获取数据,这些数据以页面的形式呈现给Presto并流经引擎。Operators 根据他们的语法,处理并产生 pages。

3 Presto查询执行模型
- Statement: 语句。指输入的符合ANSI标准的SQL语句。该语句由子句(Clause)、表达式(Expression)、断言(Predicate)组成。
- Query:执行查询。当收到一个查询语句时,会解析该SQL语句,将其转变成一个查询执行和相关的查询执行计划。查询执行代表在Presto集群中运行的查询。
- Stage:查询执行阶段,一个Query会被拆分成具有多个层级关系的stage. Stage是树状结构,每个Query都有一个Root stage. Stage并不会在集群中实际执行。每个Stage(除了Source stage和single stage)都会有输入输出。Source stage的上游是Connector。
- Exchange:Presto的stage通过Exchange来交换数据。主要有两种Exchange:Output buffer和Exchange Client
- Task:Stage在逻辑上被划分为很多Task,运行在worker上,从而可以并行执行Stage。每个Task处理一个或多个Split。每个Task都有对应的输入和输出。一个Task也可以分解为多个Driver,从而可以并行执行Task.
- Driver:一个Driver代表作用于Split上的一系列operator集合,一个Driver处理一个Split
- Operator:一个Operator代表对Split的一种操作,如过滤或加权。以Page为最小单位进行处理。Operater每次只会读取一个page,每次也只会返回一个Page。
- Split:一个大的数据集中一个小的子集。Driver是作用于一个分片上的一系列操作的集合,每个节点上包含多个Driver,从而一个Task可以运行多个split。当Presto执行一个查询的时候,先从coordinator得到一个表对应的所有split,然后presto会根据查询执行计划选择合适的节点运行相应的Task处理Split。
- Page:Page是Presto处理的最小单元,一个Page包含多个Block对象,每个Block对象是一个字节数组,存储一个字段的多个行。多个Block横切的一行是真实的数据。一个Page最大为1MB。
4 执行流程
代码执行链
********************************* statementResource生成 *********************************************************
StatementResource.createQuery //创建并执行查询
Query.create(statement,...)
Query result = new Query() //返回结果Result
QueryInfo queryInfo = queryManager.createQuery(sessionContext, query)
Statement wrappedStatement = sqlParser.createStatement(query, createParsingOptions(session));
queryExecution = queryExecutionFactory.createQueryExecution(queryId, query, session, statement, parameters);
resourceGroupManager.submit(statement, queryExecution, selectionContext, queryExecutor);
groups.get(selectionContext.getResourceGroupId()).run(queryExecution);
executor.execute(query::start);
PlanRoot plan = analyzeQuery();
metadata.beginQuery(getSession(), plan.getConnectors());
planDistribution(plan); //由plan构建task并进行分发调度计划,这个调度计划体现在Scheduler上
StageExecutionPlan outputStageExecutionPlan = distributedPlanner.plan(plan.getRoot(), stateMachine.getSession()); // 获得stage的执行计划
SqlQueryScheduler scheduler = new SqlQueryScheduler();//完成了sqlStageExecution和stageSchedulers的创建
List<SqlStageExecution> stages = createStages(); //根据不同的情况,生成对应的stage;体现为不同的StageScheduler和SqlStageExecution
SqlStageExecution stage = new SqlStageExecution() //
stageSchedulers.put(stageId, SourcePartitionedScheduler||new FixedCountScheduler(stage, partitionToNode||FixedCountScheduler)); //根据handle类型
SqlQueryScheduler.start();//分发计划体现在plan创建的Scheduler上
SqlQueryScheduler##executor.submit(this::schedule); //Async, 循环执行,直到 execution 完成.
SqlQueryScheduler##stageSchedulers.get(stageId).schedule(); //使用上述 StageScheduler 的实现类来分发 Task 到工作节点
taskScheduler.apply(entry.getValue(), entry.getKey())); //对该函数(this.taskScheduler = stage::scheduleTask;)使用这两个参数执行
sqlStageExecution::scheduleTask; // 在new StateSchedule中构造函数中获取remoteTasks赋值给其属性taskScheduler
RemoteTask(HttpRemoteTask) task = remoteTaskFactory.createRemoteTask() //
task.start(); //HttpRemoteTask-%s
scheduleUpdate();
HttpRemoteTask.sendUpdate(); // 异步请求
HttpClient.executeAsync(): // 发送请求到 TaskResource.createOrUpdateTask()
asyncQueryResults
StatementResource.getQueryResutl() // 分批获取查询结果,client向coor不断请求,每次获得部分结果,就是由该方法处理的。
asyncQueryResults
note:查询请求上的token是用来保证分批查询结果的顺序的
********************************* SqlTask *********************************************************
Reponse TaskResource.createOrUpdateTask(TaskId,TaskUpdateRequest,UriInfo) // 这个request请求的中就含有Fragment信息,后续会根据Fragment信息创建SqlTaskExecution
TaskInfo taskInfo = taskManager.updateTask(session,...)
sqlTask.updateTask(session, fragment, sources, outputBuffers);
SqlTaskExecution SqlTaskExecutionFactory.create(Session session, QueryContext queryContext, TaskStateMachine taskStateMachine, OutputBuffer outputBuffer, PlanFragment fragment, List<TaskSource> sources)
localExecutionPlan = LocalExecutionPlaner.plan( taskContext, fragment.getRoot(), fragment.getSymbols(), fragment.getPartitioningScheme(), fragment.getPipelineExecutionStrategy() == GROUPED_EXECUTION, fragment.getPartitionedSources(), outputBuffer);
PhysicalOperation physicalOperation = plan.accept(new Visitor(session, planGrouped), context); //physicalOperation这个持有OperatorFactory
context.addDriverFactory(); //将physicalOperation放到DriveFactory,其实DriveFactory也就是在localExecutionPlan中
SqlTaskExecutionFactory.createSqlTaskExecution( taskStateMachine, taskContext, outputBuffer, sources, localExecutionPlan, taskExecutor, taskNotificationExecutor, queryMonitor); //physicalOperation在其中localExecutionPlan的DriveFactory中
SqlTaskExecution.createDriver(DriverContext driverContext, @Nullable ScheduledSplit partitionedSplit) // 将physicalOperation放到了driverContext中
new SqlTaskExecution() //重要重要
taskExecutor.addTask() //添加task
********************************* Task执行 *********************************************************
TaskExecutor.start() //@PostConstruct
ExecutorService.execute()
TaskRunner.run()
PrioritizedSplitRunner.process() //
DriverSplitRunner.processFor() // DriverSplitRunner是SqlTaskExe内部类
DriverSplitRunnerFactory.createDriver()
Driver.processFor()
Driver.processInternal()
Driver.processNewSources()
Operator.getOutput(); // 会根据不同的 sql 操作,得到不同的 Operator 实现类.然后根据实现,调用对应的 connector . 该方法返回的是一个 Page, Page 相当于一张 RDBMS 的表,只不过 Page 是列存储的. 获取 page 的时候,会根据 [Block 类型,文件格式]等,使用相应的 Loader 来 load 取数据.
Operator.addInput(); //下一个 Operator 如果需要上一个 Operator 的输出,则会调用该方法

















 1537
1537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











