







问题:现有的深度聚类方法往往忽略了数据之间的关系。
本文提出了一种基于交叉注意的深度聚类框架——基于交叉注意融合的增强型图形卷积网络(CaEGCN) ,该网络包含四个主要模块: 交叉注意融合模块,创新性地将与个体数据相关的内容自编码模块(CAE)和与逐层数据之间关系相关的图形卷积自编码模块(GAE)连接起来;以及自监督模型,该模型突出了聚类任务的鉴别信息。交叉注意融合模块融合了两种异构表示,CAE 模块补充了 GAE 模块的内容信息,避免了 GCN 的过度平滑问题。在 GAE 模块中,提出了两种新的损失函数,分别重建数据的内容和数据之间的关系。最后,自监督模块约束 CAE 和 GAE 中间层表示的分布是一致的。
1)提出一种基于端到端交叉注意融合的深度聚类框架,其中交叉注意融合模块创造性地将图卷自动编码模块和内容自动编码模块分层连接;
2)提出了一种交叉注意融合模型,对融合后的异质表征进行注意权重分配;
3)在图卷积自动编码模块中,提出同时重构数据的内容和关系,有效地增强了 CaEGCN 的聚类性能;
CROSS-ATTENTION FUSION BASED ENHANCED GRAPH CONVOLUTIONAL NETWORK
整体框架如图:
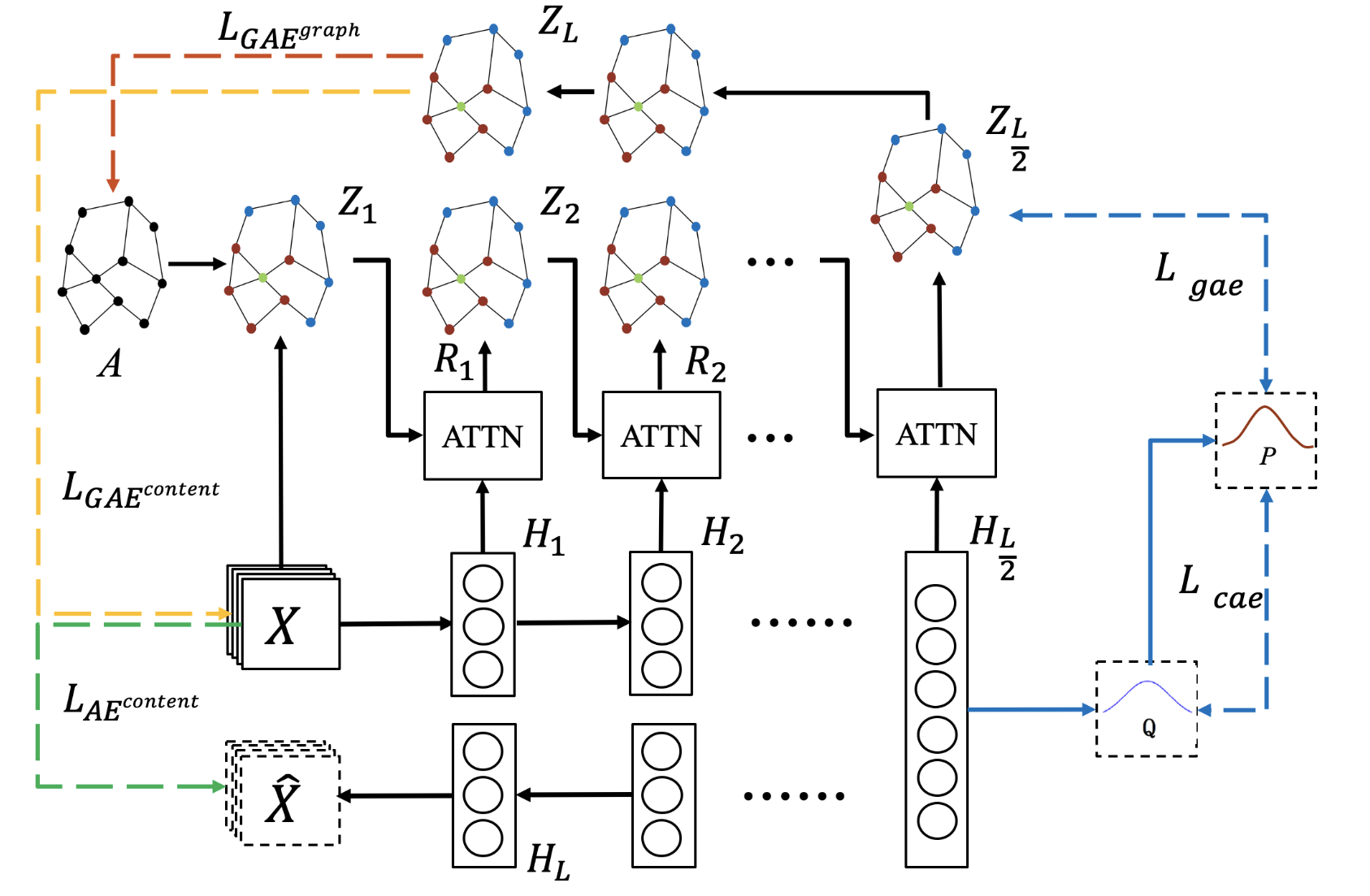
由四个主要模块组成:用于提取内容信息的自编码器模块;基于GCN的自编码器模块,用于利用数据之间的关系;交叉注意模块,用于连接上述两个模块,其中多级自适应融合策略在传输过程中尽可能补充有效的内容信息;以及用于约束中间层表示分布一致性的自监督模块。
A. Constructing the Graph
构造原始数据X的图采用方法与SDCN一样,KNN方法。
B. Content Auto-encoder Module (CAE)
采用基础的全连接层,损失采用重构损失,重构X。
C. Cross-Attention Fusion Module
利用交叉注意力融合机制以多级自适应的方式将CAE学习到的内容信息和GAE学习到的数据关系进行集成。
将交叉注意融合机制定义为:
R
=
F
a
t
t
(
Q
,
K
,
V
)
(1)
R=F_{att}(Q,K,V) \tag{1}
R=Fatt(Q,K,V)(1)
Q:query,K:key,V:value
交叉注意力融合模块的初始输入Y定义为:
Y
=
γ
Z
l
+
(
1
−
r
)
H
l
(2)
Y=\gamma Z_l + (1-r)H_l \tag{2}
Y=γZl+(1−r)Hl(2)
Z
l
,
H
l
Z_l,H_l
Zl,Hl分别为GAE与CAE第l层的输出。
γ
\gamma
γ是权衡参数,在本实验中设置为0.5。
注意力机制计算:首先计算融合query和融合key之间的相似度:
s
a
b
=
q
a
∗
k
b
(3)
s_{ab} = q_a * k_b \tag{3}
sab=qa∗kb(3)
然后在上述基础上进行softmax归一化获得
a
a
b
a_{ab}
aab:
a
a
b
=
s
o
f
t
m
a
x
(
s
a
b
)
=
e
x
p
(
s
a
b
)
∑
a
=
0
D
a
t
t
e
x
p
(
s
a
b
)
(4)
a_{ab} = softmax(s_{ab}) = \frac{exp(s_{ab})}{\sum^{D_{att}}_{a=0}exp(s_{ab})}\tag{4}
aab=softmax(sab)=∑a=0Dattexp(sab)exp(sab)(4)
交叉注意融合机制R最后获得的输出为:
r
a
=
∑
b
=
0
N
a
a
b
v
b
(5)
r_a = \sum^N_{b=0}a_{ab}v_b \tag{5}
ra=b=0∑Naabvb(5)
为了进一步感知数据的不同方面,引入了多头机制:
R
m
=
F
a
t
t
(
Q
m
,
K
m
,
V
m
)
,
m
=
1
,
2
,
3
,
.
.
.
,
M
.
(6)
R^m=F_{att}(Q_m,K_m,V_m) \tag{6},m=1,2,3,...,M.
Rm=Fatt(Qm,Km,Vm),m=1,2,3,...,M.(6)
其中
Q
m
=
W
m
q
Q
Q_m = W_m^qQ
Qm=WmqQ,K,V同理。
R
=
W
⋅
C
o
n
c
a
t
(
R
1
,
.
.
.
,
R
M
)
(7)
R = W\cdot Concat(R_1,...,R_M)\tag{7}
R=W⋅Concat(R1,...,RM)(7)
其中Concat(·)表示矩阵串联操作。这就是所谓的多头机制和交叉注意融合模块。
D. Graph Convolutional Auto-Encoder Module (GAE)
将前面的交叉注意力融合模块得到的输出表示R作为GAE的输入,进行谱图卷积。
Z
l
=
G
A
E
(
R
l
−
1
,
A
)
=
a
l
(
D
^
−
1
/
2
A
^
D
^
−
1
/
2
R
l
−
1
U
L
)
(8)
Z_l = GAE(R_{l-1},A)=a_l(\hat{D}^{-1/2}\hat{A}\hat{D}^{-1/2}R_{l-1}U_L )\tag{8}
Zl=GAE(Rl−1,A)=al(D^−1/2A^D^−1/2Rl−1UL)(8)
损失函数重构
A
~
=
S
i
g
m
o
d
i
(
Z
L
T
Z
L
)
\tilde{A} = Sigmodi(Z_L^TZ_L)
A~=Sigmodi(ZLTZL)和
X
~
=
Z
L
\tilde{X}=Z_L
X~=ZL。
E. Self-Supervised Module
前面的学习很难判断是否为聚类的最优表示,需要给出一个聚类的优化目标。
这里和诸如SDCN等前面众多方法一样采用Student’s t-distribution作为真实标签,其二次归一化作为目标标签。对CAE和GAE同时做优化。














 4443
4443











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









