







目录
2.6、LOSS、优化器、学习率衰减器及其他model辅助函数
2. 模型效果很差,rouge-l 训练集最高63%,验证集仅仅只有32%
3. 思考问题:使用focalloss 或者 普通的 softmax crossentropy 有什么问题?是否在softmax后使用 CRF 层?
一、数据
二、案例结构
2.1、数据分割获取train、val、test 类
import argparse
import pandas as pd
import numpy as np
np.random.seed(5)
import os
class FileHanlder():
"""
文件处理的类
"""
@staticmethod
def check_dir(path):
"""
检查创建目录
"""
if not os.path.exists(path):
os.makedirs(path)
@staticmethod
def get_father_dir(path):
"""
获得文件路径的父目录
:param path: 文件路径
:return: 父目录
"""
return os.path.dirname(path)
class CreateModelData():
"""
中文诗词是4句或6句、8句成诗。由于只需要训练模型生成一句诗,所以这里将每一句诗之间看作相互独立的,进行shfulle操作后分割为训练集与验证集(7:2:1)
"""
@staticmethod
def load_data(path):
"""加载、去重、去空、shuffle"""
lines = []
with open(path,'r',encoding='utf-8-sig') as r:
for line in r:
line = line.strip()
if line:
lines.append(line)
source_df = pd.DataFrame(lines,columns=['data'])
source_df = source_df.dropna(how='any')
shuffle_index = np.random.permutation(len(source_df))
source_df = source_df.iloc[shuffle_index,:]
return source_df
@staticmethod
def split_train_val_test_data(data_df):
size = len(data_df)
train_end = int(0.7 * size)
val_end = int(0.9 * size)
train_data = data_df.iloc[:train_end,:]
val_data = data_df.iloc[train_end:val_end,:]
test_data = data_df.iloc[val_end:,:]
return train_data,val_data,test_data
@staticmethod
def save_data(data_df,path):
"""保存为csv"""
data_df.to_csv(path,sep='\t',header=None,index=None)
@staticmethod
def forward(path):
source_df = CreateModelData.load_data(path=path)
train_data,val_data,test_data = CreateModelData.split_train_val_test_data(data_df=source_df)
# save
CreateModelData.save_data(train_data,'./data/train.data.tmp')
CreateModelData.save_data(val_data, './data/val.data.tmp')
CreateModelData.save_data(test_data, './data/test.data.tmp')2.2、数据预处理类【带target与没有target】
class ProcessDataWithTarget():
"""
模型 训练集、验证集、测试集 处理数据
"""
def load_data(self,path):
"""加载数据【dataframe个数"""
return pd.read_csv(path,sep='\t',header=None)
def load_stop_word(self):
"""这里不做停止词,保留标点符号"""
pass
def jieba_(self,text):
"""以每一个字作为分词"""
word_list = list(text)
return word_list
def save_data(self,data,path):
with open(path,'w',encoding='utf-8') as w:
for word_line in data:
line = ' '.join(word_line)
w.write(line)
w.write('\n')
def forward(self,source_path,report_path):
data_df = self.load_data(source_path)
datas = []
for line in data_df.iloc[:,-1]:
if line:
word_line = self.jieba_(line)
if word_line:
datas.append(word_line)
# save
self.save_data(data=datas,path=report_path)
return datas
class ProcessDataNoTarget(ProcessDataWithTarget):
"""
模型预测时处理数据,需要与 train、val、test 集处理方式完全相同【可以继承该类,然后方法进行重置】,只是没有target标签
"""
def __int__(self):
super(ProcessDataWithTarget,self).__init__()
def load_data(self,path):
pass
def forward(self,source_path):
pass2.3、创建vocab类与创建embedding表类
import collections
from collections import Counter
import numpy as np
import sys
class Vocab():
"""
构建 vocab表,id 与 one hot 的转化
"""
def build_vocab(self,train_data_path:str,val_data_path:str,save_path:str,most_common:int=None):
"""
1、使用 train data 和 val data 共同生成 vocab,添加标签 <PAD> <UNK>,使用过滤词,词频从高到低排序
① 低频词去除【保留前 most_common 个词】
"""
vocab_dict = {}
paths = [train_data_path,val_data_path]
for _path in paths:
with open(_path,'r',encoding='utf-8-sig') as f:
for line in f:
line = line.strip()
if line:
word_list = line.split() # .split() 默认使用任何空格进行分类
for word in word_list:
if word not in vocab_dict:
vocab_dict[word] = 1
else:
vocab_dict[word] = vocab_dict[word] + 1
# 取前 most_common 个词
if most_common is not None:
ordered_vocab = Counter(vocab_dict).most_common(most_common)
else:
ordered_vocab = Counter(vocab_dict).most_common(sys.maxsize)
# 建立 vocab2id 字典,并加入 <PAD> <UNK> 标签
vocab_dict = collections.OrderedDict()
vocab_dict["<PAD>"] = 0
vocab_dict["<UNK>"] = 1
for word,counts in ordered_vocab:
if word not in vocab_dict:
vocab_dict[word] = len(vocab_dict)
self.vocab = vocab_dict
# 保存 vocab_2_id
vocab_size = len(vocab_dict)
with open(save_path,'w',encoding = 'utf-8') as w:
for idx,(k,v) in enumerate(vocab_dict.items()):
w.write('{}\t{}'.format(k,v))
if idx + 1 < vocab_size:
w.write('\n')
return self.vocab
def load_vocab(self,file_path):
"""
加载 vocab_2_id【用于输入的vocab】
"""
vocab_dict = collections.OrderedDict()
with open(file_path, 'r', encoding='utf-8-sig') as f:
for line in f:
line = line.strip()
if line:
key, value = line.split()
vocab_dict[key] = int(value)
self.vocab = vocab_dict
return self.vocab
def text_encode_one_hot_ids(self,text,vocab_2_id,max_seq):
"""
将 2D text 通过 vocab2id 转化为 onehot 的id
通过 vocab 映射为 id
① 确定文本的最长长度,超过进行截取,不足的用 PAD 填充
② 由于vocab去除了低词频的词,所以也要用到 UNK 标签
return: numpy
"""
def padding(max_seq, X):
""" Pad 或 截取到相同长度,pad的值放在真实数据的前面 """
if len(X) < max_seq:
while len(X) < max_seq:
X.insert(0, vocab_2_id['<PAD>'])
else:
X = X[:max_seq]
return X
# text 必须是 2D 的
text = np.array(text)
assert text.ndim == 2
X = []
for line in text:
# mapping 为 id,注意 UNK 标签
line_tmp = [vocab_2_id[word] if word in vocab_2_id else vocab_2_id["<UNK>"] for word in line]
# padding 或 截取 为 固定长度,pad的值放在真实数据的前面
line = padding(max_seq=max_seq, X=line_tmp)
# 保存 X
X.append(line)
return np.array(X)
def ids_decode_text(self,id_array,vocab_dict):
"""
给定 id array,通过 vocab 获得 text
:param id_array: ndarray 类型
:param vocab_dict: OrderedDict 类型
:return:
"""
assert isinstance(vocab_dict,dict)
id_array = np.array(id_array)
vocab_array = np.array(list(vocab_dict.keys()))
return vocab_array[id_array]
class EmbeddingTable():
"""
embedding table 相关,本案例不使用预训练静态词向量
"""
def build_embedding(self):
"""创建预训练静态词向量,并保存"""
pass
def load_embedding(self):
pass
if __name__ == '__main__':
from data_process import FileHanlder
from loader_utils import LoadTextData,Data_Set,collate_fn
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--most_common', default=None, type=int, help='model input vocab most common number')
parser.add_argument('--max_seq', default=15, type=int, help='model input max seq len')
parser.add_argument('--train_data', default='./data/train.txt', type=str, help='model train data path')
parser.add_argument('--val_data', default='./data/val.txt', type=str, help='model val data path')
parser.add_argument('--test_data', default='./data/test.txt', type=str, help='model test data path')
parser.add_argument('--vocab', default='./word2vec/vocab.txt', type=str, help='model input vocab file')
args = parser.parse_args()
# 创建目录
FileHanlder.check_dir(FileHanlder.get_father_dir(args.vocab))
# 创建 vocab 与 embedding 表
print('building vocab ... ')
vocab_obj = Vocab()
vocab = vocab_obj.build_vocab(train_data_path=args.train_data,
val_data_path=args.val_data,
save_path=args.vocab,
most_common=args.most_common)
print('finish !!!!!!')
print('测试 ....')
train_X,train_target = LoadTextData.load_text_with_target(args.train_data)
train_X = vocab_obj.text_encode_one_hot_ids(train_X, vocab, args.max_seq)
train_target = vocab_obj.text_encode_one_hot_ids(train_target, vocab, args.max_seq)
print('train data id:')
print(train_X[:3])
print(train_target[:3])
print('train data text:')
text_X = vocab_obj.ids_decode_text(train_X,vocab)
text_target = vocab_obj.ids_decode_text(train_target, vocab)
print(text_X[:3])
print(text_target[:3])2.4、Dataset、Dataloader
import torch
from torch.utils.data import Dataset
class LoadTextData():
"""
从文件中加载数据
"""
@staticmethod
def load_text_with_target(path):
"""
用于 train、val、test 加载
:return: X:list ,target:list
"""
X = []
target = []
with open(path,'r',encoding='utf-8-sig') as f:
for line in f:
line = line.strip()
if line:
line_word = line.split()
line_target = line_word[1:]
line_target.append(line_word[0])
X.append(line_word)
target.append(line_target)
return X,target
@staticmethod
def load_text_no_target(path):
"""
模型 predict 没有 target 加载文件
:param path:
:return:
"""
pass
class Data_Set(Dataset):
def __init__(self, X, Label=None):
"""
X: 2D numpy int64
Label: 2D numpy int64
"""
self.X = X
self.Label = Label
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
if self.Label is not None:
X = torch.tensor(self.X[idx], dtype=torch.int64) # 使用torch默认的整形数据
Label = torch.tensor(self.Label[idx], dtype=torch.int64)
return X, Label
# 考虑predict阶段没有label
else:
X = torch.tensor(self.X[idx], dtype=torch.int64)
return X
def collate_fn(batch):
"""
参数:batch 是 多组 Dataset __getitem__ 的 return值,list 类型
DataLoader 中定义的 collate_fn 函数,用于对一个batch的数据进行处理
② 将 batch 数据转化为tensor
① 去除一个batch中多余的 PAD ,将数据最长长度调整为batch中最长样本的真实长度
"""
def intercept(X):
"""
X dim: [batch,T]
将tensor截取为真实值的最长度,要注意PAD必须为0才可执行
"""
max_seq = torch.max(torch.sum(X >= 1, dim=1))
return X[:, -max_seq:]
X_list = []
label_list = []
for item in batch:
if isinstance(item, tuple):
X, target_label = item # X dim: [batch,T]
if not (torch.is_tensor(X) and torch.is_tensor(target_label)):
X = torch.tensor(X)
target_label = torch.tensor(target_label)
X_list.append(X)
label_list.append(target_label)
# 考虑到预测没有标签
else:
X = item
if not torch.is_tensor(X):
X = torch.tensor(X)
X_list.append(X)
if label_list:
X = torch.stack(X_list, dim=0) # X dim: [batch,T]
label = torch.stack(label_list, dim=0)
return intercept(X), intercept(label)
else:
X = torch.stack(X_list, dim=0) # X dim: [batch,T]
return intercept(X)
if __name__ == '__main__':
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--train_data', default='./data/train.txt', type=str, help='model train data path')
parser.add_argument('--val_data', default='./data/val.txt', type=str, help='model val data path')
parser.add_argument('--test_data', default='./data/test.txt', type=str, help='model test data path')
args = parser.parse_args()
# 加载数据
train_X,train_target = LoadTextData.load_text_with_target(args.train_data)
# print(train_X[:3])
# print(train_target[:3])2.5、模型搭建
import torch
import torch.nn as nn
import torch.nn.functional as F
class LSTM_Model(nn.Module):
def __init__(self,
vocab_size,
embedding_dim,
n_class,
hidden_dim,
num_layers,
dropout,
bidirectional = False, # 生成模型不能用双向,置False
embedding_weights=None, # 预训练静态词向量 embedding
train_w2v=True, # embedding层 是否参与训练
**kwargs):
super(LSTM_Model, self).__init__()
self.vocab_size = vocab_size
self.embedding_dim = embedding_dim
self.n_class = n_class
self.hidden_dim = hidden_dim
self.num_layers = num_layers
self.dropout = dropout
self.bidirectional = bidirectional
self.embedding_weights = embedding_weights
self.train_w2v = train_w2v
# 构建 embedding 层
if self.embedding_weights is not None:
self.embedding_weights = torch.tensor(self.embedding_weights,
dtype=torch.float32) # torch 不接受 numpy 64位的浮点型,这里必须转化为32位,否则报错
self.embedding = nn.Embedding.from_pretrained(self.embedding_weights)
self.embedding.weight.requires_grad = self.train_w2v
else: # 保证预测的情况无需传入 预训练的embedding表
self.embedding = nn.Embedding(self.vocab_size, self.embedding_dim)
self.embedding.weight.requires_grad = self.train_w2v
nn.init.uniform_(self.embedding.weight, -1., 1.)
# 构建 lstm
self.lstm = nn.LSTM(input_size=self.embedding_dim,
hidden_size=self.hidden_dim,
num_layers=self.num_layers,
dropout=self.dropout,
bidirectional=self.bidirectional)
# Fc
self.fc1 = nn.Linear(self.hidden_dim,int(1/4 * self.n_class))
self.fc2 = nn.Linear(int(1/4 * self.n_class),self.n_class)
def forward(self, x,hidden_states=None):
# 0、embedding
embeddings = self.embedding(x) # (B,T) --> (B,T,D)
# 1、LSTM
# lstm 默认 输入维度为 (seq,batch,dim),因此这里需要用permute进行转换
# lstm hx递归状态 默认是用0初始化的【hidden_states==None时,使用0初始化】
outputs, states = self.lstm(embeddings.permute([1, 0, 2]),hidden_states)
# FC
outputs = outputs.permute([1,0,2]) # 将 (T,B,D) ----> (B,T,D)
outputs = F.relu(self.fc1(outputs))
outputs = self.fc2(outputs) # (B,T,n_class)
outputs = outputs.reshape((-1,self.n_class)) # (B*T,n_class)
return outputs,states
if __name__ == '__main__':
pass2.6、LOSS、优化器、学习率衰减器及其他model辅助函数
# 模型相关工具代码
import torch
import math
import torch.nn.functional as F
import numpy as np
from sklearn.metrics import confusion_matrix,f1_score,precision_score,recall_score,accuracy_score
def get_device():
dev = 'cuda:0' if torch.cuda.is_available() else 'cpu'
device = torch.device(dev)
return device
def focal_loss(output, target, alpha=1.0, gamma=2.0, *args, **kwargs):
"""
********** 给定模型前向传播的输出[batch,class]与真实值target[class,],计算loss误差 ************
1. 仅仅在训练的时候使用 focal_loss ,验证时不使用 focal_loss
2. 默认情况下不进行聚合
"""
assert np.ndim(output) == 2
assert np.ndim(target) == 1
assert len(output) == len(target)
ce_loss = F.cross_entropy(input=output, target=target, reduction="none") # 这里必须使用 none 模式, ce_loss dim: [B,]
pt = torch.exp(-ce_loss) # pt dim: [B,]
# 构建 focal_loss
focalloss = (alpha * (torch.tensor(1.0) - pt) ** gamma * ce_loss).mean()
return focalloss
def cross_entropy(output, target, *args, **kwargs):
"""
普通的交叉熵损失函数,默认情况下不进行聚合
"""
assert np.ndim(output) == 2
assert np.ndim(target) == 1
assert len(output) == len(target)
ce_loss = F.cross_entropy(input=output, target=target, reduction="mean") # ce_loss 是一个均值
return ce_loss
def view_will_trained_params(model,model_name):
"""
********** 查看模型哪些层的参数参与训练,哪些层的参数被固定了 ************
"""
train_params = []
for name,param in model.named_parameters():
if param.requires_grad == True:
train_params.append((name,param.shape))
print("\n{} 模型将要参与训练的层为:\n".format(model_name),train_params,end='\n\n\n')
def get_score(target,predict):
"""
给定真实的变迁target 与 预测的标签predict ,计算 acc、recall、precision、F1
"""
import warnings
warnings.filterwarnings('ignore')
assert np.ndim(target) == 1
assert np.ndim(predict) == 1
assert np.shape(target) == np.shape(predict)
con_matrix = confusion_matrix(y_true=target,y_pred=predict)
# 计算acc
acc = accuracy_score(y_true=target,y_pred=predict)
# 计算 macro recall
recall = recall_score(y_true=target,y_pred=predict,average='macro')
# 计算 macro precision
precision = precision_score(y_true=target,y_pred=predict,average='macro')
# 计算 macro F1
F1 = f1_score(y_true=target,y_pred=predict,average='macro')
return (acc,recall,precision,F1),con_matrix
class RougeScore():
'''
计算 rouge-l f1 分值,通过调节beta大小,控制 recall 在f1中的比重
'''
def __init__(self,beta = 1.2):
# rouge-l beta 值定义
self.beta = beta # self.beat 越大,F1值越接近 recall,当 self.beta 很大时,rouge-l 值约等于recall值
def _my_lcs(self,string, sub):
"""
dp 算法计算 LCS
:param string: 1D iter:len >=1
:param sub: 1D iter:len >=1
:return: int
"""
if (len(string) < len(sub)):
sub, string = string, sub
# init dp map
lengths = [[0 for i in range(0, len(sub) + 1)] for j in range(0, len(string) + 1)]
for j in range(1, len(sub) + 1):
for i in range(1, len(string) + 1):
if (string[i - 1] == sub[j - 1]):
lengths[i][j] = lengths[i - 1][j - 1] + 1
else:
lengths[i][j] = max(lengths[i - 1][j], lengths[i][j - 1])
return lengths[len(string)][len(sub)]
def calc_score(self, candidate, refs):
"""
计算 candidate 与 reference Rouge - l score
:param candidate: candidate : iter : len>=1
:param refs: refs : iter : len>=1
:return:
"""
assert len(candidate) >= 1
assert len(refs) >= 1
lcs = self._my_lcs(string=refs,sub=candidate)
precision_ = (lcs + 1e-12) / len(candidate)
recall_ = (lcs + 1e-12) / len(refs)
score = ((1 + self.beta ** 2) * precision_ * recall_) / float(recall_ + self.beta ** 2 * precision_)
return score
def batch_rouge_l(self, candidates, references):
"""
计算一个 batch 的 均值 mean
:param candidates: 2D(batch,T)
:param references: 2D(batch,T)
:return: mean rouge-l score & list of scores
"""
assert np.shape(candidates) == np.shape(candidates)
assert np.ndim(candidates) == 2
assert np.ndim(references) == 2
scores = []
for idx in range(len(candidates)):
_score = self.calc_score(candidate=candidates[idx],refs=references[idx])
scores.append(_score)
scores = np.array(scores)
return np.mean(scores),scores
class WarmupCosineLR():
def __init__(self, optimizer, warmup_iter: int, lrs_min:tuple = (1e-5, ), T_max: int = 10):
"""
******************* pytorch自定义学习率 预热warmup + Cosline 余弦衰减 **************************
具体可看文章:https://blog.csdn.net/qq_36560894/article/details/114004799?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-13.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-13.control
Args:
optimizer (Optimizer): pytotch 优化器
warmup_iter: 预热的最大epoch
lrs_min: list, optimizer 学习率一一对应的最小值
T_max:余弦半周期,该值必须比 warmup_iter 大
特点:
① 支持分层学习率多组学习率衰减
"""
self.optimizer = optimizer
self.warmup_iter = warmup_iter
self.lrs_min = lrs_min
self.T_max = T_max
self.base_lrs = [i['lr'] for i in optimizer.param_groups]
def get_lr(self):
if self.iter < self.warmup_iter:
return [i * self.iter * 1. / self.warmup_iter for i in self.base_lrs]
else:
return [self.lrs_min[idx] + 0.5 * (i - self.lrs_min[idx]) * (
1.0 + math.cos((self.iter - self.warmup_iter) / (self.T_max - self.warmup_iter) * math.pi)) \
for idx, i in enumerate(self.base_lrs)]
def step(self, iter: int):
if iter == 0:
iter = iter + 1
self.iter = iter
# 获取当前epoch学习率
decay_lrs = self.get_lr()
# 更新学习率
for param_group, lr in zip(self.optimizer.param_groups, decay_lrs):
param_group['lr'] = lr
if __name__ == '__main__':
pass2.7、Train & eval
import torch
import argparse
from data_process import FileHanlder
from word2vec import Vocab,EmbeddingTable
from loader_utils import Data_Set,collate_fn,LoadTextData
from model_utils import get_device,WarmupCosineLR,view_will_trained_params,cross_entropy,focal_loss,get_score,RougeScore
from torch.utils.data import DataLoader
from model import LSTM_Model
import torch.optim as optim
import copy
import numpy as np
import os
def train_one_epoch(model, device, optimizer, loss_fun, metric_fun,clip_gradient, train_loader, current_epoch,
info_interval: int = None):
"""
********** 一个epoch模型训练 ************
关于 model.eval() model.train() with torch.no_grad() with torch.set_grad_enabled(bool) 区别
return:
① batch_losses:每个step均值loss列表
② 整个epoch 每个 step 的 rouge_l
"""
print('Training ... ')
model.train()
model.to(device)
LRs = [i['lr'] for i in optimizer.param_groups] # 获取当前epoch 优化器 optimizer 学习率组
batch_losses = []
# 存储所有的epoch的 target 与 predict,用于计算score
steps_rouge_l = []
for idx, (input_x, target) in enumerate(train_loader):
input_x, target = input_x.to(device), target.to(device)
target = target.reshape(-1) # 将(B,T) ---> ( B*T,)
optimizer.zero_grad()
output,_ = model(input_x,hidden_states=None) # 前向传播
loss = loss_fun(output, target, alpha=1.0, gamma=2.0)
loss.backward() # 反向传播计算梯度
# TODO 梯度截断
torch.nn.utils.clip_grad_norm_(filter(lambda p: p.requires_grad,model.parameters()),max_norm=clip_gradient)
optimizer.step() # 更新
batch_losses.append(loss.item())
# 计算rouge-l f1 分值
target = target.reshape(input_x.shape) # (B*T) ---> (B,T)
pre = torch.argmax(output, dim=1) # (B,T)
pre = pre.reshape(input_x.shape) # (B*T,) ---> (B,T)
pre = pre.cpu().numpy().tolist()
target = target.cpu().numpy().tolist()
mean_rouge_l, rouge_ls = metric_fun.batch_rouge_l(candidates=pre, references=target)
steps_rouge_l.append(mean_rouge_l)
if info_interval is not None:
if idx % info_interval == 0:
print("Epoch:{}\t[{}\{}\t\t{:.2f}%]\tLoss:{:.8f}\tScores: < mean rouge-l:{:.3f}%\t" \
" >\t\tBatch input_x shape:{}".format(
current_epoch, idx * len(input_x),
len(train_loader.dataset), 100. * (idx / len(train_loader)), loss.item(),100.* mean_rouge_l, input_x.shape))
# 计算一个epoch的score
print("Epoch Info :\tLoss:{:.8f}\tScores: <\tmean rouge-l:{:.3f}%" \
"\t>\tLRs:{}".format(
np.mean(batch_losses),100.* np.mean(steps_rouge_l), LRs
))
return batch_losses, np.mean(steps_rouge_l)
def eval_one_epoch(model, device, loss_fun, metric_fun, eval_loader):
"""
********** 一个epoch模型验证 ************
关于 model.eval() model.train() with torch.no_grad() with torch.set_grad_enabled(bool) 区别
return: batch_losses 每个batch均值loss列表,batch_scores 每个batch的 acc,recall,precision,F1
"""
print('Evaling ... ')
model.eval() # 开启与dropout、BN层,它不会阻止梯度的计算,只不过回传参数,因此,eval 模式使用 with torch.no_grad() 还是很有必要的,加快计算速度。
model.to(device)
batch_losses = []
steps_rouge_l = []
with torch.no_grad():
for idx, (input_x, target) in enumerate(eval_loader):
input_x, target = input_x.to(device), target.to(device)
target = target.reshape(-1) # 将(B,T) ---> ( B*T,)
output,_ = model(input_x,hidden_states=None) # 前向传播
loss = loss_fun(output, target, alpha=1.0, gamma=2.0)
batch_losses.append(loss.item())
# 计算rouge-l f1 分值
target = target.reshape(input_x.shape) # (B*T) ---> (B,T)
pre = torch.argmax(output, dim=1) # (B,T)
pre = pre.reshape(input_x.shape) # (B*T,) ---> (B,T)
pre = pre.cpu().numpy().tolist()
target = target.cpu().numpy().tolist()
mean_rouge_l, rouge_ls = metric_fun.batch_rouge_l(candidates=pre, references=target)
steps_rouge_l.append(mean_rouge_l)
# 计算一个epoch的score
print("Epoch Info :\tLoss:{:.8f}\tScores: <\tmean rouge-l:{:.3f}%" \
"\t>".format(
np.mean(batch_losses), 100.* np.mean(steps_rouge_l)
))
return batch_losses, np.mean(steps_rouge_l)
def train(model, device, optimizer, scheduler_fun, loss_fun, epochs, metric_fun,clip_gradient, info_interval, checkpoint,
train_loader, eval_loader):
"""
********** 模型训练 ************
return:
① train_losses,eval_losses: 2D list ,(epoch,step)
② train_scores,eval_scores: 1D list,(epoch,)
"""
# 判断加载已保留的最优的模型参数【支持断点续传】
best_scores = -0.000001 # 定义初始的 rouge-l F1的值
history_epoch, best_epoch = 0, 0 # 定义历史训练模型epoch次数初始值、最优模型的epoch初始值
best_params = copy.deepcopy(model.state_dict()) # 获取模型的最佳参数,OrderDict属于链表,对其更该引用的变量也会变动,因此这里要用到深拷贝
best_optimizer = copy.deepcopy(optimizer.state_dict())
LRs = [i['lr'] for i in optimizer.param_groups]
if os.path.exists(checkpoint):
"""
为了保证 gpu/cpu 训练的模型参数可以相互加载,这里在load时使用 map_location=lambda storage, loc: storage 来控制,详情请看文章:
https://blog.csdn.net/nospeakmoreact/article/details/89634039?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.withoutpai&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.withoutpai
"""
if torch.cuda.is_available():
ck_dict = torch.load(checkpoint, map_location=lambda storage, loc: storage.cuda()) # 使用 gpu 读取 模型参数
else:
ck_dict = torch.load(checkpoint, map_location=lambda storage, loc: storage) # 使用 cpu 读取模型参数
best_scores = ck_dict['best_score']
history_epoch, best_epoch = ck_dict['epochs'], ck_dict['best_epochs']
model.load_state_dict(ck_dict['best_params'])
optimizer.load_state_dict(ck_dict['optimizer'])
if torch.cuda.is_available():
"""
重载optimizer的参数时将所有的tensor都放到cuda上(optimizer保存时默认放在cpu上了),详情见:
https://blog.csdn.net/weixin_41848012/article/details/105675735
"""
for state in optimizer.state.values():
for k, v in state.items():
if torch.is_tensor(v):
state[k] = v.cuda()
best_params = copy.deepcopy(model.state_dict()) # 获取模型的最佳参数,OrderDict属于链表,对其更该引用的变量也会变动,因此这里要用到深拷贝
best_optimizer = copy.deepcopy(optimizer.state_dict())
LRs = [i['lr'] for i in optimizer.param_groups]
print('From "{}" load history model params:\n\tTrained Epochs:{}\n\t' \
'Best Model Epoch:{}\n\t各层学习率 LRs 为:{}\n\tBest Score:<\tmean rouge-l:{:.3f}%\t>\n'.format(
checkpoint, history_epoch, best_epoch, LRs, best_scores))
# print(best_params)
# print(best_optimizer)
# Train
train_losses = []
eval_losses = []
train_scores = []
eval_scores = []
for epoch in range(1, epochs + 1):
# 获得本次训练的 lr 学习率
scheduler_fun.step(history_epoch + epoch) # 这里需要使用历史的epoch,为了是LR变化符合 Warmup + cosine
LRs = [i['lr'] for i in optimizer.param_groups]
# train & eval
train_batch_loss, train_score = train_one_epoch(model=model,
device=device,
optimizer=optimizer,
loss_fun=loss_fun,
metric_fun=metric_fun,
clip_gradient=clip_gradient,
train_loader=train_loader,
current_epoch=history_epoch + epoch,
info_interval=info_interval)
print()
eval_batch_loss, eval_score = eval_one_epoch(model=model,
device=device,
loss_fun=loss_fun,
metric_fun=metric_fun,
eval_loader=eval_loader)
train_losses.append(train_batch_loss)
eval_losses.append(eval_batch_loss)
train_scores.append(train_score)
eval_scores.append(eval_score)
# 保存模型[当验证集的 F1 值 大于最优F1时,模型进行保存
if best_scores < eval_score:
print('历史模型分值:{:.3f}%,更新分值{:.3f}%,优化器学习率:{},模型参数更新保存\n'.format(100. * best_scores, 100. * eval_score,
LRs))
best_scores = eval_score
best_params = copy.deepcopy(model.state_dict())
best_optimizer = copy.deepcopy(optimizer.state_dict())
best_epoch = history_epoch + epoch
else:
print("模型最优的epcoh为:{},模型验证集最高分值:{:.3f}%, model 效果未提升\n".format(best_epoch, 100. * best_scores))
ck_dict = {
"best_score": best_scores,
"best_params": best_params,
"optimizer": best_optimizer,
'epochs': history_epoch + epoch,
'best_epochs': best_epoch
}
torch.save(ck_dict, checkpoint)
# 训练结束,将模型赋予最优的参数
model.load_state_dict(best_params)
return model, train_losses, eval_losses, train_scores, eval_scores
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--max_seq', default=12, type=int, help='model input max seq len')
parser.add_argument('--clip_grad', default=5, type=int, help='clip gradient')
parser.add_argument('--lr', default=0.001, type=float, help='model learning rate')
parser.add_argument('--min_lr', default=8e-5, type=float, help='model lr scheduler min learning rate')
parser.add_argument('--embedding_dim', default=64, type=int, help='word embedding dim')
parser.add_argument('--hidden_dim', default=128, type=int, help='lstm hidden dim')
parser.add_argument('--num_layer', default=2, type=int, help='lstm layer number')
parser.add_argument('--epochs', default=350, type=int, help='train total epochs')
parser.add_argument('--batch_size', default=48, type=int, help='train batch size')
parser.add_argument('--dropout', default=0.2, type=float, help='drop out keep prob = 1 - dropout ')
parser.add_argument('--train_w2v', default=1, type=int, help='whether train word embedding layer,1 :True 0:False')
parser.add_argument('--focal_loss', default=1, type=int, help='use focal loss or cross entropy,1 :focal 0:cross entropy')
parser.add_argument('--num_workers', default=4, type=int, help='multi preprocess number')
parser.add_argument('--info_interval', default=160, type=int, help='every number of batch print log')
parser.add_argument('--model_name', default='lstm', type=str, help='model name: "lstm" ')
parser.add_argument('--train_data', default='./data/train.txt', type=str, help='model train data path')
parser.add_argument('--val_data', default='./data/val.txt', type=str, help='model val data path')
parser.add_argument('--test_data', default='./data/test.txt', type=str, help='model test data path')
parser.add_argument('--vocab', default='./word2vec/vocab.txt', type=str, help='model input vocab file')
parser.add_argument('--checkpoint', default='./checkpoint/lstm.ckpt', type=str, help='model validation best checkpoint dict')
args = parser.parse_args()
# 创建目录
FileHanlder.check_dir(FileHanlder.get_father_dir(args.checkpoint))
# 获取 device
device = get_device() # cuda:0 / cpu
# 数据加载
train_X,train_target = LoadTextData.load_text_with_target(args.train_data)
val_X,val_target = LoadTextData.load_text_with_target(args.val_data)
# vocab,embedding table 加载
vocab_obj = Vocab()
vocab_2_id = vocab_obj.load_vocab(args.vocab)
train_X = vocab_obj.text_encode_one_hot_ids(text=train_X,vocab_2_id=vocab_2_id,max_seq=args.max_seq) # text 编码为 id
train_target = vocab_obj.text_encode_one_hot_ids(text=train_target, vocab_2_id=vocab_2_id, max_seq=args.max_seq)
val_X = vocab_obj.text_encode_one_hot_ids(text=val_X, vocab_2_id=vocab_2_id, max_seq=args.max_seq)
val_target = vocab_obj.text_encode_one_hot_ids(text=val_target, vocab_2_id=vocab_2_id, max_seq=args.max_seq)
# DataSet DataLoader
kwargs = {'num_workers': args.num_workers, 'pin_memory': True} if torch.cuda.is_available() else {
'num_workers': args.num_workers}
train_dataset = Data_Set(train_X, train_target)
val_dataset = Data_Set(val_X,val_target)
train_loader = DataLoader(dataset=train_dataset,
batch_size=args.batch_size,
shuffle=True,
collate_fn=collate_fn,
**kwargs
)
val_loader = DataLoader(dataset=val_dataset,
batch_size=args.batch_size,
shuffle=False,
collate_fn=collate_fn,
**kwargs
)
print('train loader 第一个batch的情况如下:')
print(next(iter(train_loader)), next(iter(train_loader))[0].shape)
# 模型搭建
if args.model_name == 'lstm':
model = LSTM_Model(vocab_size=len(vocab_2_id),
embedding_dim= args.embedding_dim,
n_class = len(vocab_2_id),
hidden_dim = args.hidden_dim ,
num_layers = args.num_layer,
dropout = args.dropout,
bidirectional = False, # 生成模型不能用 None
embedding_weights=None, # 预训练静态词向量 embedding
train_w2v=True if args.train_w2v else False
)
else:
raise Exception('model name error !!!')
# 打印模型训练参数
print('Model-"{}" 细节:\n'.format(args.model_name), model)
view_will_trained_params(model, model_name=args.model_name)
# LOSS、优化器、学习率衰减器
if args.focal_loss:
loss_fun = focal_loss
else:
loss_fun = cross_entropy
# 定义优化器
optimizer = optim.Adam(filter(lambda p:p.requires_grad,model.parameters()),lr=args.lr)
# 学习率衰减器
scheduler_func = WarmupCosineLR(optimizer=optimizer,warmup_iter=4,lrs_min=(args.min_lr,),T_max=30)
# train & eval
rouge_l = RougeScore(beta=1.2)
train(model=model,
device=device,
optimizer = optimizer,
scheduler_fun=scheduler_func,
loss_fun=loss_fun,
epochs=args.epochs,
metric_fun = rouge_l,
clip_gradient= args.clip_grad,
info_interval = args.info_interval,
checkpoint = args.checkpoint,
train_loader = train_loader,
eval_loader = val_loader)三、遇到的问题
1. 是否使用focal loss作为损失函数
使用,因为存在数据不均衡的问题2. 模型效果很差,rouge-l 训练集最高63%,验证集仅仅只有32%
原因:直接使用softmax层输出没有考虑序列中每一个时刻之间的联系
解决方法:在softmax层后加入crf层3. 思考问题:使用focalloss 或者 普通的 softmax crossentropy 有什么问题?是否在softmax后使用 CRF 层?
我们最后将target [batch,T] ----> [batch * T] 与 logits [B * T, n_class] 做softmax 忽略了同一个样本中每
一个时刻T与其他时刻的关系,softmax过程将他们作为独立单位处理,这显然是不切实际的
例如:在做NER的时候,我们都知道 B-persion 后是不可能接 B-,但是仅仅用softmax的CE损失就可能出现这种情况,而加入
了crf会对这些无效的标签进行约束,大大减少了无效标签的数量。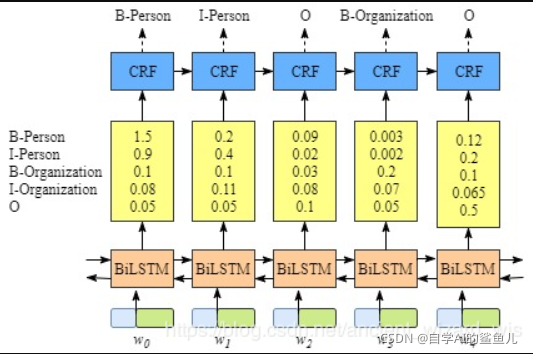















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









