







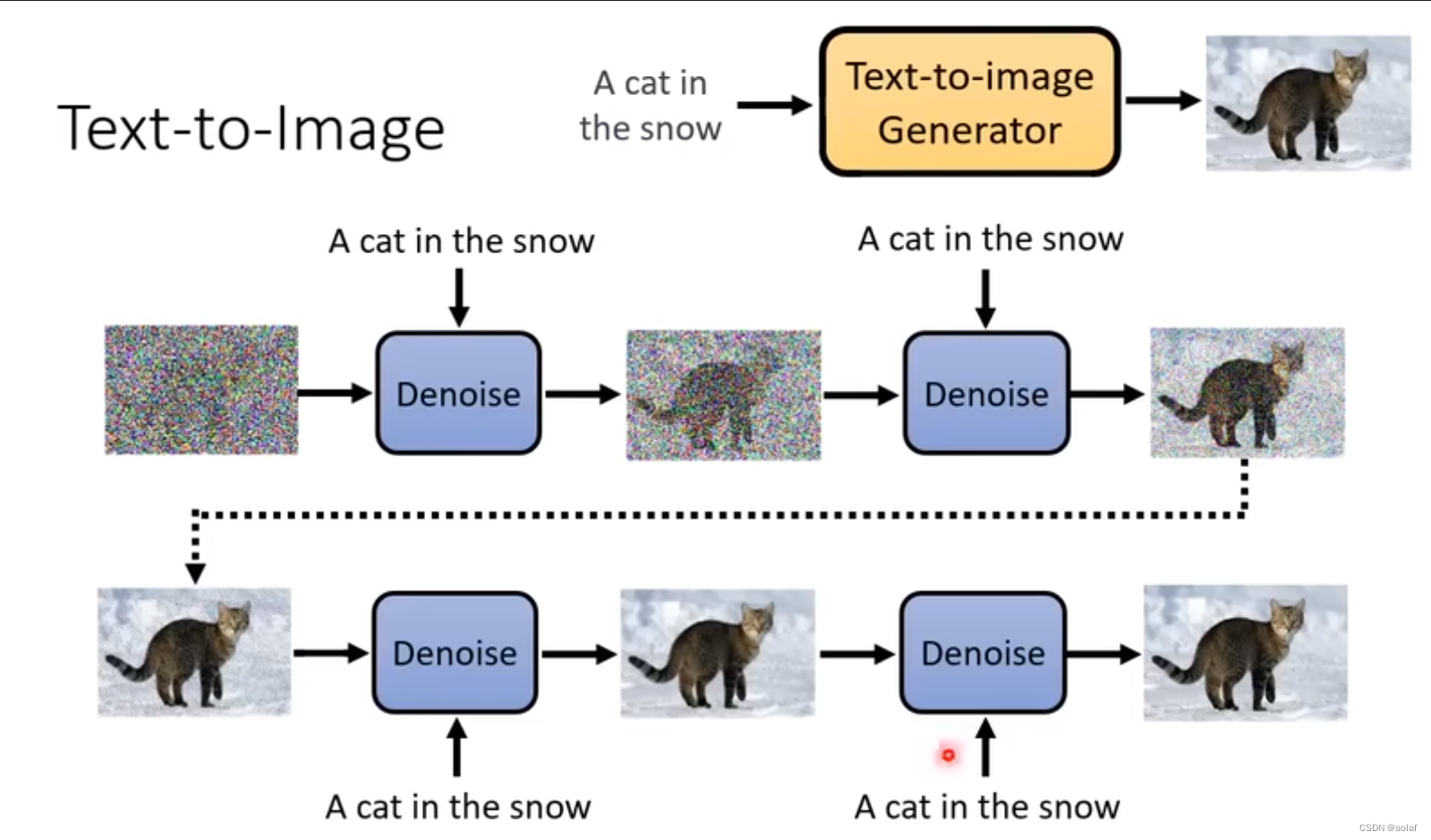
1 Diffusion Model的运作过程
输入一张和我们所需结果图尺寸一致的噪声图像,通过Denoise模块逐步减少noise,最终生成我们需要的效果图。
图中Denoise模块虽然是同一个,但是它会根据不同step的输入图像和代表noise严重程度的参数选择denoise的程度。
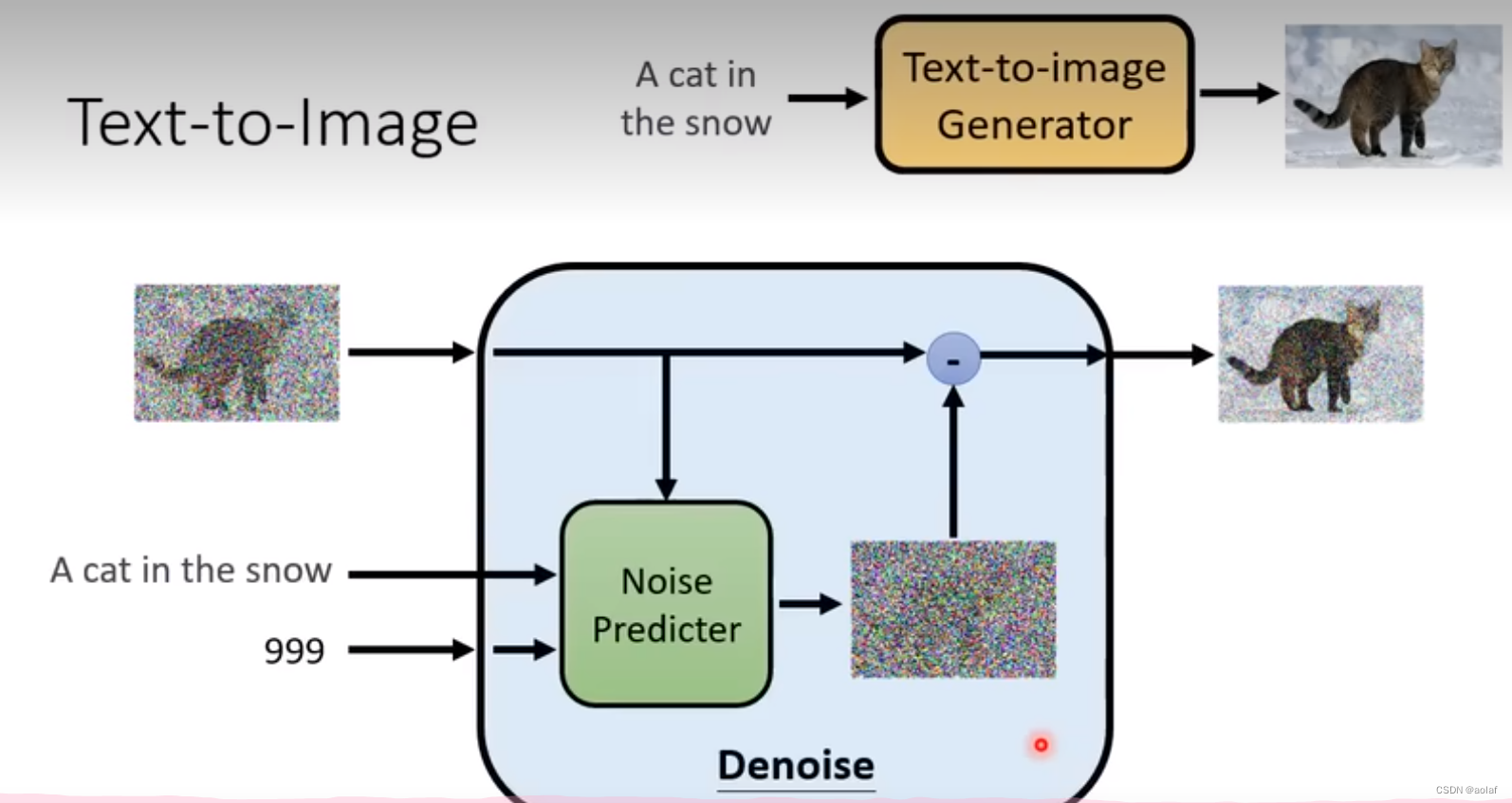
1.1 Denoise 模块的内部过程
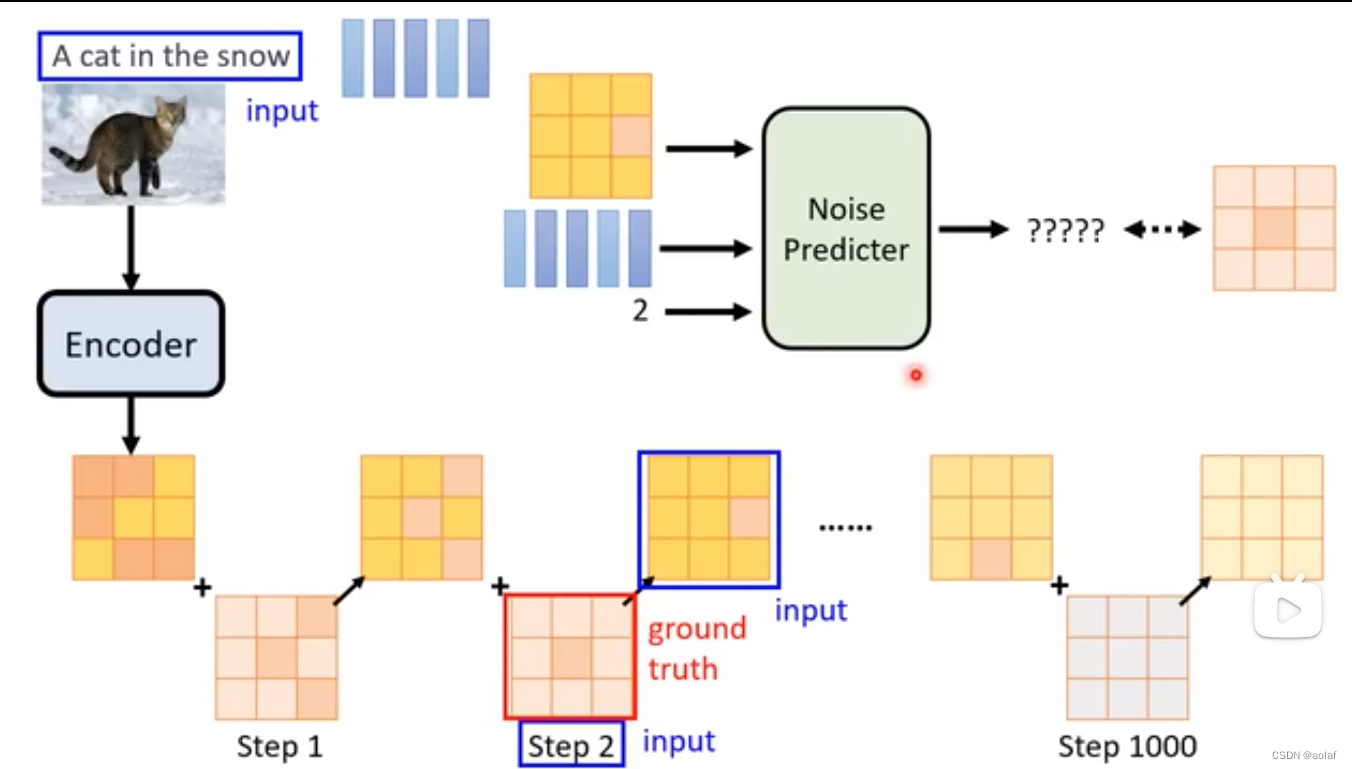
根据我们输入带噪声的图像和去噪程度的参数,Denoise模块中的Noise pred模块会预测出图中的noise部分,此时输入图像和预测噪声的差即为该step的输出结果。
问:为何选择预测噪声做差而不是直接预测消除部分噪声后的图像?
由于预测噪声的难度更低,如果直接预测带噪声后的图像其实就已经相当于可以实现图像的生成了。
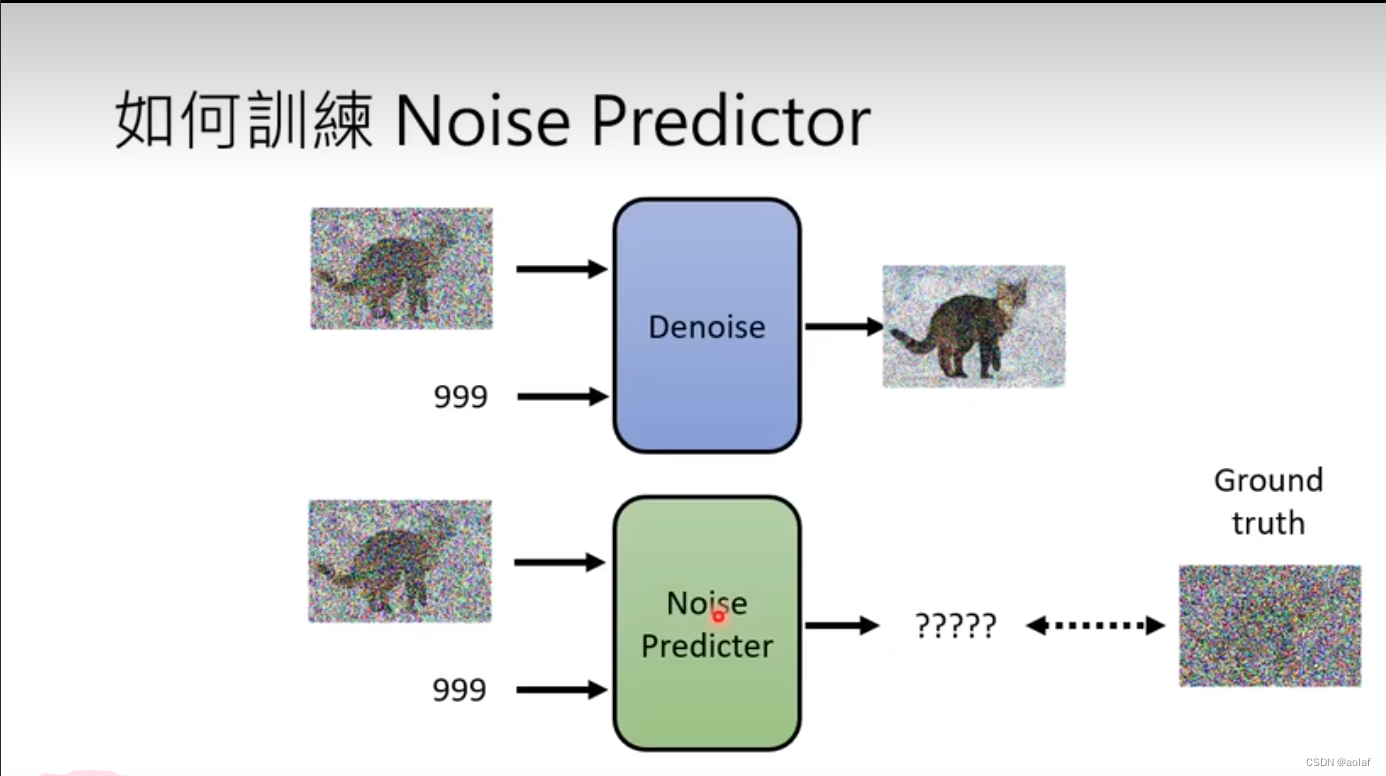
1.2 如何训练Noise_predictor
想要训练Noise_predictor预测出来噪声,我们需要提供噪声的Ground truth,这个如何获得?
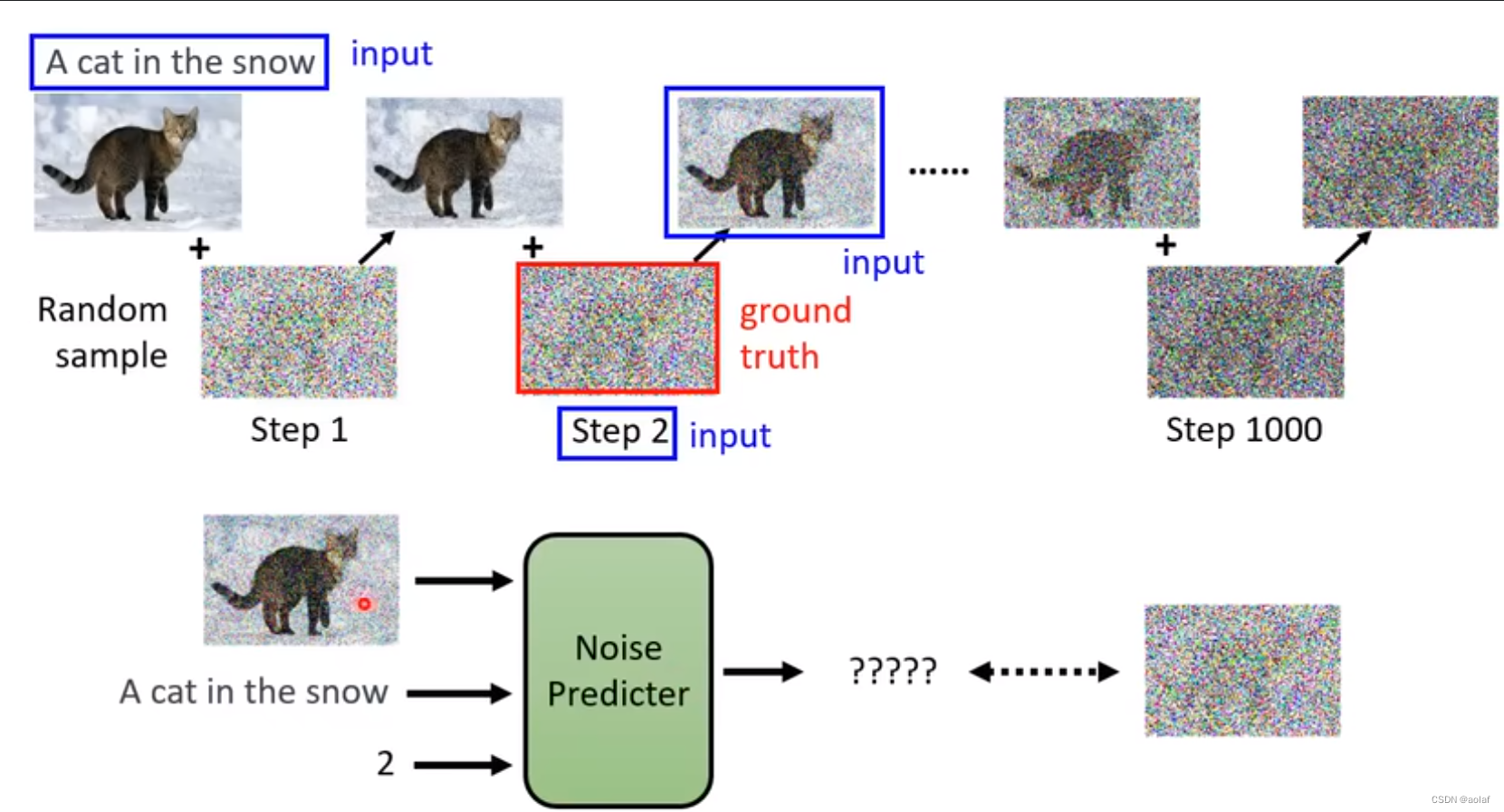
我们从训练数据集中随机抽取一张图像,然后人为给其加噪声,我们人为添加的噪声即是Noise_predictor中的groundTruth,该添加噪声的过程也被称为foward process。
2 Stable Diffusion
stable diffusion包括三大模块:TextEncoder、Generation Model、Decoder,三个模块独立训练,最终组合。
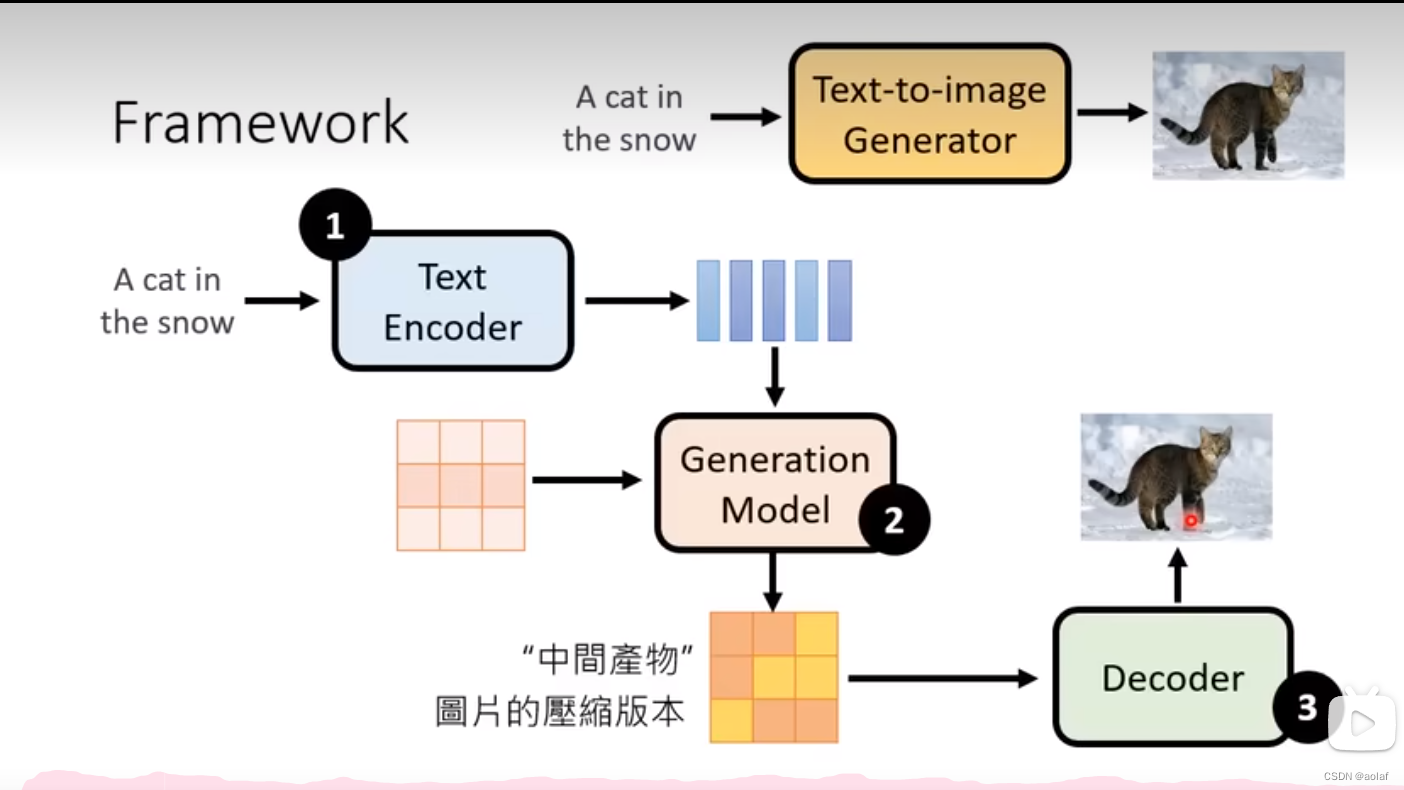
2.1 TextEncoder
TextEncoder对结果的影响很大,远大于diffusion model,增大TextEncoder模型,效果明显,而增大diffusion model模型,效果则没那么显著。
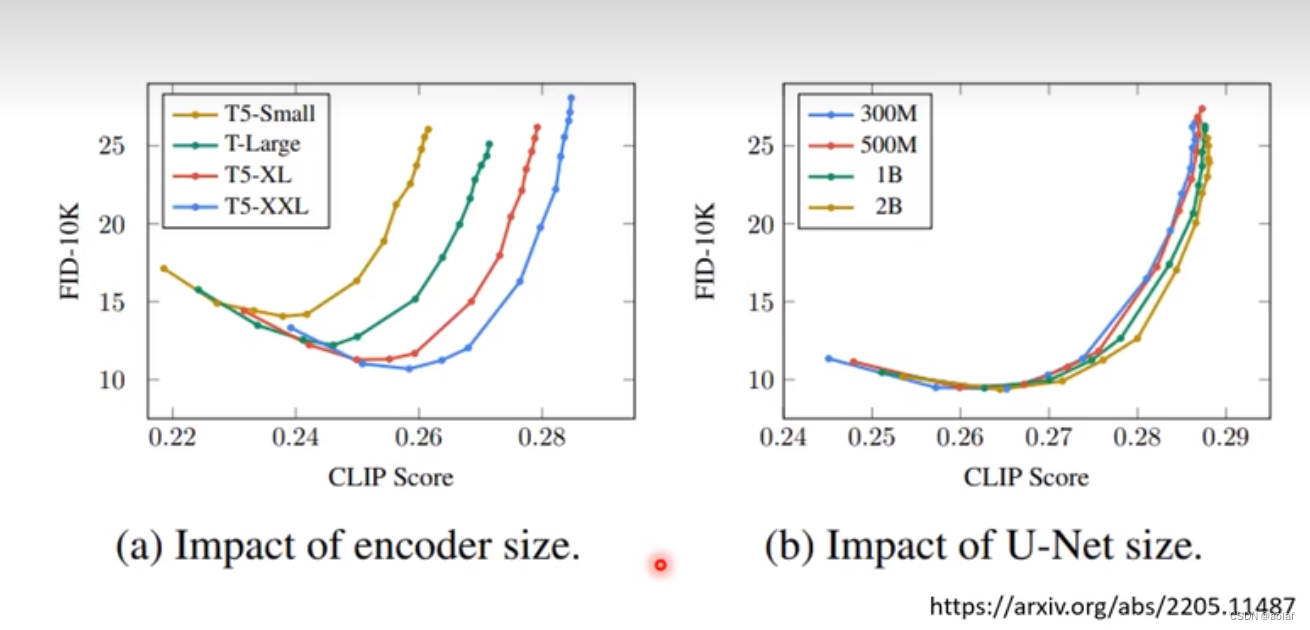
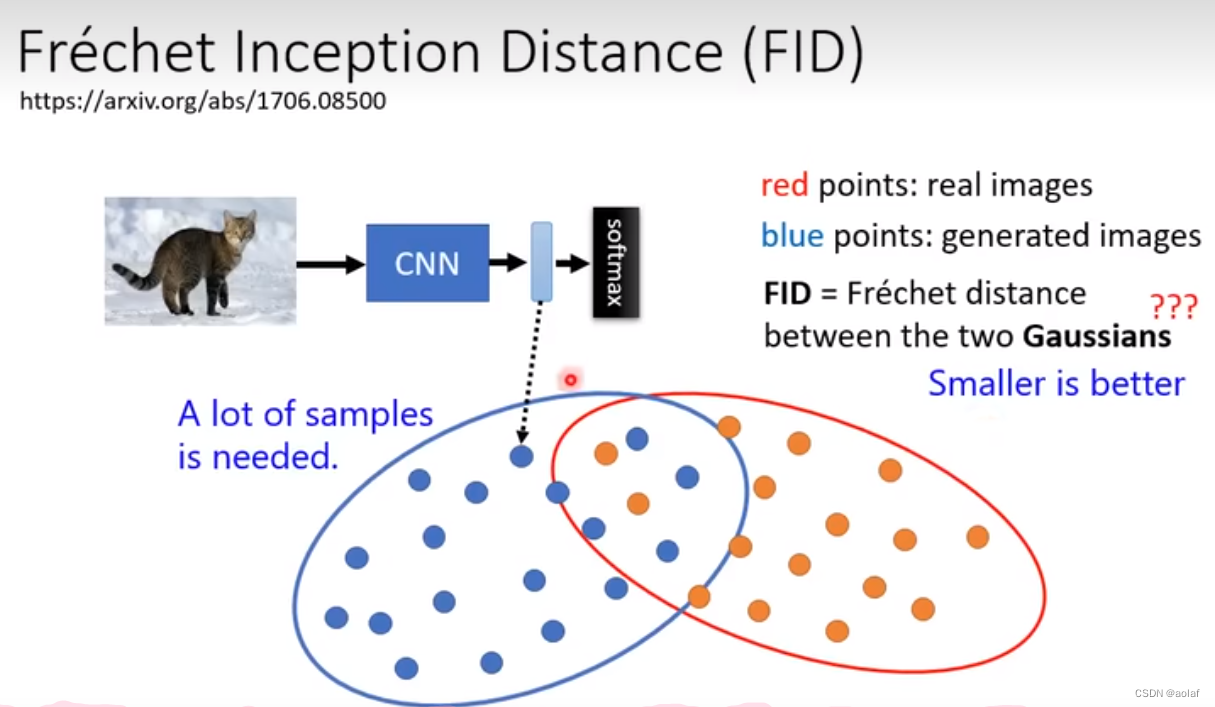
2.1.1 FID的理解
将真实图片和生成图片分别输入到一个CNN分类器,假设他们都满足高斯分布,计算他们的距离,距离越小,说明生成的图片效果越好,距离越大说明生成的图片效果越差。注意,FID的计算需要充足数量的样本。
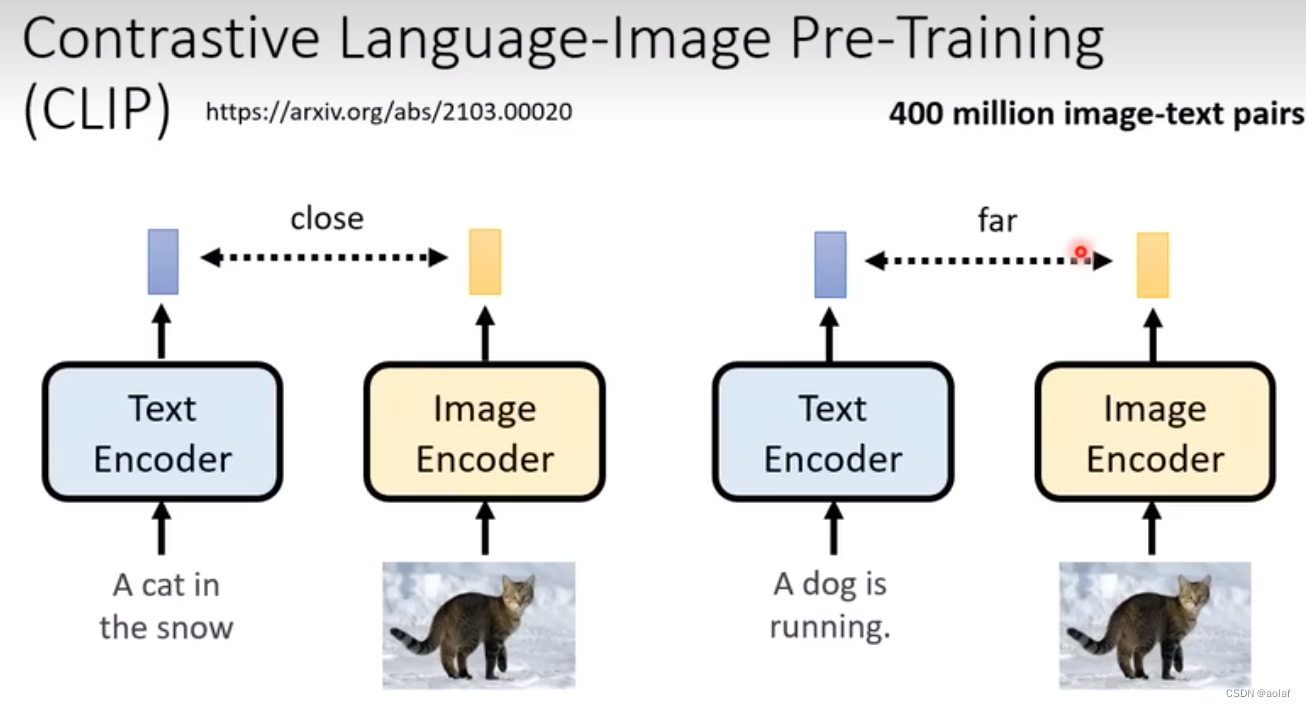
2.1.2 CLIP score的理解
clip分为TextEncoder和imageEncoder两个模块,将text输入到TextEncoder中获得的向量与将image送入到imageEncoder中获得的向量进行比较,如果输入的text和image是成对的,则结果向量越近越好,反之,越远越好。
2.2 Decoder
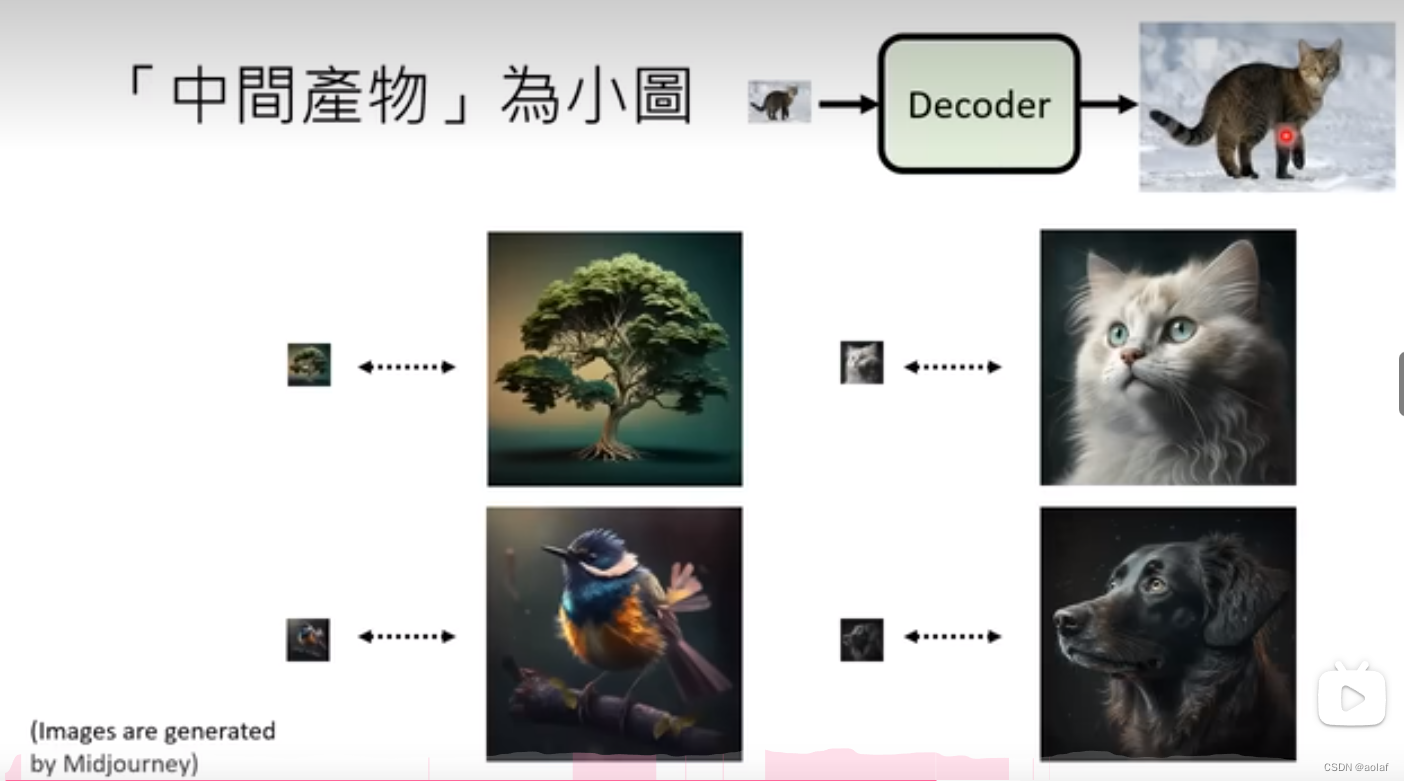
2.2.1 若中间产物为小图
直接训练一个输入为小图,输出为大图的模型。
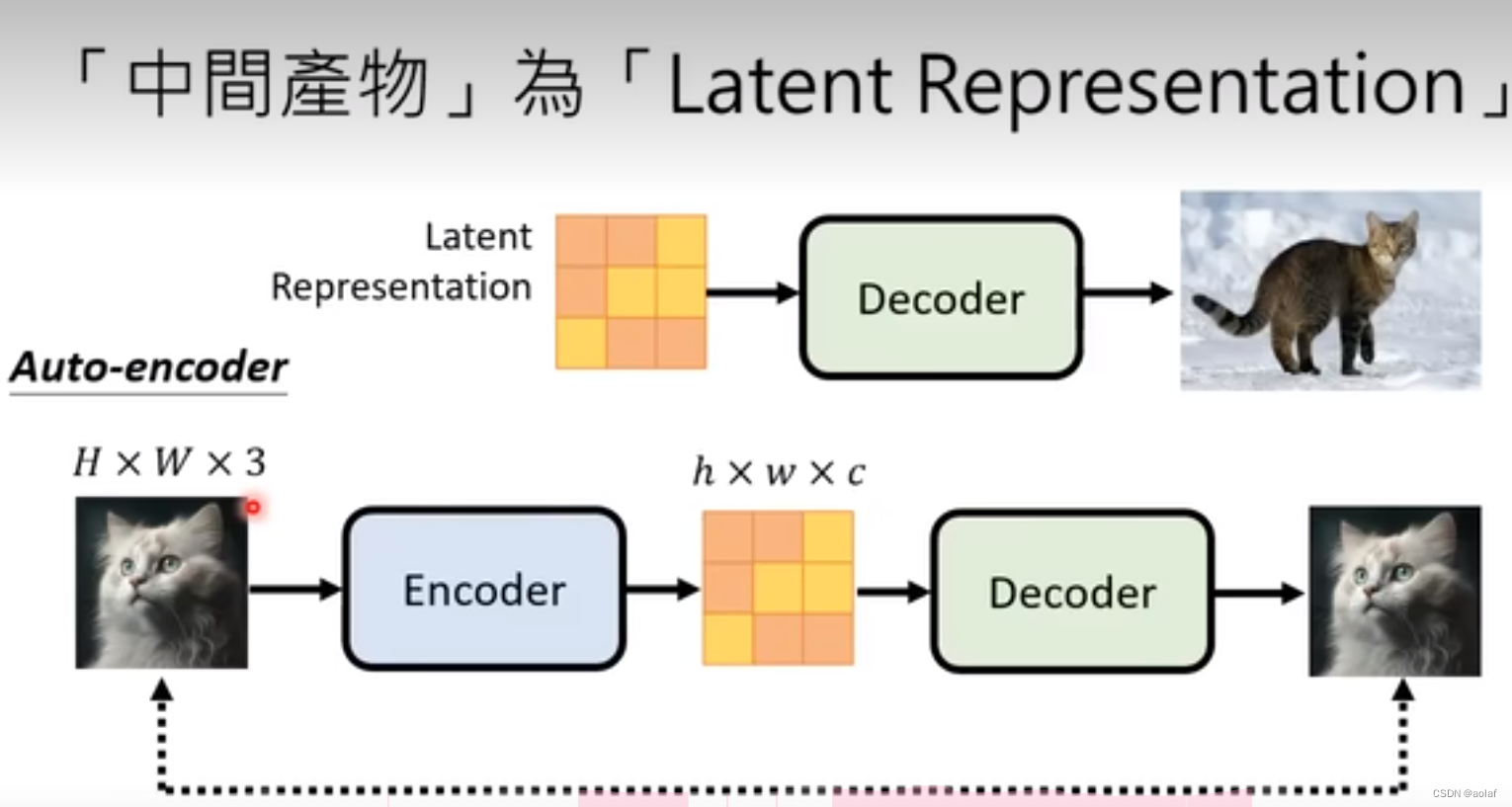
2.2.2 若中间产物为latent representation
训练一个Auto-encoder,即将输入的图像通过encoder可以获得一个latent representation,随后再经历Decoder还原成一张图,该图与原图进行对比,即完成训练流程。最终取用其中的decoder模块即可。
2.3 Generation Model
将noise加到encoder后的latent representation上,通过noise predictor预测出噪声,得到去噪后的图像
3 Diffusion Model 数学原理
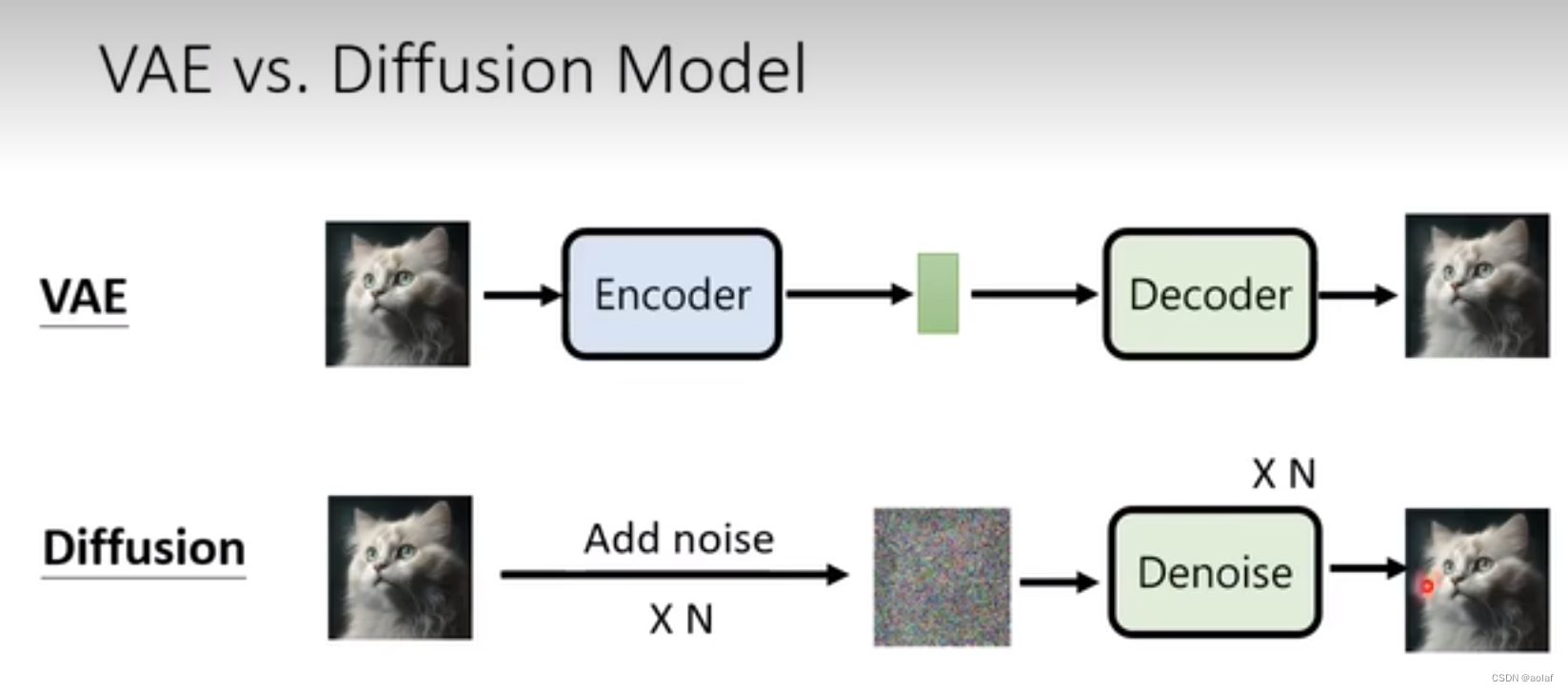
3.1 VAE与Diffusion Model区别
3.2 Diffusion Model训练过程原理:
- 随机选取一张干净的原始图像
- 初始化一个迭代次数t
- 初始化一个噪声
- 利用Noise predictor预测加噪后图片的噪声与真实噪声之间的差距,约束其越小越好


3.3 Diffusion Model推理过程原理:
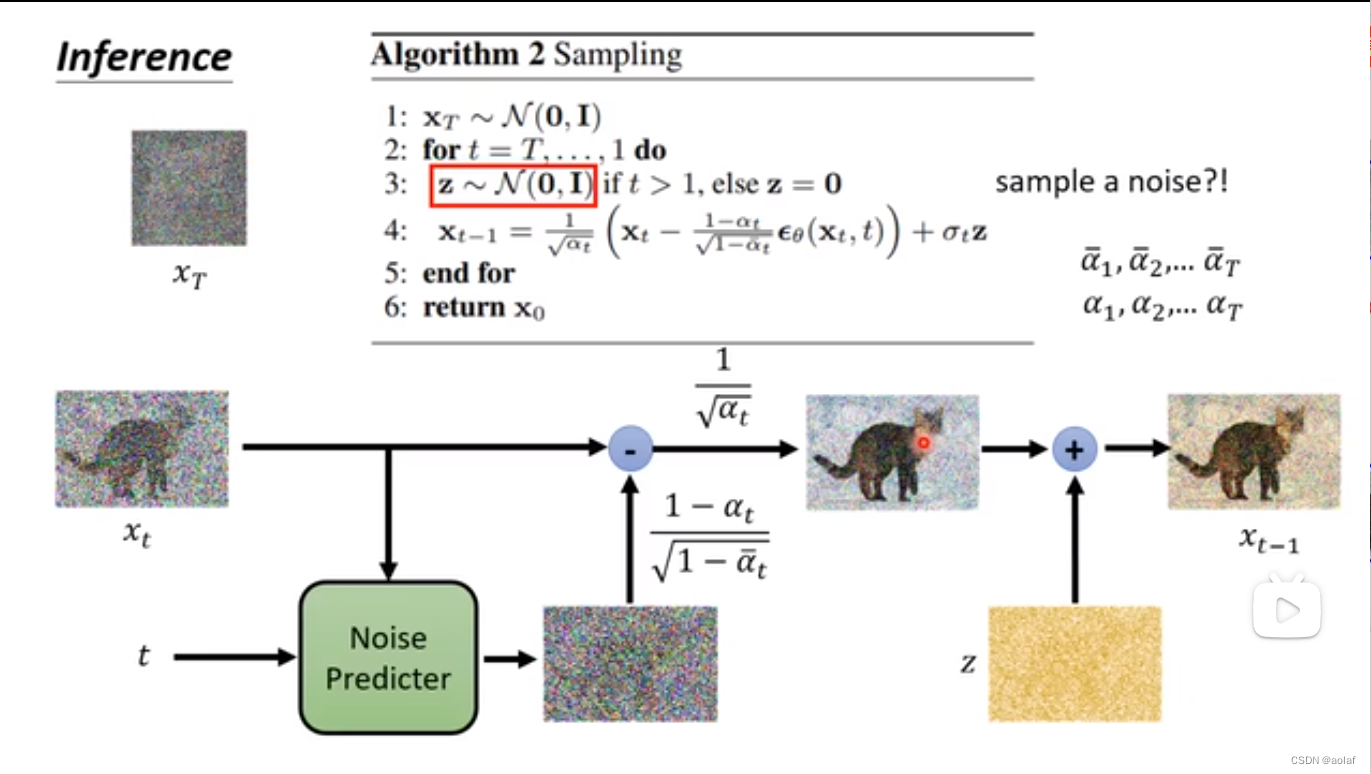
4 图像生成模型原理
4.1 Maximum Likelihood Estimation
- 在训练数据Pdata中取样x1, x2…xm
- 计算pθ产生xi(x1, x2…xm)的几率
- 找一个θ,使得pθ产生xi(x1, x2…xm)的几率相乘结果越大越好
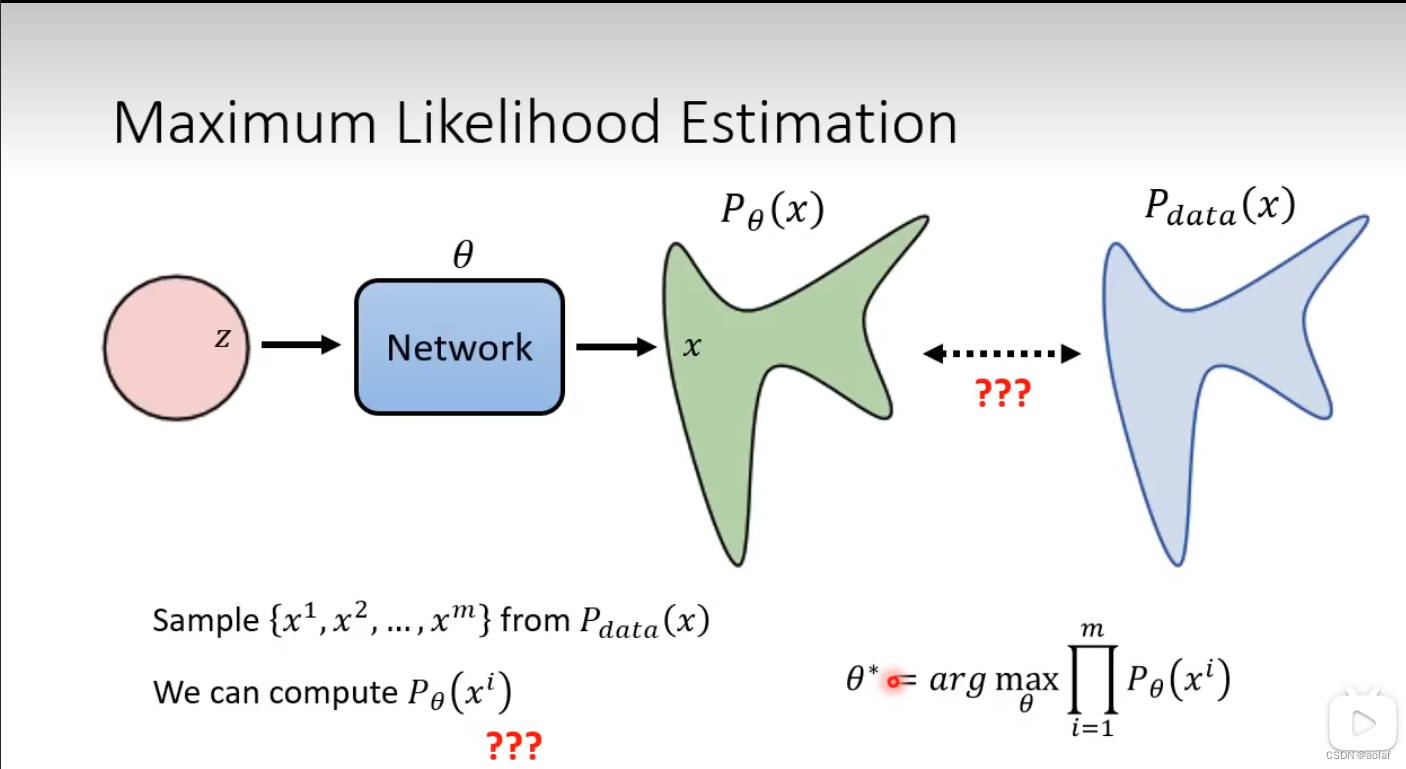
4.2 公式推导

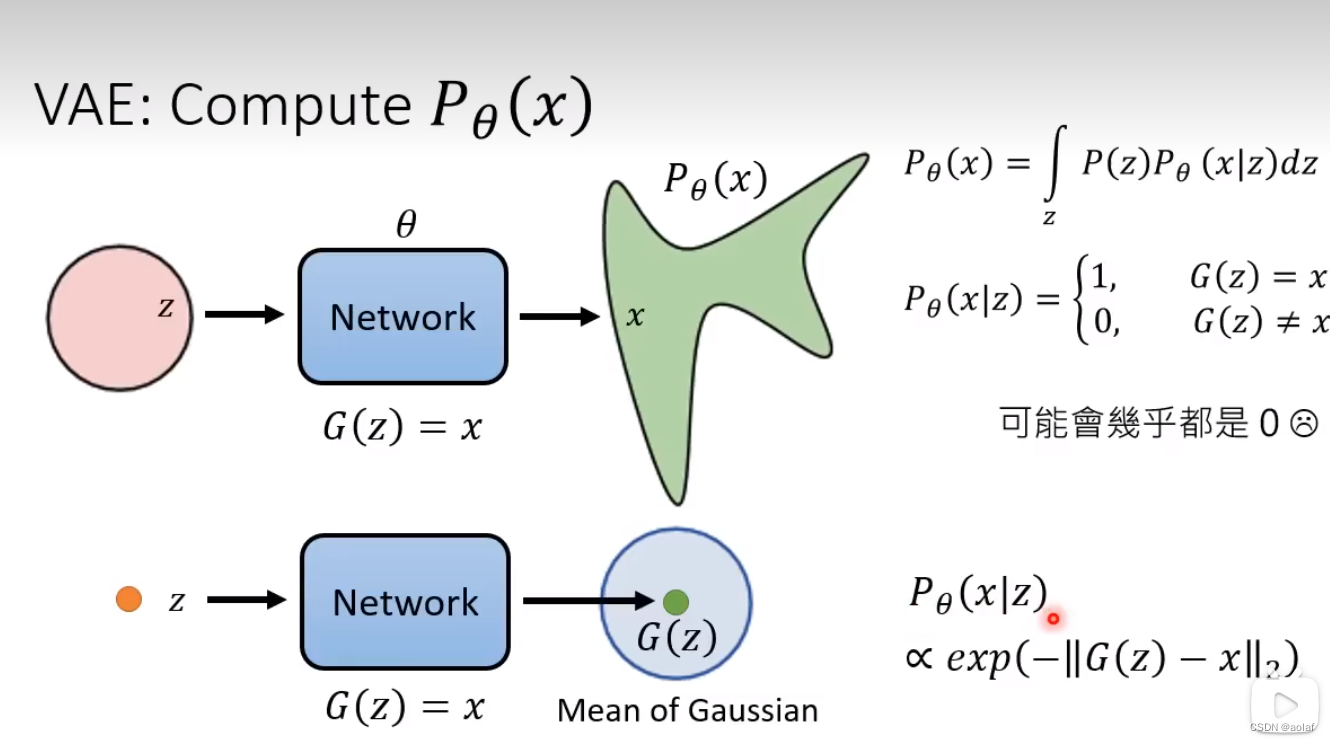
4.3 VAE计算
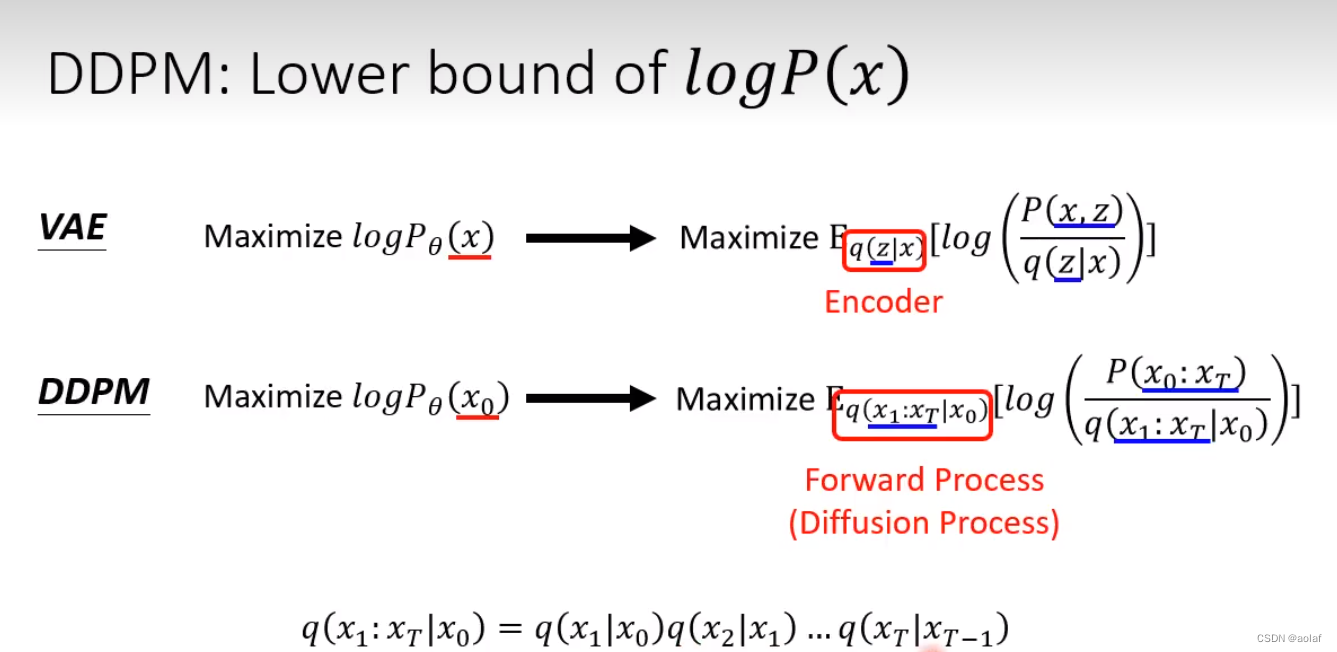
 DDPM
DDPM
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









