







用WFST来表征ASR中的模型(HCLG),可以更方便的对这些模型进行融合和优化,于是可以作为一个简单而灵活的ASR的解码器(simple and flexible ASR decoder design)。
利用WFTS,我们可以吧ctc label,lexicon(字典),language models(语言模型)等模型结合起来,生成一个简单的search graph用于解码。
WFTS主要由Composition、Determinization和Minimization这三大算法来实现。
一 Composition
Composition可以用于合并不同级别的representation,例如可以将一个pronunciation lixicon(发音字典模型,可能是由音素到声母和韵母的模型)和一个word-level grammar(例如把声母和韵母翻译成字)字级别的模型结合起来生成一个phone-to-word (直接由音素到字)的模型。效果图如下:
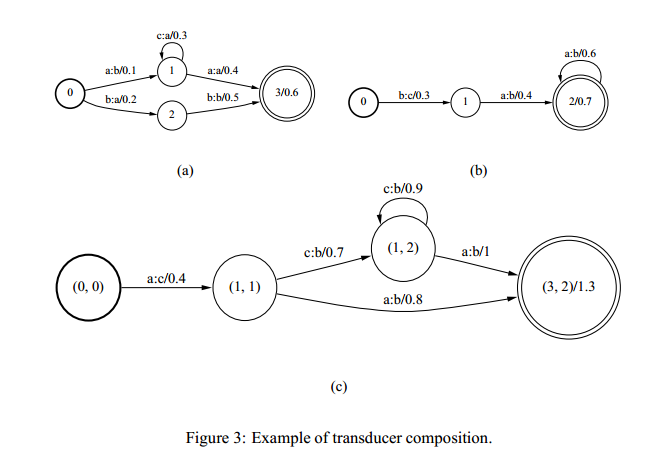
上图是将a模型和b模型结合成c模型的示意图,例如(a)模型中的第一步有俩种方式,第一种0->1,a到b的权重为0.1(表示成a:b/0.1),第二种0->2,b:a/0.2,而(b)模型中的第一步只有一种情况,即0->1,b:c/0.3,我们可以看出,能吧(a),(b)俩个模型结合起来的只有一条路径,a->b->c,即(a)模型走的那条路径为0->1,a:b/0.1,(b)模型走的那条路径为0->1,b:c/0.3,结合起来即重(0,0)->(1,1),a:c/0.4,如图c所示,(权重为什么要相加呢?这里可能是因为我们要找出一条最优路径来解码,显然结合俩个模型的代价肯定与俩个模型分别的代价的总量有关,意会就行哈哈哈~),接下来怎么走呢?到达(1,1)后代表a模型中到达1位置了,此时又有俩条路径可以走,分别为①1->1,c:a/0.3,②1->3,a:a/0.4,b此时也是在位置1,又只有一条路可以走,即1->2,a:b/0.4,我们可以发现这俩条路的标签都可以结合起来,c:a可以与a:b结合起来,a:a也可以与a:b结合起来,分别到的俩个新目的地为(1,1)->(1,2) c:b/0.3+0.4=0.7和(1,1)->(3,2) a:b/0.4+0.4(感觉可以理解成这个”音素模型”(a)我把”120125410….”这一串东西成”nihao”,然后又有一个模型(b)将”nihao”翻译成”你好”,这俩个要能连起来才可以翻译,感觉示意图在语音识别的过程中大概就是这个意思吧?)同样的,把其余位置填完就可以把a和b结合起来组成模型c。
二 Determinization
1. WFST
determinization的功能其实就是当离开某个状态的转移上的输入标签相同时,采取某种机制只保留其中的一条而不影响整个系统的结果,这样离开某个状态的转移就是确定的了,因为每输入一个标签,它都会到达唯一一个确定的状态。
找最优路径即要找权重值和最小的那一条路径,这也是为什么保留权重值小的那个标签的原因。
效果演示图如下:
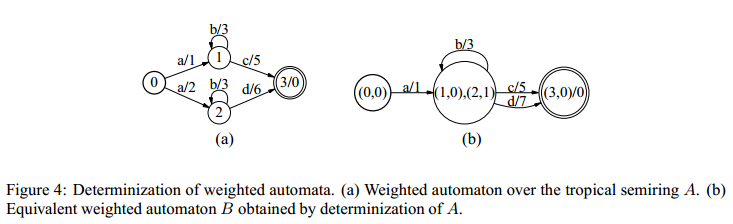
这里0->1,0->2时的转移标签都为a,我只保留那条权重值比较小的标签,即a/1,这样到达1的a标签的权重值只剩下0了,记成(1,0)保存在下个状态中,到达2的权重值还剩下a/2 - a/1 一个权重值,记作(2,1),这个剩下来的权重在后面的路径上还会加上去的,例如d/6 在图b中就变成d/7了,是把之前的那个权重加进去了,这样俩个模型中得到每个标签的代价还是一样的,不会变。
2. WFSA
WFST与前面WFSA不同的是,WFST的每个状态转移上都含有输出标签。同样的,determinzation演示图如下:
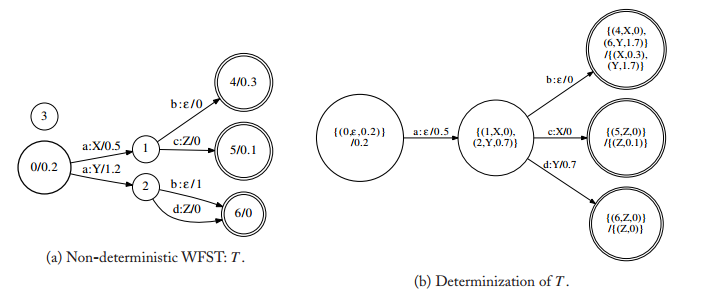
第一幅图中,a:X/0.5,a表示输入标签,X表示输出标签,第一步输入标签为a的还是有俩个a:X/0.5,a:Y/1.2,我们还是想要把他合并成一个来简化搜索路径,但是输出分别为X和Y,不一致,这里由e表示X和Y的的共同的元素,那么他们的共同输出就记作a:e/0.5,接下来到达点1的输出标签为X的权重还剩下0了,记作(1,X,0),到达点2的输出标签为Y的还剩下1.2-0.5=0.7,记作(2,Y,0.7),同样的,下一步过程中合并输入标签相同的b,即得到右图。
接着再把所有状态都renumber一下并添加一个真正的结束状态得到下图:
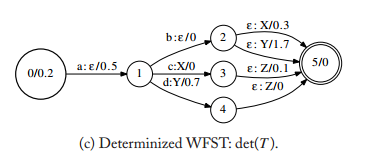
三 Minimization
3.1 权重推移(weight pushing)
在很多序列识别的问题中我们都是通过找到最小的cost来解决问题的,那么在WFST中我们同样就是通过找到最大或者最小的权重路径来解决问题的。
而pushing后权重都集中在前面可以降低整体的搜索时间因为我们会一步步的把我们不需要的路径排除掉,这样一开始就可以排除掉了很多种可能路径。
把权重推到前面,而每条路径的总权重不发生改变,效果图如下图所示:
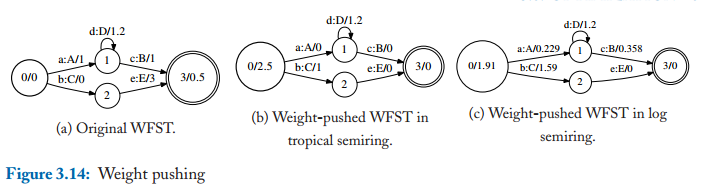
可以发现,这俩种不同的push方式在每条路径上的权重和都不变。
3.2 为了能让WFST中的状态数最小,进行Minimization效果图如下:
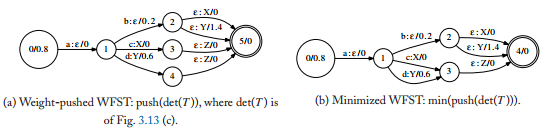
如上图,左边之前由俩个e:Z/0,我们想让状态数最小,而对应于不同的转移线,怎么把他们合并呢?即可以从后面往前面合并,把3,4俩个状态消除一个。合并后即得到右图。
四 总结
这样经过Composition合并不同的模型,从前往后Determinization合并状态数,再从后往前Minimization合并状态数来优化整个搜索图,来用于语音识别。
参考
1 http://blog.csdn.net/l_b_yuan/article/details/50958047
2 http://101.96.10.65/www.cs.nyu.edu/~mohri/pub/hbka.pdf















 70
70











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









