









目录
MGA(Multimodal Grouping Alignment )
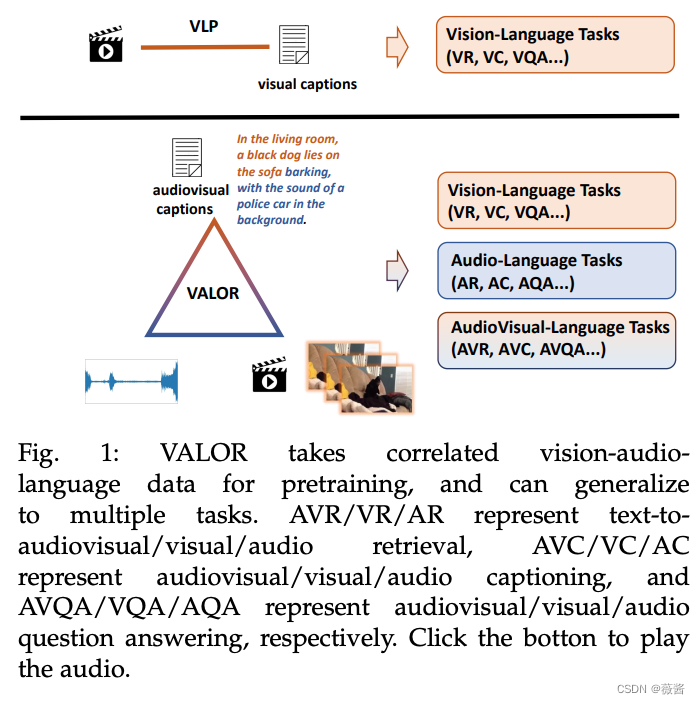
之前介绍了打通文本图像的里程碑之作-clip,今天来介绍下VALOR,使用到了视觉-语音-语言三方面的数据,并且在多个数据集上获得了sota的结果。
1.INTRODUCTION
目前,跨模态模型有了非常大的发展,但大多数集中在视觉-语言方面,包括文本到视觉检索,为图片写标题(blip),视觉问答等等。视觉-语言预训练发展迅速,但是却忽视了非常重要的声音讯号。
本文贡献:
-
提出了全视角预训练模型VALOR,视觉-音频-文本三模态的理解和生成
-
提出了MGA和MGC预训练任务,模态分组策略提升模型在不同模态输出上的泛化能力
-
提出了超大规模的人工标注的三模态数据集VALOR-1M,用以促进三模态的预训练研究,以及VALOR-32K三模态评估数据集
-
在VALOR-1M上预训练的VALOR模型取得了多个跨模态数据集sota的结果
使用三个单模态的encoder分别编码视觉/音频/语言信息。
同时提出了2个预训练任务:MGA和MGC,使得VALOR同时具备判别和生成的能力。
MGA将三模态的embedding投影到相同的语义空间,同时通过对比学习建立视觉-文本,音频-文本,视觉音频-文本三模态之间细粒度的对齐。
MGC通过视觉/音频或者视觉+音频重建被随机掩码的文本。
2.模型结构
2.1 整体框架 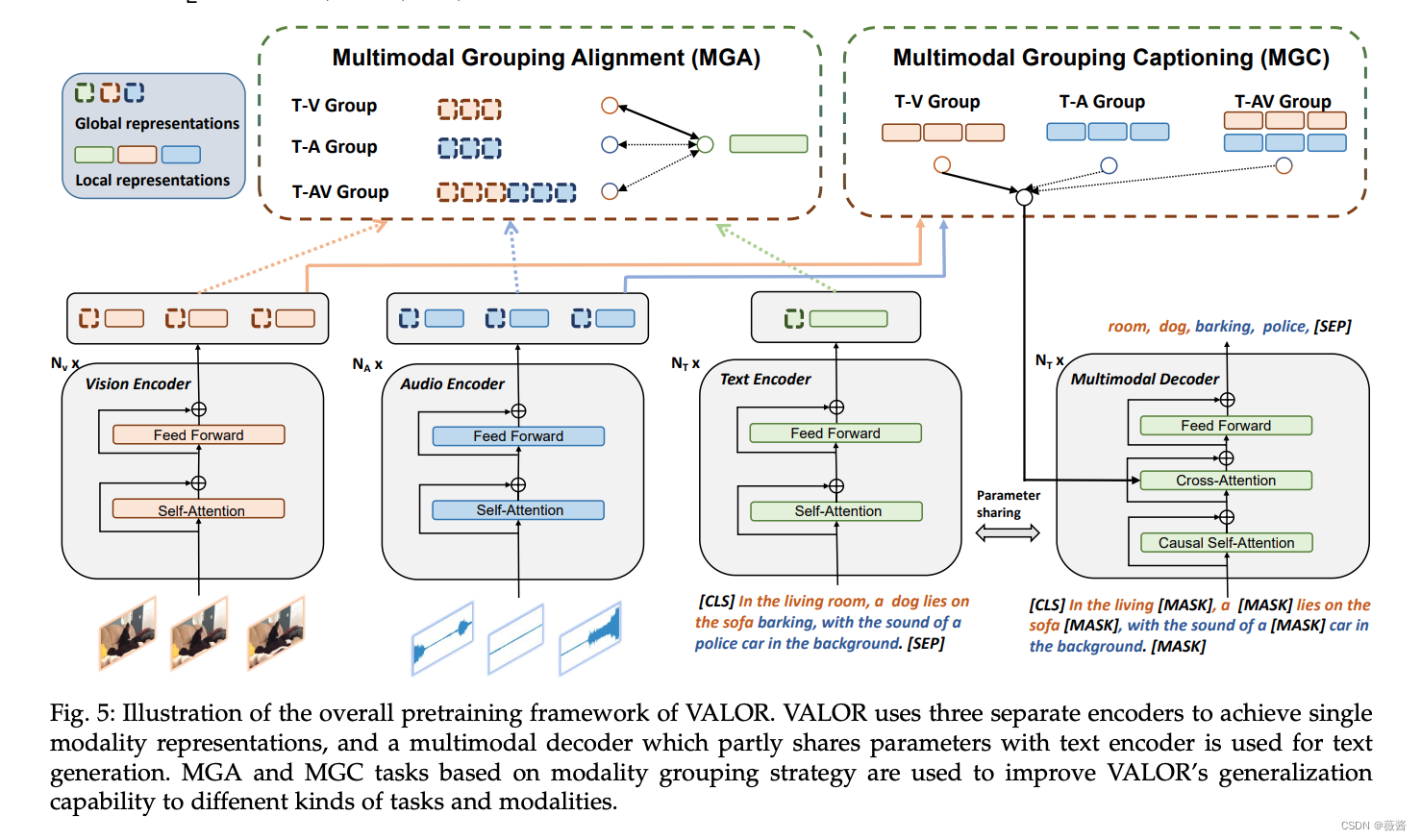
VALOR由 text encoder, vision encoder, audio encoder和一个多模态decoder构成。
三个encoder可以使用之前的预训练模型,以便加速收敛,提升效果
-
Text encoder:bert,词汇表大小:30522
-
Vision encoder:CLIP、VideoSwin,从视频中采样Nv帧图像,在clip中图像独立处理,在VideoSwin中,图片之间通过temporal window attention进行交互。
-
Audio Encoder:在AudioSet中预训练,
-
Multimodal Decoder:使用预训练的BERT模型作为解码器,通过添加交叉注意力层(cross-attention layer)来实现多模态信息的融合,和text encoder共享除了交叉注意力层外的参数。
2.2 视觉-音频-文本跨模态学习
MGA(Multimodal Grouping Alignment )
使用对比学习来进行文本和x的细粒度对齐,x可以是视觉/音频或者是两者的结合,来源于同一个片段的为正例,反之为负例,使用的是双向对比损失( Bi-directional contrastive loss )
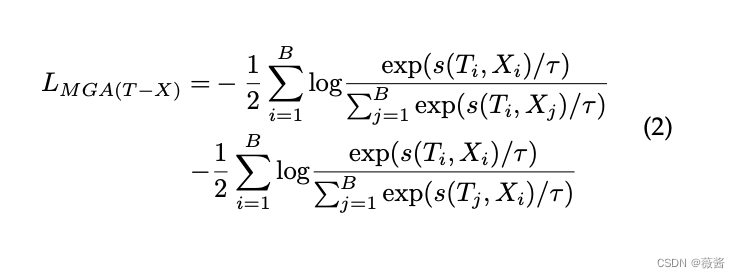 MGA中,并不是直接用文本和模态x的全局表示来进行对齐的,而是使用[CLS]或者GAP获得每帧或者每个音频片段整体的表征,然后通过三个线性投影层将三个特征投射到相同的语义空间。
MGA中,并不是直接用文本和模态x的全局表示来进行对齐的,而是使用[CLS]或者GAP获得每帧或者每个音频片段整体的表征,然后通过三个线性投影层将三个特征投射到相同的语义空间。
细粒度的相似度是et和ex点积获得ex ∈ (ev, ea, eav),整体的相似度是两个矩阵的双向相似度的加权和。权重通过学习得到, et, ev ,ea 通过线性层和softmax之后,得到每个向量对应的权重,loss公式如下
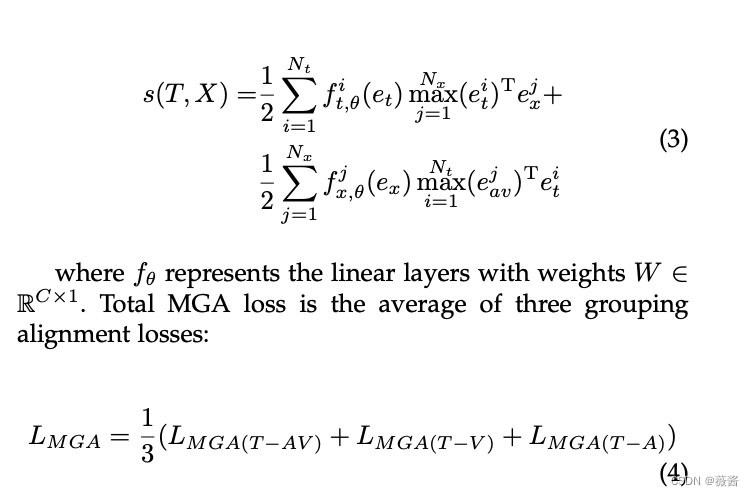
MGC
将多模态解码器的输入文本标记随机替换为[MASK]标记(60%概率),并将其输出特征向量输入到一个多层感知机(MLP)中来预测原始文本标记。这样,整个多模态解码器就可以通过MGC来学习文本的语言模型,从而提高对文本的理解和生成能力。
文本/视觉和音频特征是通过交叉注意力层进行融合的,在融合前,首先需要将音频和视频特征张量Fa和Fv在时间维度上进行压平(flatten),变成两维张量。然后,使用独立的线性层对Fa和Fv进行变换(transform),将它们转化为相同的隐藏层维度,以方便后续的数据融合。
MGC loss:
 在训练过程中,MGC和MGA同步优化,用超参数α来控制两者
在训练过程中,MGC和MGA同步优化,用超参数α来控制两者
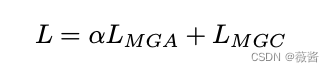
2.3 适应下游任务
-
检索任务 (AVR, VR, AR)
-
使用 LMGA(T −AV ) , LMGA(T −V ) , LMGA(T −A)作为训练目标,多模态解码器没有用到。只需要计算query和所有候选项之间的相似度排序即可。
-
-
字幕生成任务 (AVC, VC, AC)
-
使用LMGC(T −AV ) , LMGC(T −V ) , LMGC(T −A) 作为训练目标,文本自回归生成
-
-
问答任务 (AVQA, VQA, AQA)
-
使用 MGC loss作为训练目标
-
需要将问题和答案拼接起来作为解码器的输入,并且需要在答案部分进行掩码操作,以避免模型在生成答案时使用未来信息。而问题部分不需要进行掩码操作,因为问题部分的信息是所有时间步都可见的。
-
3. 相关工作
3.1 视觉-文本与训练
-
跨模态预训练框架设计
-
双encoder
-
简单点积
-
适用于跨模态检索,zero-shot分类
-
-
融合encoder
-
通过co-attention,merge-attention
-
适用于captioning或者VQA
-
-
自监督预训练
-
MLM,masked language modeling
-
MVM,masked vision modeling
-
VTM,vision-text matching
-
VTC,vision-text contrastive learning
-
-
-
统一多任务建模
-
VL-T5,使用sequence-to-sequence来建模视觉-文本任务,比如VQA,viusal grounding(视觉指代,是指在自然语言处理和计算机视觉中,将文本或语言与图像中的物体或场景进行对应的过程,即将文本或语言中的词、短语或句子与图像中的物体、位置、场景等进行匹配和对齐。)
-
对比学习
-
MLM
-
-
图文基础模型
-
Flamingo
-
GIT2
-

















 1870
1870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









